 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybridThinker: Efficient Chain-of-Thought Reasoning via Compressed Memory and Transient Thought Steps
Jun 02, 2026Extended chain-of-thought (CoT) traces improve LLM reasoning but incur substantial computational and memory costs. While existing CoT compression methods mitigate this by condensing thought steps into compact representations via memory tokens and retaining only these representations at inference time, the loss of fine-grained information makes subsequent steps more error-prone. To alleviate this, we propose \textbf{HybridThinker}, where in addition to preserved these representations, thought steps are also temporarily retained to provide fine-grained details. However, we observe that naively keeping thought steps accessible to subsequent steps \emph{during training} lets the model bypass memory tokens by retrieving information directly from these steps, leaving the model's ability to compress and retrieve information through memory tokens insufficiently trained. We therefore introduce a hybrid training scheme, in which only some thought steps are directly accessible through attention to subsequent steps, while the other thought steps are masked, forcing the model to use memory tokens for compression and retrieval. Across 4 reasoning benchmarks, HybridThinker matches the uncompressed baseline, advancing the state of the art in CoT compression by 5.8 points on average accuracy with similar inference time. Ablation studies confirm that both temporary thought-step retention and the hybrid training scheme contribute to these gains.
Teacher-Guided Policy Optimization for LLM Distillation
May 13, 2026The convergence of reinforcement learning and imitation learning has positioned Reverse KL (RKL) as a promising paradigm for on-policy LLM distillation, aiming to unify exploration with teacher supervision. However, we identify a critical limitation: when the student and teacher distributions diverge significantly, standard RKL often fails to yield meaningful improvement due to uninformative negative feedback. To address this inefficiency, we propose Teacher-Guided Policy Optimization (TGPO), an on-policy algorithm that incorporates dense directional guidance by leveraging teacher predictions conditioned on the student's rollout. Because TGPO remains on-policy, the algorithm integrates seamlessly with existing RLVR frameworks without requiring additional data annotation. Experiments on complex reasoning benchmarks demonstrate that TGPO significantly outperforms standard baselines and is robust to different teachers.
MemoSight: Unifying Context Compression and Multi Token Prediction for Reasoning Acceleration
Apr 16, 2026While Chain-of-thought (CoT) reasoning enables LLMs to solve challenging reasoning problems, as KV cache grows linearly with the number of generated tokens, CoT reasoning faces scaling issues in terms of speed and memory usage. In this work, we propose MemoSight (Memory-Foresight-based reasoning), a unified framework that integrates both context compression and multi-token prediction to mitigate the efficiency issues while maintaining CoT reasoning performance. Our framework adopts the same minimalist design for both context compression and multi-token prediction via special tokens and their corresponding position layout tailored to each token type. Comprehensive experiments on four reasoning benchmarks demonstrate that MemoSight reduces the KV cache footprint by up to 66% and accelerates inference by 1.56x, while outperforming existing CoT compression methods.
Industry-Aligned Granular Topic Modeling
Jan 16, 2026Topic modeling has extensive applications in text mining and data analysis across various industrial sectors. Although the concept of granularity holds significant value for business applications by providing deeper insights, the capability of topic modeling methods to produce granular topics has not been thoroughly explored. In this context, this paper introduces a framework called TIDE, which primarily provides a novel granular topic modeling method based on large language models (LLMs) as a core feature, along with other useful functionalities for business applications, such as summarizing long documents, topic parenting, and distillation. Through extensive experiments on a variety of public and real-world business datasets, we demonstrate that TIDE's topic modeling approach outperforms modern topic modeling methods, and our auxiliary components provide valuable support for dealing with industrial business scenarios. The TIDE framework is currently undergoing the process of being open sourced.
Automatic Labelling with Open-source LLMs using Dynamic Label Schema Integration
Jan 21, 2025Acquiring labelled training data remains a costly task in real world machine learning projects to meet quantity and quality requirements. Recently Large Language Models (LLMs), notably GPT-4, have shown great promises in labelling data with high accuracy. However, privacy and cost concerns prevent the ubiquitous use of GPT-4. In this work, we explore effectively leveraging open-source models for automatic labelling. We identify integrating label schema as a promising technology but found that naively using the label description for classification leads to poor performance on high cardinality tasks. To address this, we propose Retrieval Augmented Classification (RAC) for which LLM performs inferences for one label at a time using corresponding label schema; we start with the most related label and iterates until a label is chosen by the LLM. We show that our method, which dynamically integrates label description, leads to performance improvements in labelling tasks. We further show that by focusing only on the most promising labels, RAC can trade off between label quality and coverage - a property we leverage to automatically label our internal datasets.
Forgetting Curve: A Reliable Method for Evaluating Memorization Capability for Long-context Models
Oct 07, 2024



Numerous recent works target to extend effective context length for language models and various methods, tasks and benchmarks exist to measure model's effective memorization length. However, through thorough investigations, we find limitations for currently existing evaluations on model's memorization capability. We provide an extensive survey for limitations in this work and propose a new method called forgetting curve to measure the memorization capability of long-context models. We show that forgetting curve has the advantage of being robust to the tested corpus and the experimental settings, of not relying on prompts and can be applied to any model size. We apply our forgetting curve to a large variety of models involving both transformer and RNN/SSM based architectures. Our measurement provides empirical evidence for the effectiveness of transformer extension techniques while raises questions for the effective length of RNN/SSM based models. We also examine the difference between our measurement and existing benchmarks as well as popular metrics for various models. Our code and results can be found at https://github.com/1azybug/ForgettingCurve.
More Effective LLM Compressed Tokens with Uniformly Spread Position Identifiers and Compression Loss
Sep 22, 2024



Compressing Transformer inputs into compressd tokens allows running LLMs with improved speed and cost efficiency. Based on the compression method ICAE, we carefully examine the position identifier choices for compressed tokens and also propose a new compression loss. We demonstrate empirically that our proposed methods achieve significantly higher compression ratios (15x compared to 4x for ICAE), while being able to attain comparable reconstruction performance.
Translate-and-Revise: Boosting Large Language Models for Constrained Translation
Jul 18, 2024



Imposing constraints on machine translation systems presents a challenging issue because these systems are not trained to make use of constraints in generating adequate, fluent translations. In this paper, we leverage the capabilities of large language models (LLMs) for constrained translation, given that LLMs can easily adapt to this task by taking translation instructions and constraints as prompts. However, LLMs cannot always guarantee the adequacy of translation, and, in some cases, ignore the given constraints. This is in part because LLMs might be overly confident in their predictions, overriding the influence of the constraints. To overcome this overiding behaviour, we propose to add a revision process that encourages LLMs to correct the outputs by prompting them about the constraints that have not yet been met. We evaluate our approach on four constrained translation tasks, encompassing both lexical and structural constraints in multiple constraint domains. Experiments show 15\% improvement in constraint-based translation accuracy over standard LLMs and the approach also significantly outperforms neural machine translation (NMT) state-of-the-art methods.
Towards Robust Aspect-based Sentiment Analysis through Non-counterfactual Augmentations
Jun 24, 2023While state-of-the-art NLP models have demonstrated excellent performance for aspect based sentiment analysis (ABSA), substantial evidence has been presented on their lack of robustness. This is especially manifested as significant degradation in performance when faced with out-of-distribution data. Recent solutions that rely on counterfactually augmented datasets show promising results, but they are inherently limited because of the lack of access to explicit causal structure. In this paper, we present an alternative approach that relies on non-counterfactual data augmentation. Our proposal instead relies on using noisy, cost-efficient data augmentations that preserve semantics associated with the target aspect. Our approach then relies on modelling invariances between different versions of the data to improve robustness. A comprehensive suite of experiments shows that our proposal significantly improves upon strong pre-trained baselines on both standard and robustness-specific datasets. Our approach further establishes a new state-of-the-art on the ABSA robustness benchmark and transfers well across domains.
A call for better unit testing for invariant risk minimisation
Jun 06, 2021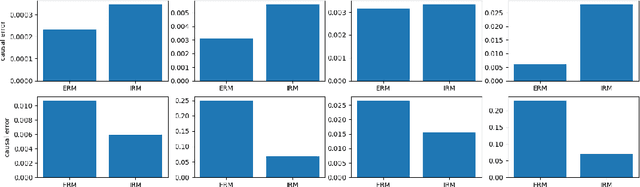
In this paper we present a controlled study on the linearized IRM framework (IRMv1) introduced in Arjovsky et al. (2020). We show that IRMv1 (and its variants) framework can be potentially unstable under small changes to the optimal regressor. This can, notably, lead to worse generalisation to new environments, even compared with ERM which converges simply to the global minimum for all training environments mixed up all together. We also highlight the isseus of scaling in the the IRMv1 setup. These observations highlight the importance of rigorous evaluation and importance of unit-testing for measuring progress towards IRM.