 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Cosine Transform Network for Guided Depth Map Super-Resolution
Apr 14, 2021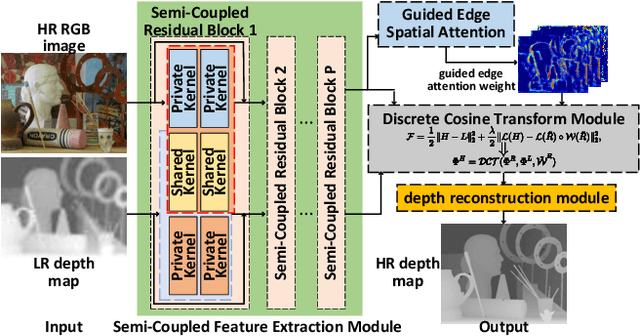
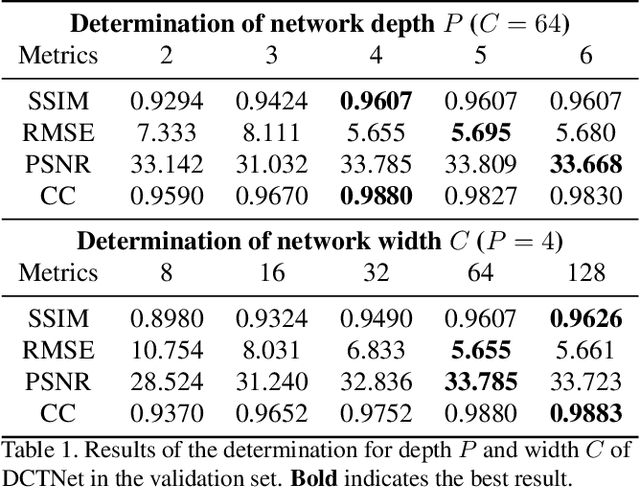
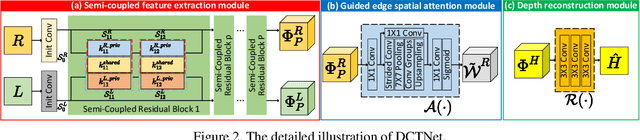
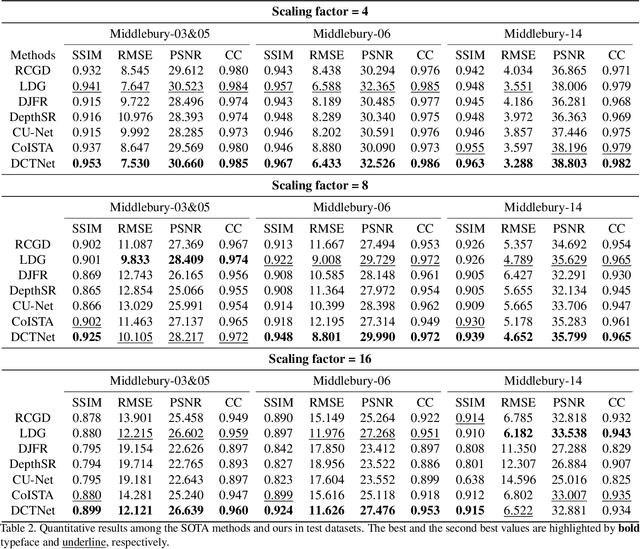
Guided depth super-resolution (GDSR) is a hot topic in multi-modal image processing. The goal is to use high-resolution (HR) RGB images to provide extra information on edges and object contours, so that low-resolution depth maps can be upsampled to HR ones. To solve the issues of RGB texture over-transferred, cross-modal feature extraction difficulty and unclear working mechanism of modules in existing methods, we propose an advanced Discrete Cosine Transform Network (DCTNet), which is composed of four components. Firstly, the paired RGB/depth images are input into the semi-coupled feature extraction module. The shared convolution kernels extract the cross-modal common features, and the private kernels extract their unique features, respectively. Then the RGB features are input into the edge attention mechanism to highlight the edges useful for upsampling. Subsequently, in the Discrete Cosine Transform (DCT) module, where DCT is employed to solve the optimization problem designed for image domain GDSR. The solution is then extended to implement the multi-channel RGB/depth features upsampling, which increases the rationality of DCTNet, and is more flexible and effective than conventional methods. The final depth prediction is output by the reconstruction module. Numerous qualitative and quantitative experiments demonstrate the effectiveness of our method, which can generate accurate and HR depth maps, surpassing state-of-the-art methods. Meanwhile, the rationality of modules is also proved by ablation experiments.
Deep Convolutional Sparse Coding Network for Pansharpening with Guidance of Side Information
Mar 10, 2021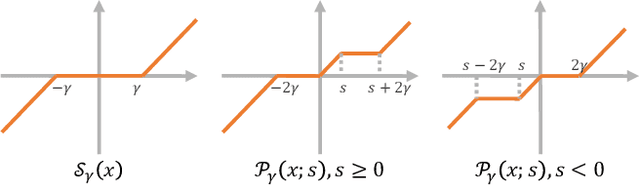
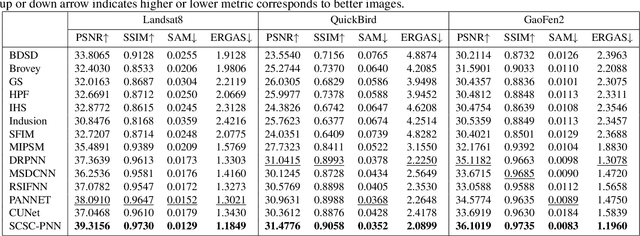
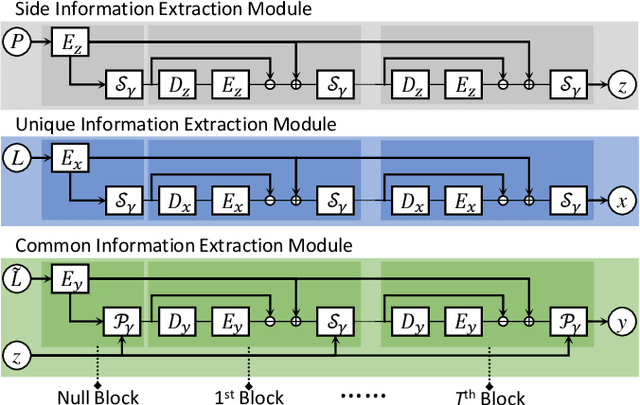
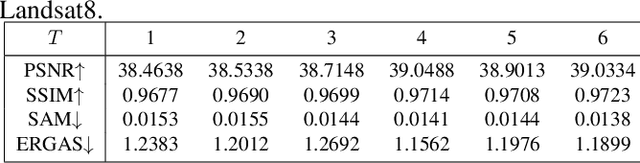
Pansharpening is a fundamental issue in remote sensing field. This paper proposes a side information partially guided convolutional sparse coding (SCSC) model for pansharpening. The key idea is to split the low resolution multispectral image into a panchromatic image related feature map and a panchromatic image irrelated feature map, where the former one is regularized by the side information from panchromatic images. With the principle of algorithm unrolling techniques, the proposed model is generalized as a deep neural network, called as SCSC pansharpening neural network (SCSC-PNN). Compared with 13 classic and state-of-the-art methods on three satellites, the numerical experiments show that SCSC-PNN is superior to others. The codes are available at https://github.com/xsxjtu/SCSC-PNN.
Deep Gradient Projection Networks for Pan-sharpening
Mar 08, 2021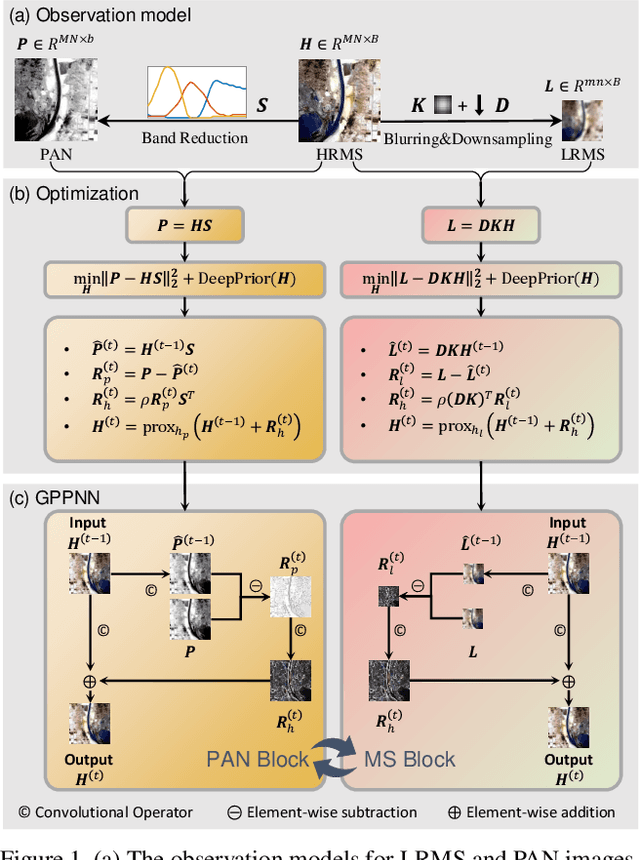
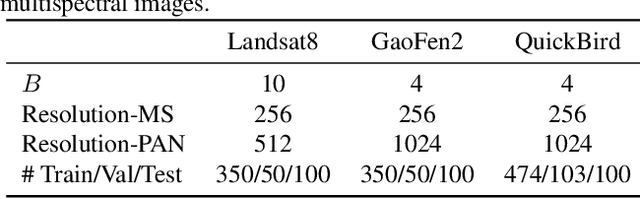
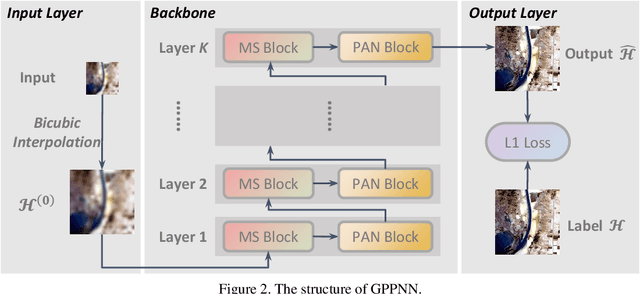
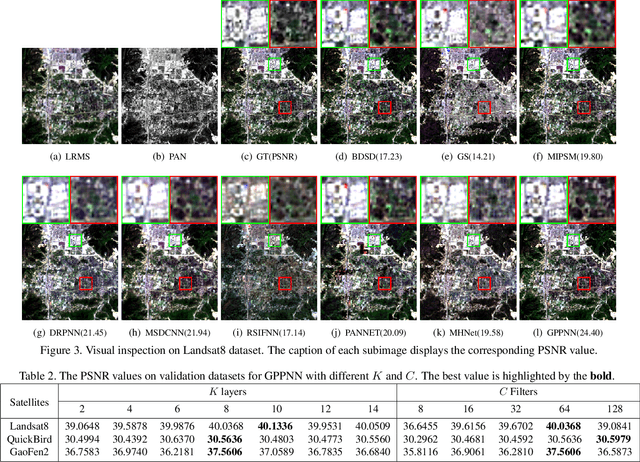
Pan-sharpening is an important technique for remote sensing imaging systems to obtain high resolution multispectral images. Recently, deep learning has become the most popular tool for pan-sharpening. This paper develops a model-based deep pan-sharpening approach. Specifically, two optimization problems regularized by the deep prior are formulated, and they are separately responsible for the generative models for panchromatic images and low resolution multispectral images. Then, the two problems are solved by a gradient projection algorithm, and the iterative steps are generalized into two network blocks. By alternatively stacking the two blocks, a novel network, called gradient projection based pan-sharpening neural network, is constructed. The experimental results on different kinds of satellite datasets demonstrate that the new network outperforms state-of-the-art methods both visually and quantitatively. The codes are available at https://github.com/xsxjtu/GPPNN.
FGF-GAN: A Lightweight Generative Adversarial Network for Pansharpening via Fast Guided Filter
Dec 31, 2020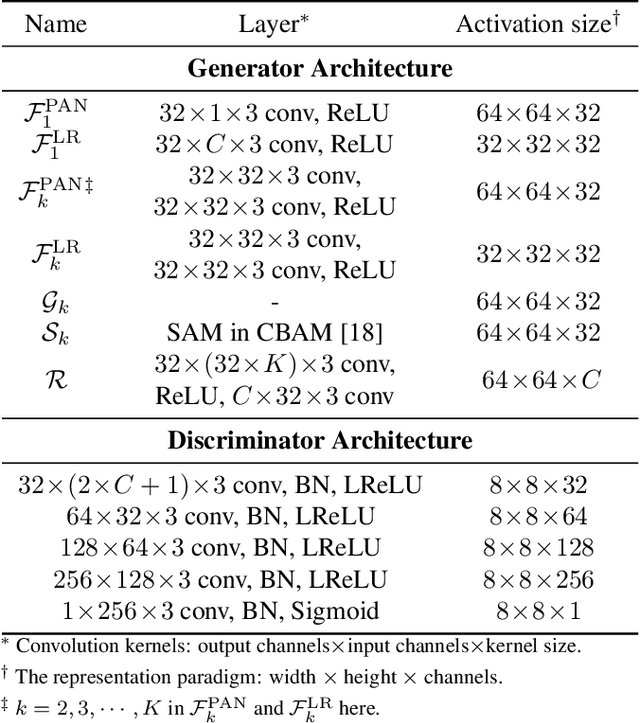
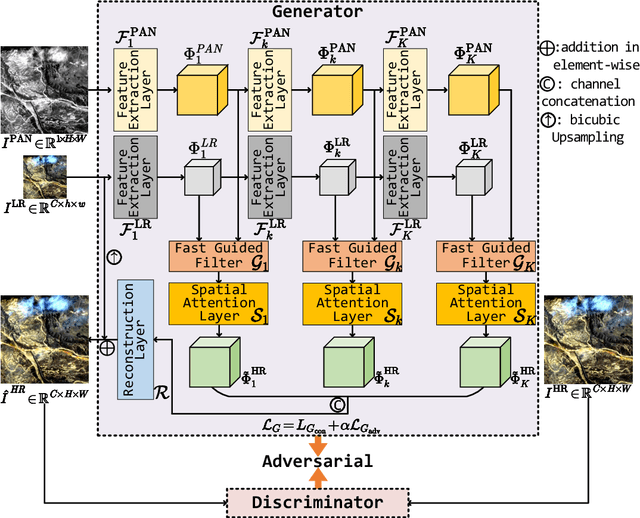

Pansharpening is a widely used image enhancement technique for remote sensing. Its principle is to fuse the input high-resolution single-channel panchromatic (PAN) image and low-resolution multi-spectral image and to obtain a high-resolution multi-spectral (HRMS) image. The existing deep learning pansharpening method has two shortcomings. First, features of two input images need to be concatenated along the channel dimension to reconstruct the HRMS image, which makes the importance of PAN images not prominent, and also leads to high computational cost. Second, the implicit information of features is difficult to extract through the manually designed loss function. To this end, we propose a generative adversarial network via the fast guided filter (FGF) for pansharpening. In generator, traditional channel concatenation is replaced by FGF to better retain the spatial information while reducing the number of parameters. Meanwhile, the fusion objects can be highlighted by the spatial attention module. In addition, the latent information of features can be preserved effectively through adversarial training. Numerous experiments illustrate that our network generates high-quality HRMS images that can surpass existing methods, and with fewer parameters.
Towards Reducing Severe Defocus Spread Effects for Multi-Focus Image Fusion via an Optimization Based Strategy
Dec 29, 2020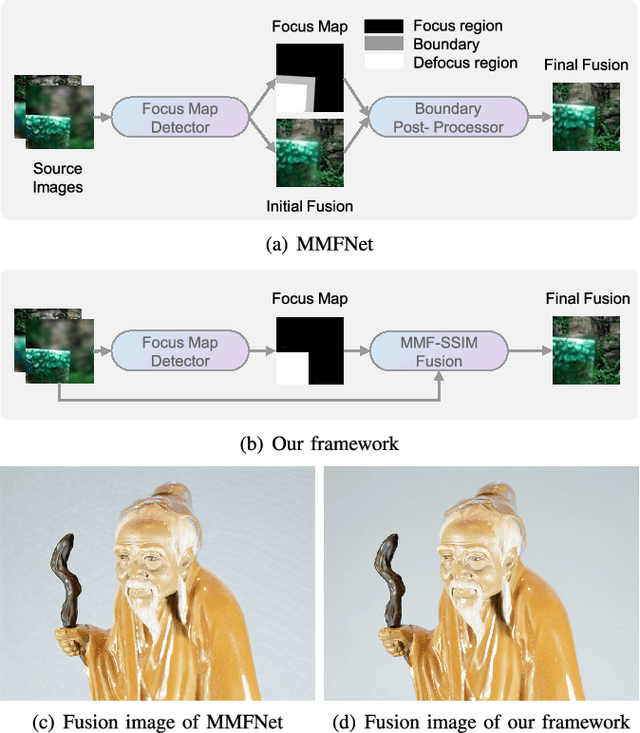
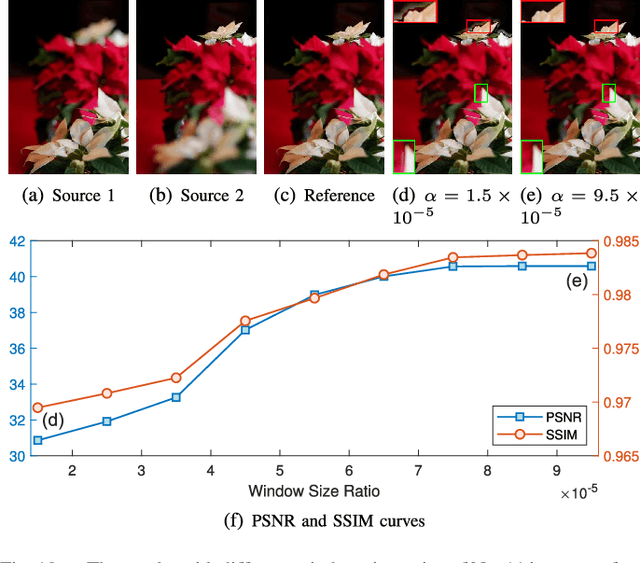


Multi-focus image fusion (MFF) is a popular technique to generate an all-in-focus image, where all objects in the scene are sharp. However, existing methods pay little attention to defocus spread effects of the real-world multi-focus images. Consequently, most of the methods perform badly in the areas near focus map boundaries. According to the idea that each local region in the fused image should be similar to the sharpest one among source images, this paper presents an optimization-based approach to reduce defocus spread effects. Firstly, a new MFF assessmentmetric is presented by combining the principle of structure similarity and detected focus maps. Then, MFF problem is cast into maximizing this metric. The optimization is solved by gradient ascent. Experiments conducted on the real-world dataset verify superiority of the proposed model. The codes are available at https://github.com/xsxjtu/MFF-SSIM.
MFIF-GAN: A New Generative Adversarial Network for Multi-Focus Image Fusion
Sep 22, 2020
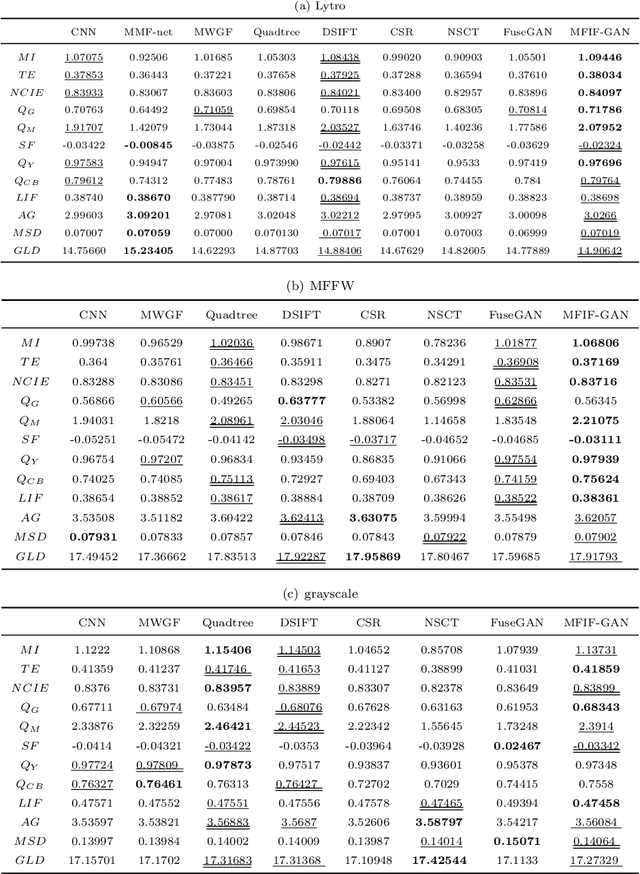

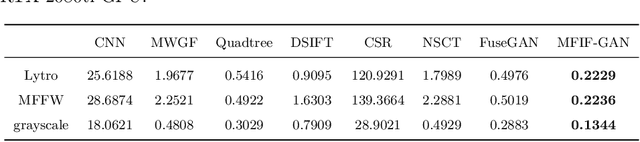
Multi-Focus Image Fusion (MFIF) is one of the promising techniques to obtain all-in-focus images to meet people's visual needs and it is a precondition of other computer vision tasks. One of the research trends of MFIF is to solve the defocus spread effect (DSE) around the focus/defocus boundary (FDB). In this paper, we present a novel generative adversarial network termed MFIF-GAN to translate multi-focus images into focus maps and to get the all-in-focus images further. The Squeeze and Excitation Residual Network (SE-ResNet) module as an attention mechanism is employed in the network. During the training, we propose reconstruction and gradient regularization loss functions to guarantee the accuracy of generated focus maps. In addition, by combining the prior knowledge of training conditon, this network is trained on a synthetic dataset with DSE based on an {\alpha}-matte model. A series of experimental results demonstrate that the MFIF-GAN is superior to several representative state-of-the-art (SOTA) algorithms in visual perception, quantitative analysis as well as efficiency.
When Image Decomposition Meets Deep Learning: A Novel Infrared and Visible Image Fusion Method
Sep 02, 2020
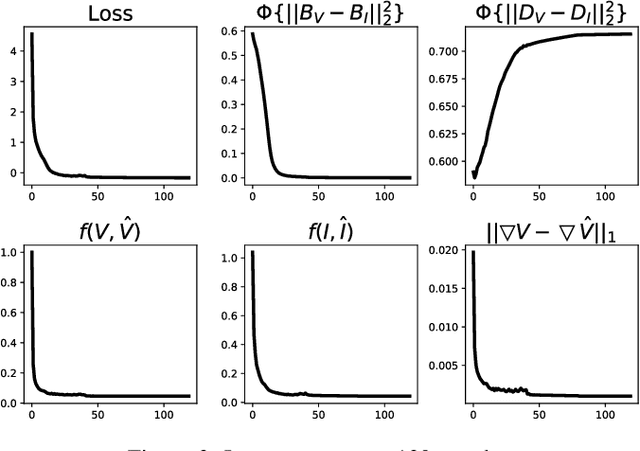


Infrared and visible image fusion, as a hot topic in image processing and image enhancement, aims to produce fused images retaining the detail texture information in visible images and the thermal radiation information in infrared images. In this paper, we propose a novel two-stream auto-encoder (AE) based fusion network. The core idea is that the encoder decomposes an image into base and detail feature maps with low- and high-frequency information, respectively, and that the decoder is responsible for the original image reconstruction. To this end, a well-designed loss function is established to make the base/detail feature maps similar/dissimilar. In the test phase, base and detail feature maps are respectively merged via a fusion module, and the fused image is recovered by the decoder. Qualitative and quantitative results demonstrate that our method can generate fusion images containing highlighted targets and abundant detail texture information with strong reproducibility and meanwhile superior than the state-of-the-art (SOTA) approaches.
Deep Convolutional Sparse Coding Networks for Image Fusion
May 18, 2020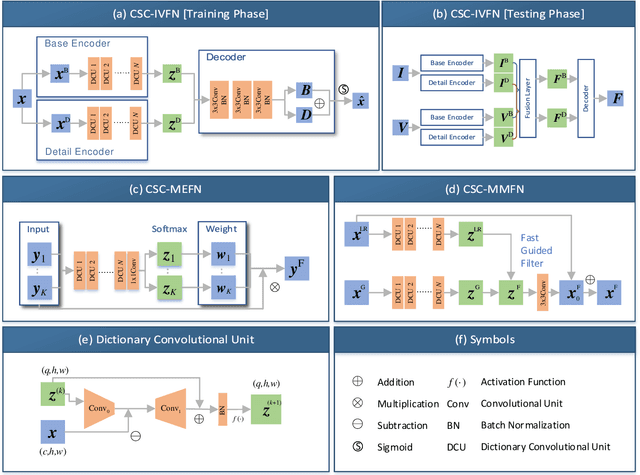


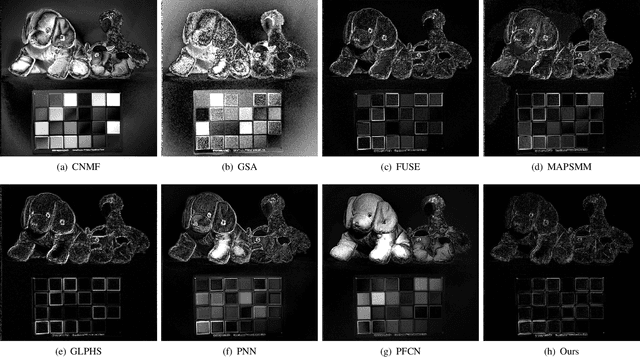
Image fusion is a significant problem in many fields including digital photography, computational imaging and remote sensing, to name but a few. Recently, deep learning has emerged as an important tool for image fusion. This paper presents three deep convolutional sparse coding (CSC) networks for three kinds of image fusion tasks (i.e., infrared and visible image fusion, multi-exposure image fusion, and multi-modal image fusion). The CSC model and the iterative shrinkage and thresholding algorithm are generalized into dictionary convolution units. As a result, all hyper-parameters are learned from data. Our extensive experiments and comprehensive comparisons reveal the superiority of the proposed networks with regard to quantitative evaluation and visual inspection.
Efficient and Interpretable Infrared and Visible Image Fusion Via Algorithm Unrolling
May 12, 2020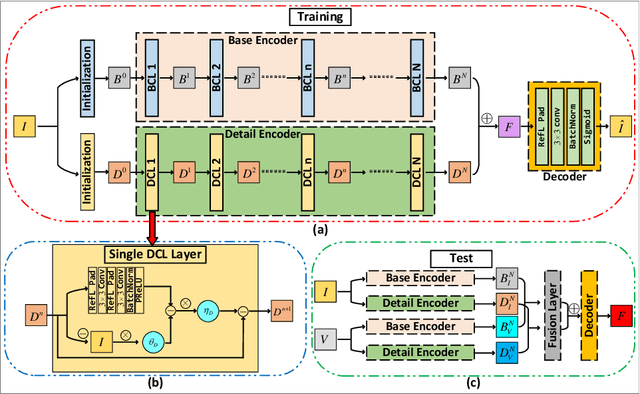
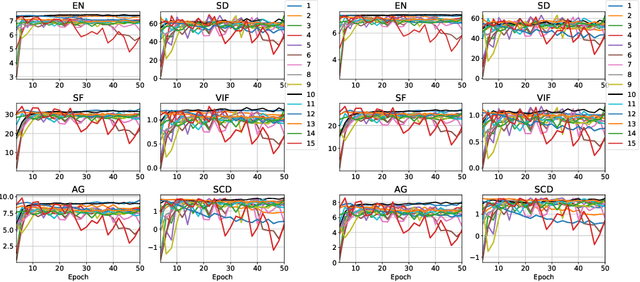
Infrared and visible image fusion expects to obtain images that highlight thermal radiation information from infrared images and texture details from visible images. In this paper, an interpretable deep network fusion model is proposed. Initially, two optimization models are established to accomplish two-scale decomposition, separating low-frequency base information and high-frequency detail information from source images. The algorithm unrolling that each iteration process is mapped to a convolutional neural network layer to transfer the optimization steps into the trainable neural networks, is implemented to solve the optimization models. In the test phase, the two decomposition feature maps of base and detail are merged respectively by the fusion layer, and then the decoder outputs the fusion image. Qualitative and quantitative comparisons demonstrate the superiority of our model, which is interpretable and can robustly generate fusion images containing highlight targets and legible details, exceeding the state-of-the-art methods.
Bayesian Fusion for Infrared and Visible Images
May 12, 2020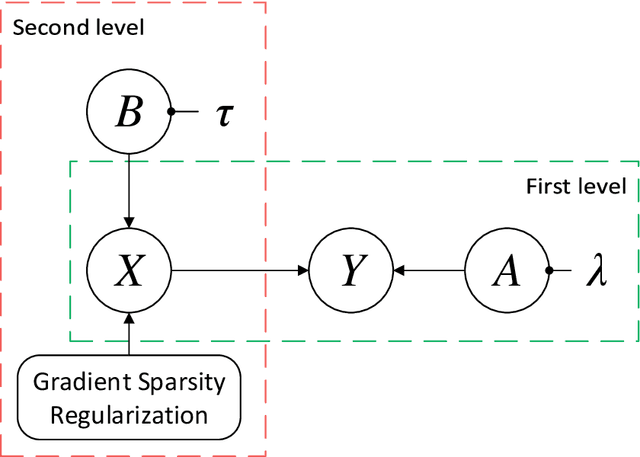
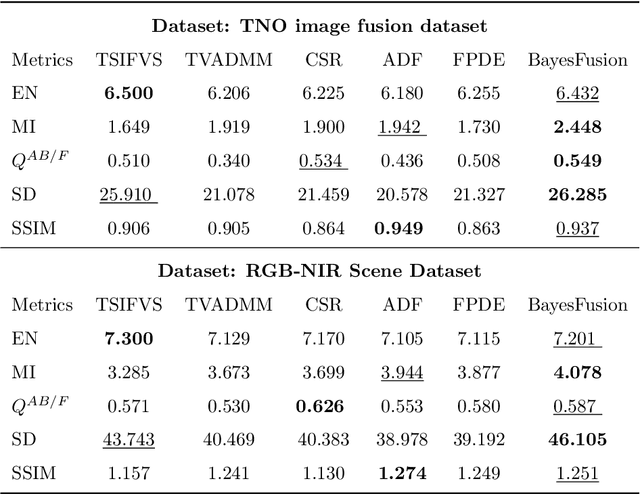

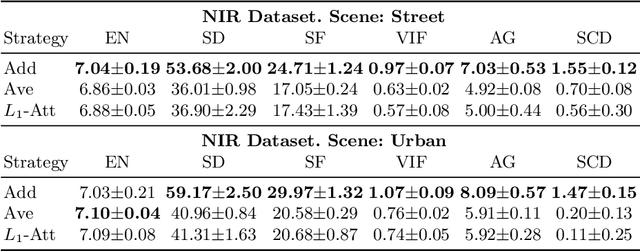
Infrared and visible image fusion has been a hot issue in image fusion. In this task, a fused image containing both the gradient and detailed texture information of visible images as well as the thermal radiation and highlighting targets of infrared images is expected to be obtained. In this paper, a novel Bayesian fusion model is established for infrared and visible images. In our model, the image fusion task is cast into a regression problem. To measure the variable uncertainty, we formulate the model in a hierarchical Bayesian manner. Aiming at making the fused image satisfy human visual system, the model incorporates the total-variation(TV) penalty. Subsequently, the model is efficiently inferred by the expectation-maximization(EM) algorithm. We test our algorithm on TNO and NIR image fusion datasets with several state-of-the-art approaches. Compared with the previous methods, the novel model can generate better fused images with high-light targets and rich texture details, which can improve the reliability of the target automatic detection and recognition system.