 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Communication in Deep Learning Recommendation Model Training with Dual-Level Adaptive Lossy Compression
Jul 05, 2024DLRM is a state-of-the-art recommendation system model that has gained widespread adoption across various industry applications. The large size of DLRM models, however, necessitates the use of multiple devices/GPUs for efficient training. A significant bottleneck in this process is the time-consuming all-to-all communication required to collect embedding data from all devices. To mitigate this, we introduce a method that employs error-bounded lossy compression to reduce the communication data size and accelerate DLRM training. We develop a novel error-bounded lossy compression algorithm, informed by an in-depth analysis of embedding data features, to achieve high compression ratios. Moreover, we introduce a dual-level adaptive strategy for error-bound adjustment, spanning both table-wise and iteration-wise aspects, to balance the compression benefits with the potential impacts on accuracy. We further optimize our compressor for PyTorch tensors on GPUs, minimizing compression overhead. Evaluation shows that our method achieves a 1.38$\times$ training speedup with a minimal accuracy impact.
Nimble GNN Embedding with Tensor-Train Decomposition
Jun 21, 2022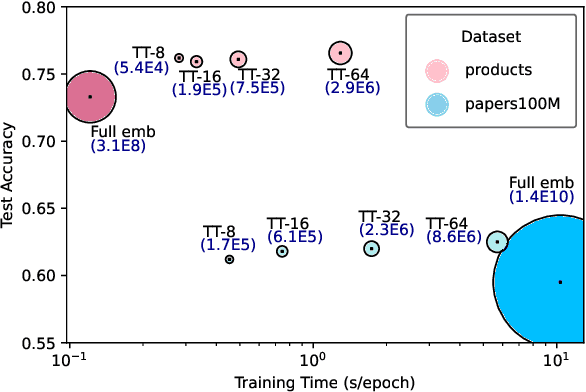

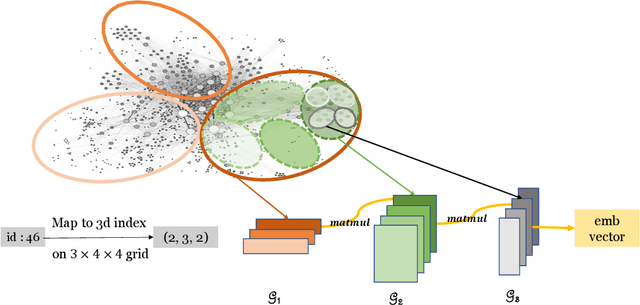
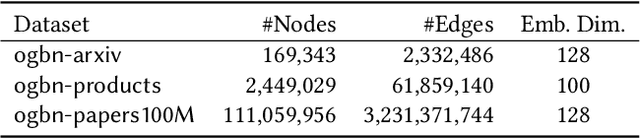
This paper describes a new method for representing embedding tables of graph neural networks (GNNs) more compactly via tensor-train (TT) decomposition. We consider the scenario where (a) the graph data that lack node features, thereby requiring the learning of embeddings during training; and (b) we wish to exploit GPU platforms, where smaller tables are needed to reduce host-to-GPU communication even for large-memory GPUs. The use of TT enables a compact parameterization of the embedding, rendering it small enough to fit entirely on modern GPUs even for massive graphs. When combined with judicious schemes for initialization and hierarchical graph partitioning, this approach can reduce the size of node embedding vectors by 1,659 times to 81,362 times on large publicly available benchmark datasets, achieving comparable or better accuracy and significant speedups on multi-GPU systems. In some cases, our model without explicit node features on input can even match the accuracy of models that use node features.
TT-Rec: Tensor Train Compression for Deep Learning Recommendation Models
Jan 25, 2021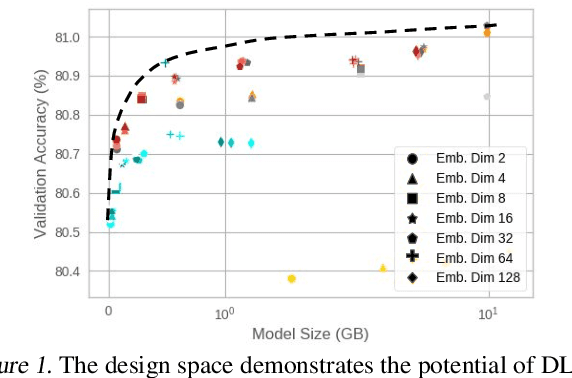
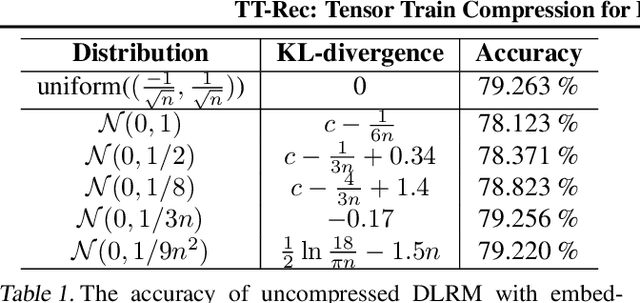
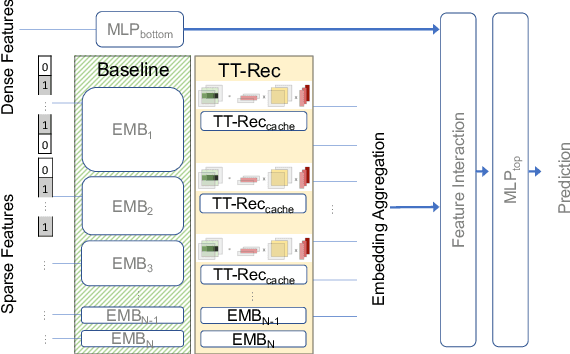
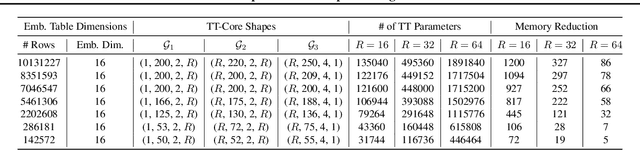
The memory capacity of embedding tables in deep learning recommendation models (DLRMs) is increasing dramatically from tens of GBs to TBs across the industry. Given the fast growth in DLRMs, novel solutions are urgently needed, in order to enable fast and efficient DLRM innovations. At the same time, this must be done without having to exponentially increase infrastructure capacity demands. In this paper, we demonstrate the promising potential of Tensor Train decomposition for DLRMs (TT-Rec), an important yet under-investigated context. We design and implement optimized kernels (TT-EmbeddingBag) to evaluate the proposed TT-Rec design. TT-EmbeddingBag is 3 times faster than the SOTA TT implementation. The performance of TT-Rec is further optimized with the batched matrix multiplication and caching strategies for embedding vector lookup operations. In addition, we present mathematically and empirically the effect of weight initialization distribution on DLRM accuracy and propose to initialize the tensor cores of TT-Rec following the sampled Gaussian distribution. We evaluate TT-Rec across three important design space dimensions -- memory capacity, accuracy, and timing performance -- by training MLPerf-DLRM with Criteo's Kaggle and Terabyte data sets. TT-Rec achieves 117 times and 112 times model size compression, for Kaggle and Terabyte, respectively. This impressive model size reduction can come with no accuracy nor training time overhead as compared to the uncompressed baseline.