 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint graph entropy knowledge distillation for point cloud classification and robustness against corruptions
Sep 26, 2025



Classification tasks in 3D point clouds often assume that class events \replaced{are }{follow }independent and identically distributed (IID), although this assumption destroys the correlation between classes. This \replaced{study }{paper }proposes a classification strategy, \textbf{J}oint \textbf{G}raph \textbf{E}ntropy \textbf{K}nowledge \textbf{D}istillation (JGEKD), suitable for non-independent and identically distributed 3D point cloud data, \replaced{which }{the strategy } achieves knowledge transfer of class correlations through knowledge distillation by constructing a loss function based on joint graph entropy. First\deleted{ly}, we employ joint graphs to capture add{the }hidden relationships between classes\replaced{ and}{,} implement knowledge distillation to train our model by calculating the entropy of add{add }graph.\replaced{ Subsequently}{ Then}, to handle 3D point clouds \deleted{that is }invariant to spatial transformations, we construct \replaced{S}{s}iamese structures and develop two frameworks, self-knowledge distillation and teacher-knowledge distillation, to facilitate information transfer between different transformation forms of the same data. \replaced{In addition}{ Additionally}, we use the above framework to achieve knowledge transfer between point clouds and their corrupted forms, and increase the robustness against corruption of model. Extensive experiments on ScanObject, ModelNet40, ScanntV2\_cls and ModelNet-C demonstrate that the proposed strategy can achieve competitive results.
MAML MOT: Multiple Object Tracking based on Meta-Learning
May 12, 2024



With the advancement of video analysis technology, the multi-object tracking (MOT) problem in complex scenes involving pedestrians is gaining increasing importance. This challenge primarily involves two key tasks: pedestrian detection and re-identification. While significant progress has been achieved in pedestrian detection tasks in recent years, enhancing the effectiveness of re-identification tasks remains a persistent challenge. This difficulty arises from the large total number of pedestrian samples in multi-object tracking datasets and the scarcity of individual instance samples. Motivated by recent rapid advancements in meta-learning techniques, we introduce MAML MOT, a meta-learning-based training approach for multi-object tracking. This approach leverages the rapid learning capability of meta-learning to tackle the issue of sample scarcity in pedestrian re-identification tasks, aiming to improve the model's generalization performance and robustness. Experimental results demonstrate that the proposed method achieves high accuracy on mainstream datasets in the MOT Challenge. This offers new perspectives and solutions for research in the field of pedestrian multi-object tracking.
Algorithm and Hardware Co-Design of Energy-Efficient LSTM Networks for Video Recognition with Hierarchical Tucker Tensor Decomposition
Dec 05, 2022



Long short-term memory (LSTM) is a type of powerful deep neural network that has been widely used in many sequence analysis and modeling applications. However, the large model size problem of LSTM networks make their practical deployment still very challenging, especially for the video recognition tasks that require high-dimensional input data. Aiming to overcome this limitation and fully unlock the potentials of LSTM models, in this paper we propose to perform algorithm and hardware co-design towards high-performance energy-efficient LSTM networks. At algorithm level, we propose to develop fully decomposed hierarchical Tucker (FDHT) structure-based LSTM, namely FDHT-LSTM, which enjoys ultra-low model complexity while still achieving high accuracy. In order to fully reap such attractive algorithmic benefit, we further develop the corresponding customized hardware architecture to support the efficient execution of the proposed FDHT-LSTM model. With the delicate design of memory access scheme, the complicated matrix transformation can be efficiently supported by the underlying hardware without any access conflict in an on-the-fly way. Our evaluation results show that both the proposed ultra-compact FDHT-LSTM models and the corresponding hardware accelerator achieve very high performance. Compared with the state-of-the-art compressed LSTM models, FDHT-LSTM enjoys both order-of-magnitude reduction in model size and significant accuracy improvement across different video recognition datasets. Meanwhile, compared with the state-of-the-art tensor decomposed model-oriented hardware TIE, our proposed FDHT-LSTM architecture achieves better performance in throughput, area efficiency and energy efficiency, respectively on LSTM-Youtube workload. For LSTM-UCF workload, our proposed design also outperforms TIE with higher throughput, higher energy efficiency and comparable area efficiency.
Doubly Residual Neural Decoder: Towards Low-Complexity High-Performance Channel Decoding
Feb 08, 2021
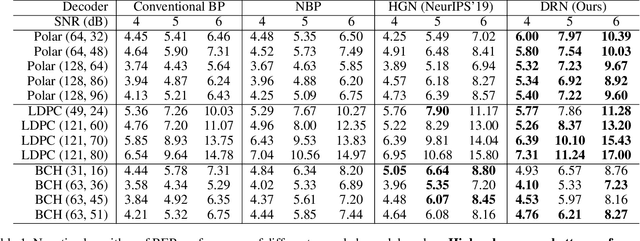
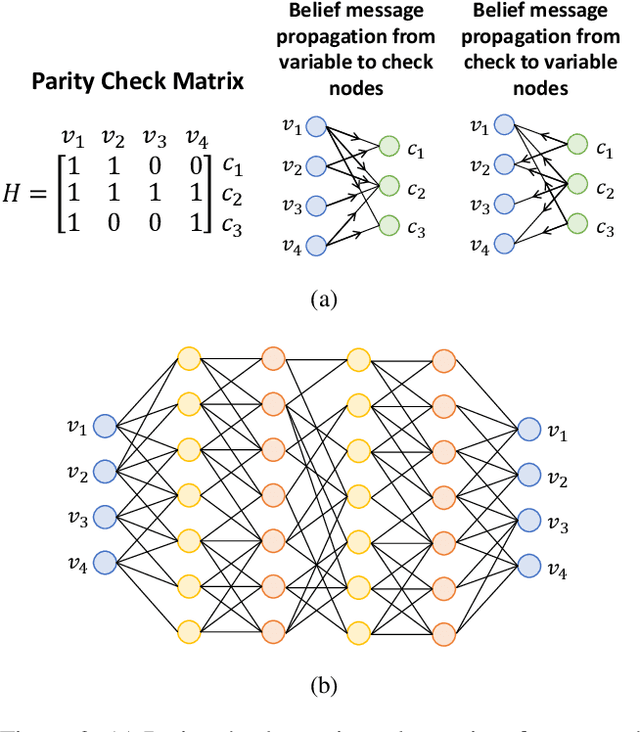
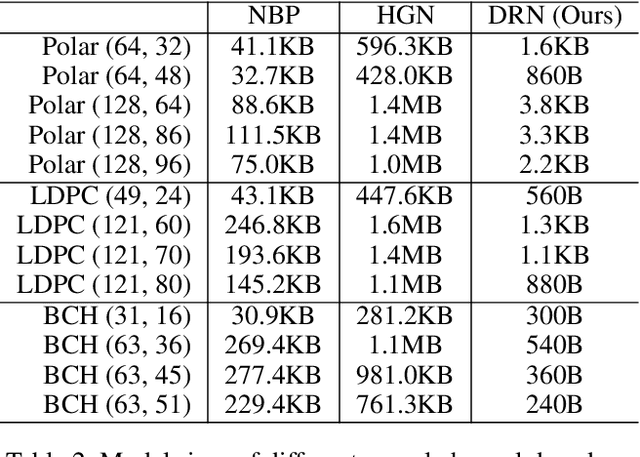
Recently deep neural networks have been successfully applied in channel coding to improve the decoding performance. However, the state-of-the-art neural channel decoders cannot achieve high decoding performance and low complexity simultaneously. To overcome this challenge, in this paper we propose doubly residual neural (DRN) decoder. By integrating both the residual input and residual learning to the design of neural channel decoder, DRN enables significant decoding performance improvement while maintaining low complexity. Extensive experiment results show that on different types of channel codes, our DRN decoder consistently outperform the state-of-the-art decoders in terms of decoding performance, model sizes and computational cost.
PERMDNN: Efficient Compressed DNN Architecture with Permuted Diagonal Matrices
Apr 23, 2020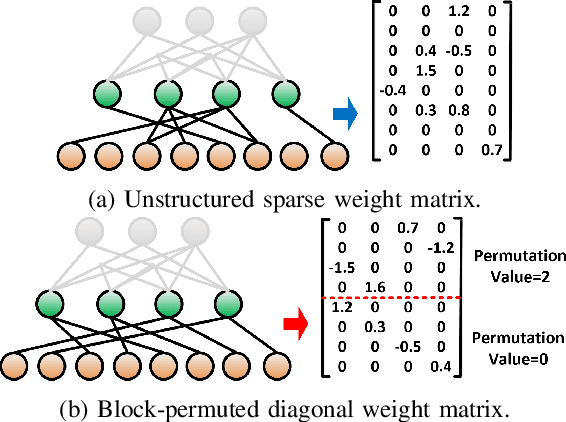
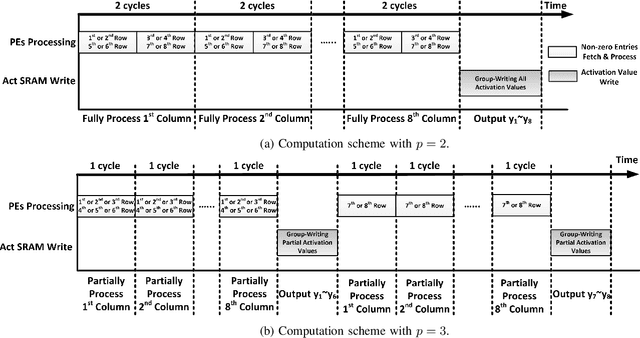

Deep neural network (DNN) has emerged as the most important and popular artificial intelligent (AI) technique. The growth of model size poses a key energy efficiency challenge for the underlying computing platform. Thus, model compression becomes a crucial problem. However, the current approaches are limited by various drawbacks. Specifically, network sparsification approach suffers from irregularity, heuristic nature and large indexing overhead. On the other hand, the recent structured matrix-based approach (i.e., CirCNN) is limited by the relatively complex arithmetic computation (i.e., FFT), less flexible compression ratio, and its inability to fully utilize input sparsity. To address these drawbacks, this paper proposes PermDNN, a novel approach to generate and execute hardware-friendly structured sparse DNN models using permuted diagonal matrices. Compared with unstructured sparsification approach, PermDNN eliminates the drawbacks of indexing overhead, non-heuristic compression effects and time-consuming retraining. Compared with circulant structure-imposing approach, PermDNN enjoys the benefits of higher reduction in computational complexity, flexible compression ratio, simple arithmetic computation and full utilization of input sparsity. We propose PermDNN architecture, a multi-processing element (PE) fully-connected (FC) layer-targeted computing engine. The entire architecture is highly scalable and flexible, and hence it can support the needs of different applications with different model configurations. We implement a 32-PE design using CMOS 28nm technology. Compared with EIE, PermDNN achieves 3.3x~4.8x higher throughout, 5.9x~8.5x better area efficiency and 2.8x~4.0x better energy efficiency on different workloads. Compared with CirCNN, PermDNN achieves 11.51x higher throughput and 3.89x better energy efficiency.