 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMGFFD-VLM: Multi-Granularity Prompt Learning for Face Forgery Detection with VLM
Jul 16, 2025


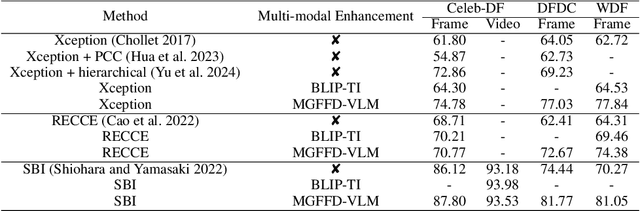
Recent studies have utilized visual large language models (VLMs) to answer not only "Is this face a forgery?" but also "Why is the face a forgery?" These studies introduced forgery-related attributes, such as forgery location and type, to construct deepfake VQA datasets and train VLMs, achieving high accuracy while providing human-understandable explanatory text descriptions. However, these methods still have limitations. For example, they do not fully leverage face quality-related attributes, which are often abnormal in forged faces, and they lack effective training strategies for forgery-aware VLMs. In this paper, we extend the VQA dataset to create DD-VQA+, which features a richer set of attributes and a more diverse range of samples. Furthermore, we introduce a novel forgery detection framework, MGFFD-VLM, which integrates an Attribute-Driven Hybrid LoRA Strategy to enhance the capabilities of Visual Large Language Models (VLMs). Additionally, our framework incorporates Multi-Granularity Prompt Learning and a Forgery-Aware Training Strategy. By transforming classification and forgery segmentation results into prompts, our method not only improves forgery classification but also enhances interpretability. To further boost detection performance, we design multiple forgery-related auxiliary losses. Experimental results demonstrate that our approach surpasses existing methods in both text-based forgery judgment and analysis, achieving superior accuracy.
Thinking Racial Bias in Fair Forgery Detection: Models, Datasets and Evaluations
Jul 19, 2024



Due to the successful development of deep image generation technology, forgery detection plays a more important role in social and economic security. Racial bias has not been explored thoroughly in the deep forgery detection field. In the paper, we first contribute a dedicated dataset called the Fair Forgery Detection (FairFD) dataset, where we prove the racial bias of public state-of-the-art (SOTA) methods. Different from existing forgery detection datasets, the self-construct FairFD dataset contains a balanced racial ratio and diverse forgery generation images with the largest-scale subjects. Additionally, we identify the problems with naive fairness metrics when benchmarking forgery detection models. To comprehensively evaluate fairness, we design novel metrics including Approach Averaged Metric and Utility Regularized Metric, which can avoid deceptive results. Extensive experiments conducted with nine representative forgery detection models demonstrate the value of the proposed dataset and the reasonability of the designed fairness metrics. We also conduct more in-depth analyses to offer more insights to inspire researchers in the community.
Federated Face Forgery Detection Learning with Personalized Representation
Jun 17, 2024Deep generator technology can produce high-quality fake videos that are indistinguishable, posing a serious social threat. Traditional forgery detection methods directly centralized training on data and lacked consideration of information sharing in non-public video data scenarios and data privacy. Naturally, the federated learning strategy can be applied for privacy protection, which aggregates model parameters of clients but not original data. However, simple federated learning can't achieve satisfactory performance because of poor generalization capabilities for the real hybrid-domain forgery dataset. To solve the problem, the paper proposes a novel federated face forgery detection learning with personalized representation. The designed Personalized Forgery Representation Learning aims to learn the personalized representation of each client to improve the detection performance of individual client models. In addition, a personalized federated learning training strategy is utilized to update the parameters of the distributed detection model. Here collaborative training is conducted on multiple distributed client devices, and shared representations of these client models are uploaded to the server side for aggregation. Experiments on several public face forgery detection datasets demonstrate the superior performance of the proposed algorithm compared with state-of-the-art methods. The code is available at \emph{https://github.com/GANG370/PFR-Forgery.}
Imperceptible Face Forgery Attack via Adversarial Semantic Mask
Jun 16, 2024



With the great development of generative model techniques, face forgery detection draws more and more attention in the related field. Researchers find that existing face forgery models are still vulnerable to adversarial examples with generated pixel perturbations in the global image. These generated adversarial samples still can't achieve satisfactory performance because of the high detectability. To address these problems, we propose an Adversarial Semantic Mask Attack framework (ASMA) which can generate adversarial examples with good transferability and invisibility. Specifically, we propose a novel adversarial semantic mask generative model, which can constrain generated perturbations in local semantic regions for good stealthiness. The designed adaptive semantic mask selection strategy can effectively leverage the class activation values of different semantic regions, and further ensure better attack transferability and stealthiness. Extensive experiments on the public face forgery dataset prove the proposed method achieves superior performance compared with several representative adversarial attack methods. The code is publicly available at https://github.com/clawerO-O/ASMA.
Semi-Supervised Learning for Anomaly Traffic Detection via Bidirectional Normalizing Flows
Mar 13, 2024



With the rapid development of the Internet, various types of anomaly traffic are threatening network security. We consider the problem of anomaly network traffic detection and propose a three-stage anomaly detection framework using only normal traffic. Our framework can generate pseudo anomaly samples without prior knowledge of anomalies to achieve the detection of anomaly data. Firstly, we employ a reconstruction method to learn the deep representation of normal samples. Secondly, these representations are normalized to a standard normal distribution using a bidirectional flow module. To simulate anomaly samples, we add noises to the normalized representations which are then passed through the generation direction of the bidirectional flow module. Finally, a simple classifier is trained to differentiate the normal samples and pseudo anomaly samples in the latent space. During inference, our framework requires only two modules to detect anomalous samples, leading to a considerable reduction in model size. According to the experiments, our method achieves the state of-the-art results on the common benchmarking datasets of anomaly network traffic detection. The code is given in the https://github.com/ZxuanDang/ATD-via-Flows.git
Masked Attribute Description Embedding for Cloth-Changing Person Re-identification
Jan 12, 2024Cloth-changing person re-identification (CC-ReID) aims to match persons who change clothes over long periods. The key challenge in CC-ReID is to extract clothing-independent features, such as face, hairstyle, body shape, and gait. Current research mainly focuses on modeling body shape using multi-modal biological features (such as silhouettes and sketches). However, it does not fully leverage the personal description information hidden in the original RGB image. Considering that there are certain attribute descriptions which remain unchanged after the changing of cloth, we propose a Masked Attribute Description Embedding (MADE) method that unifies personal visual appearance and attribute description for CC-ReID. Specifically, handling variable clothing-sensitive information, such as color and type, is challenging for effective modeling. To address this, we mask the clothing and color information in the personal attribute description extracted through an attribute detection model. The masked attribute description is then connected and embedded into Transformer blocks at various levels, fusing it with the low-level to high-level features of the image. This approach compels the model to discard clothing information. Experiments are conducted on several CC-ReID benchmarks, including PRCC, LTCC, Celeb-reID-light, and LaST. Results demonstrate that MADE effectively utilizes attribute description, enhancing cloth-changing person re-identification performance, and compares favorably with state-of-the-art methods. The code is available at https://github.com/moon-wh/MADE.
Adv-Diffusion: Imperceptible Adversarial Face Identity Attack via Latent Diffusion Model
Dec 28, 2023Adversarial attacks involve adding perturbations to the source image to cause misclassification by the target model, which demonstrates the potential of attacking face recognition models. Existing adversarial face image generation methods still can't achieve satisfactory performance because of low transferability and high detectability. In this paper, we propose a unified framework Adv-Diffusion that can generate imperceptible adversarial identity perturbations in the latent space but not the raw pixel space, which utilizes strong inpainting capabilities of the latent diffusion model to generate realistic adversarial images. Specifically, we propose the identity-sensitive conditioned diffusion generative model to generate semantic perturbations in the surroundings. The designed adaptive strength-based adversarial perturbation algorithm can ensure both attack transferability and stealthiness. Extensive qualitative and quantitative experiments on the public FFHQ and CelebA-HQ datasets prove the proposed method achieves superior performance compared with the state-of-the-art methods without an extra generative model training process. The source code is available at https://github.com/kopper-xdu/Adv-Diffusion.
Symmetrical Bidirectional Knowledge Alignment for Zero-Shot Sketch-Based Image Retrieval
Dec 16, 2023This paper studies the problem of zero-shot sketch-based image retrieval (ZS-SBIR), which aims to use sketches from unseen categories as queries to match the images of the same category. Due to the large cross-modality discrepancy, ZS-SBIR is still a challenging task and mimics realistic zero-shot scenarios. The key is to leverage transferable knowledge from the pre-trained model to improve generalizability. Existing researchers often utilize the simple fine-tuning training strategy or knowledge distillation from a teacher model with fixed parameters, lacking efficient bidirectional knowledge alignment between student and teacher models simultaneously for better generalization. In this paper, we propose a novel Symmetrical Bidirectional Knowledge Alignment for zero-shot sketch-based image retrieval (SBKA). The symmetrical bidirectional knowledge alignment learning framework is designed to effectively learn mutual rich discriminative information between teacher and student models to achieve the goal of knowledge alignment. Instead of the former one-to-one cross-modality matching in the testing stage, a one-to-many cluster cross-modality matching method is proposed to leverage the inherent relationship of intra-class images to reduce the adverse effects of the existing modality gap. Experiments on several representative ZS-SBIR datasets (Sketchy Ext dataset, TU-Berlin Ext dataset and QuickDraw Ext dataset) prove the proposed algorithm can achieve superior performance compared with state-of-the-art methods.
DeepFidelity: Perceptual Forgery Fidelity Assessment for Deepfake Detection
Dec 07, 2023Deepfake detection refers to detecting artificially generated or edited faces in images or videos, which plays an essential role in visual information security. Despite promising progress in recent years, Deepfake detection remains a challenging problem due to the complexity and variability of face forgery techniques. Existing Deepfake detection methods are often devoted to extracting features by designing sophisticated networks but ignore the influence of perceptual quality of faces. Considering the complexity of the quality distribution of both real and fake faces, we propose a novel Deepfake detection framework named DeepFidelity to adaptively distinguish real and fake faces with varying image quality by mining the perceptual forgery fidelity of face images. Specifically, we improve the model's ability to identify complex samples by mapping real and fake face data of different qualities to different scores to distinguish them in a more detailed way. In addition, we propose a network structure called Symmetric Spatial Attention Augmentation based vision Transformer (SSAAFormer), which uses the symmetry of face images to promote the network to model the geographic long-distance relationship at the shallow level and augment local features. Extensive experiments on multiple benchmark datasets demonstrate the superiority of the proposed method over state-of-the-art methods.
GazeForensics: DeepFake Detection via Gaze-guided Spatial Inconsistency Learning
Nov 22, 2023



DeepFake detection is pivotal in personal privacy and public safety. With the iterative advancement of DeepFake techniques, high-quality forged videos and images are becoming increasingly deceptive. Prior research has seen numerous attempts by scholars to incorporate biometric features into the field of DeepFake detection. However, traditional biometric-based approaches tend to segregate biometric features from general ones and freeze the biometric feature extractor. These approaches resulted in the exclusion of valuable general features, potentially leading to a performance decline and, consequently, a failure to fully exploit the potential of biometric information in assisting DeepFake detection. Moreover, insufficient attention has been dedicated to scrutinizing gaze authenticity within the realm of DeepFake detection in recent years. In this paper, we introduce GazeForensics, an innovative DeepFake detection method that utilizes gaze representation obtained from a 3D gaze estimation model to regularize the corresponding representation within our DeepFake detection model, while concurrently integrating general features to further enhance the performance of our model. Experiment results reveal that our proposed GazeForensics outperforms the current state-of-the-art methods.