 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMGFFD-VLM: Multi-Granularity Prompt Learning for Face Forgery Detection with VLM
Paper and Code
Jul 16, 2025


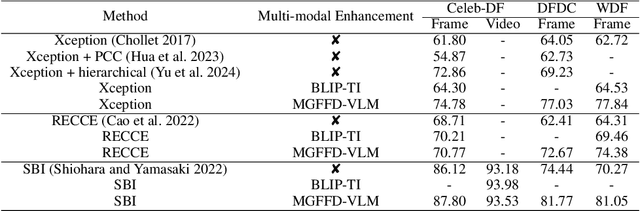
Recent studies have utilized visual large language models (VLMs) to answer not only "Is this face a forgery?" but also "Why is the face a forgery?" These studies introduced forgery-related attributes, such as forgery location and type, to construct deepfake VQA datasets and train VLMs, achieving high accuracy while providing human-understandable explanatory text descriptions. However, these methods still have limitations. For example, they do not fully leverage face quality-related attributes, which are often abnormal in forged faces, and they lack effective training strategies for forgery-aware VLMs. In this paper, we extend the VQA dataset to create DD-VQA+, which features a richer set of attributes and a more diverse range of samples. Furthermore, we introduce a novel forgery detection framework, MGFFD-VLM, which integrates an Attribute-Driven Hybrid LoRA Strategy to enhance the capabilities of Visual Large Language Models (VLMs). Additionally, our framework incorporates Multi-Granularity Prompt Learning and a Forgery-Aware Training Strategy. By transforming classification and forgery segmentation results into prompts, our method not only improves forgery classification but also enhances interpretability. To further boost detection performance, we design multiple forgery-related auxiliary losses. Experimental results demonstrate that our approach surpasses existing methods in both text-based forgery judgment and analysis, achieving superior accuracy.