 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFourier Document Restoration for Robust Document Dewarping and Recognition
Mar 18, 2022
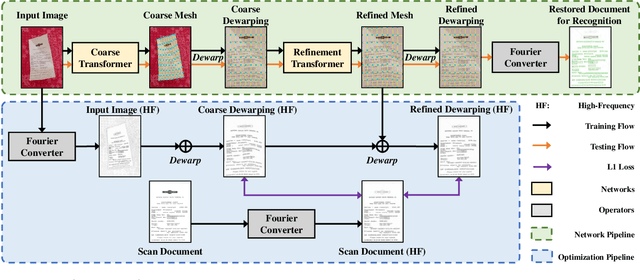
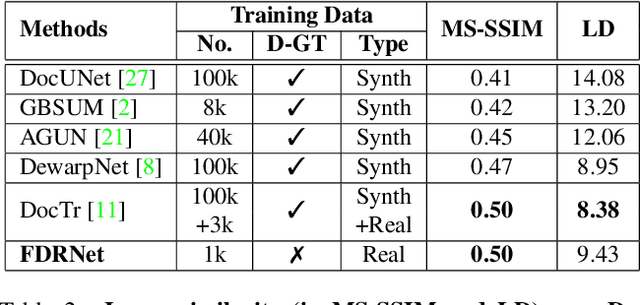
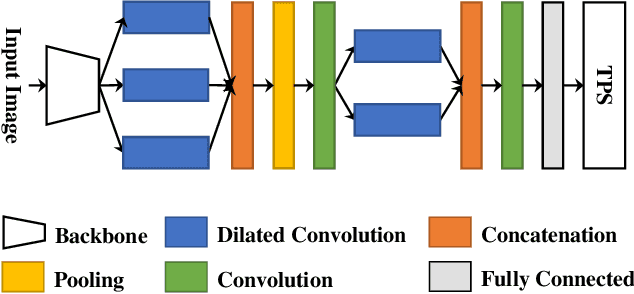
State-of-the-art document dewarping techniques learn to predict 3-dimensional information of documents which are prone to errors while dealing with documents with irregular distortions or large variations in depth. This paper presents FDRNet, a Fourier Document Restoration Network that can restore documents with different distortions and improve document recognition in a reliable and simpler manner. FDRNet focuses on high-frequency components in the Fourier space that capture most structural information but are largely free of degradation in appearance. It dewarps documents by a flexible Thin-Plate Spline transformation which can handle various deformations effectively without requiring deformation annotations in training. These features allow FDRNet to learn from a small amount of simply labeled training images, and the learned model can dewarp documents with complex geometric distortion and recognize the restored texts accurately. To facilitate document restoration research, we create a benchmark dataset consisting of over one thousand camera documents with different types of geometric and photometric distortion. Extensive experiments show that FDRNet outperforms the state-of-the-art by large margins on both dewarping and text recognition tasks. In addition, FDRNet requires a small amount of simply labeled training data and is easy to deploy.
Language Matters: A Weakly Supervised Pre-training Approach for Scene Text Detection and Spotting
Mar 08, 2022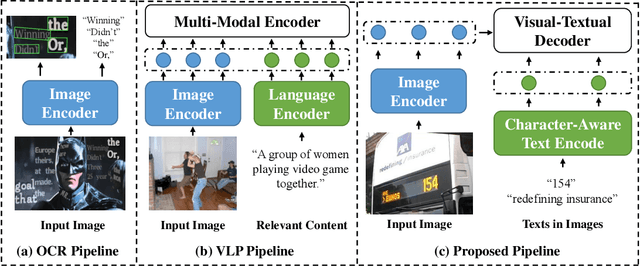
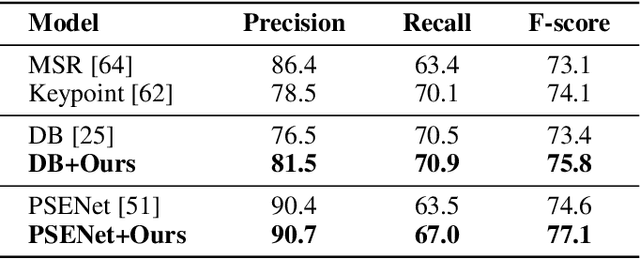
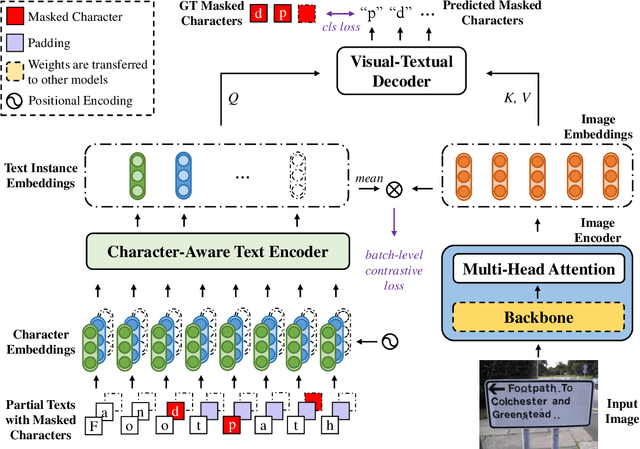

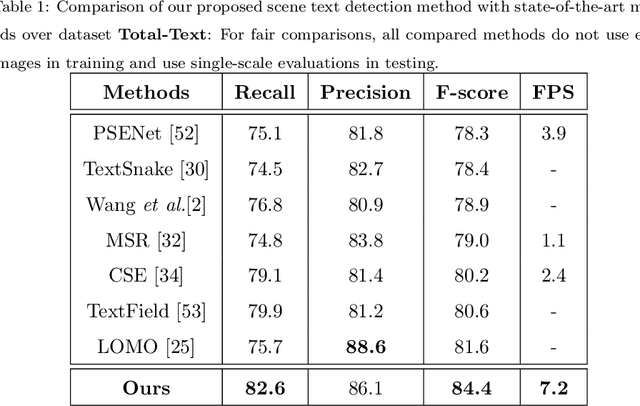
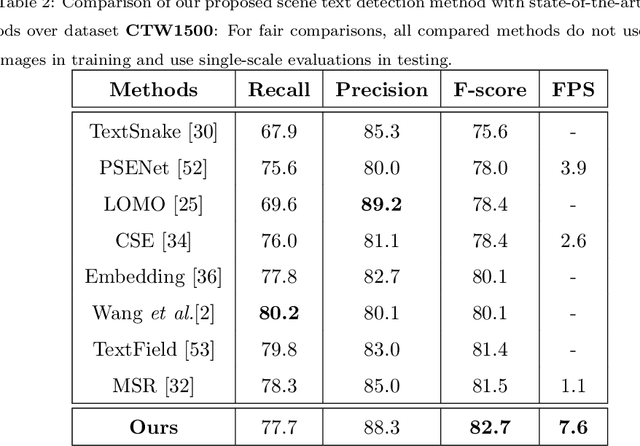
Recently, Vision-Language Pre-training (VLP) techniques have greatly benefited various vision-language tasks by jointly learning visual and textual representations, which intuitively helps in Optical Character Recognition (OCR) tasks due to the rich visual and textual information in scene text images. However, these methods cannot well cope with OCR tasks because of the difficulty in both instance-level text encoding and image-text pair acquisition (i.e. images and captured texts in them). This paper presents a weakly supervised pre-training method that can acquire effective scene text representations by jointly learning and aligning visual and textual information. Our network consists of an image encoder and a character-aware text encoder that extract visual and textual features, respectively, as well as a visual-textual decoder that models the interaction among textual and visual features for learning effective scene text representations. With the learning of textual features, the pre-trained model can attend texts in images well with character awareness. Besides, these designs enable the learning from weakly annotated texts (i.e. partial texts in images without text bounding boxes) which mitigates the data annotation constraint greatly. Experiments over the weakly annotated images in ICDAR2019-LSVT show that our pre-trained model improves F-score by +2.5% and +4.8% while transferring its weights to other text detection and spotting networks, respectively. In addition, the proposed method outperforms existing pre-training techniques consistently across multiple public datasets (e.g., +3.2% and +1.3% for Total-Text and CTW1500).
I2C2W: Image-to-Character-to-Word Transformers for Accurate Scene Text Recognition
May 18, 2021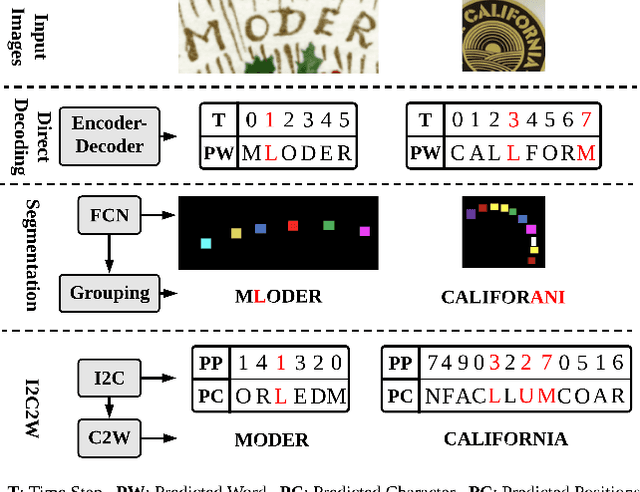
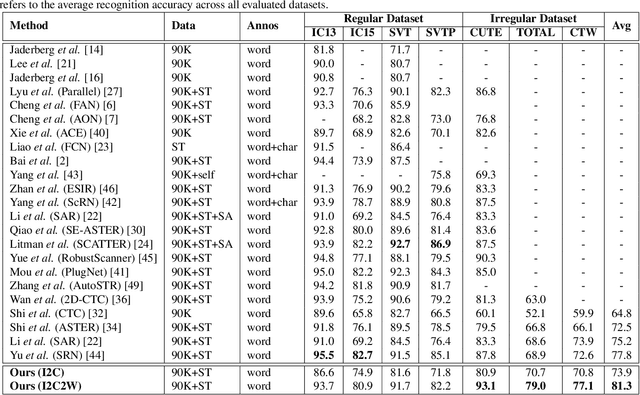
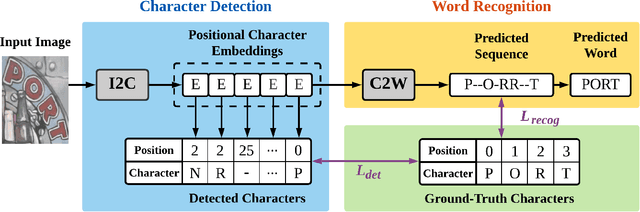
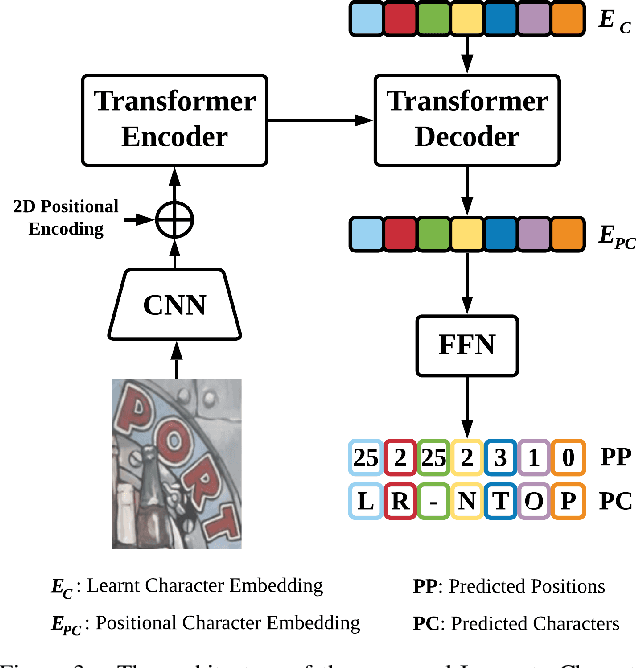
Leveraging the advances of natural language processing, most recent scene text recognizers adopt an encoder-decoder architecture where text images are first converted to representative features and then a sequence of characters via `direct decoding'. However, scene text images suffer from rich noises of different sources such as complex background and geometric distortions which often confuse the decoder and lead to incorrect alignment of visual features at noisy decoding time steps. This paper presents I2C2W, a novel scene text recognizer that is accurate and tolerant to various noises in scenes. I2C2W consists of an image-to-character module (I2C) and a character-to-word module (C2W) which are complementary and can be trained end-to-end. I2C detects characters and predicts their relative positions in a word. It strives to detect all possible characters including incorrect and redundant ones based on different alignments of visual features without the restriction of time steps. Taking the detected characters as input, C2W learns from character semantics and their positions to filter out incorrect and redundant detection and produce the final word recognition. Extensive experiments over seven public datasets show that I2C2W achieves superior recognition performances and outperforms the state-of-the-art by large margins on challenging irregular scene text datasets.
Detection and Rectification of Arbitrary Shaped Scene Texts by using Text Keypoints and Links
Mar 01, 2021

Detection and recognition of scene texts of arbitrary shapes remain a grand challenge due to the super-rich text shape variation in text line orientations, lengths, curvatures, etc. This paper presents a mask-guided multi-task network that detects and rectifies scene texts of arbitrary shapes reliably. Three types of keypoints are detected which specify the centre line and so the shape of text instances accurately. In addition, four types of keypoint links are detected of which the horizontal links associate the detected keypoints of each text instance and the vertical links predict a pair of landmark points (for each keypoint) along the upper and lower text boundary, respectively. Scene texts can be located and rectified by linking up the associated landmark points (giving localization polygon boxes) and transforming the polygon boxes via thin plate spline, respectively. Extensive experiments over several public datasets show that the use of text keypoints is tolerant to the variation in text orientations, lengths, and curvatures, and it achieves superior scene text detection and rectification performance as compared with state-of-the-art methods.
GA-DAN: Geometry-Aware Domain Adaptation Network for Scene Text Detection and Recognition
Jul 23, 2019
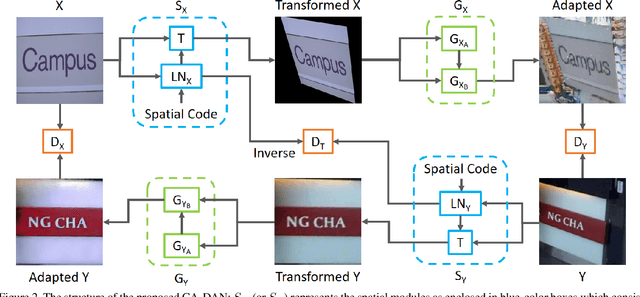
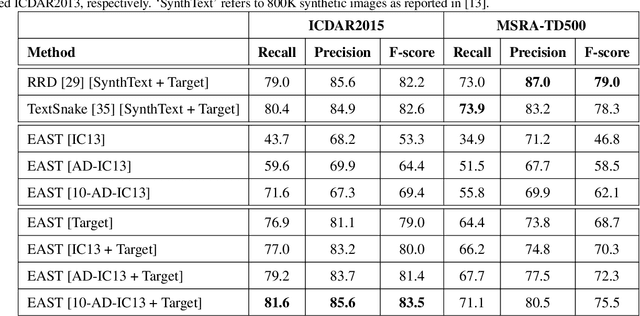
Recent adversarial learning research has achieved very impressive progress for modelling cross-domain data shifts in appearance space but its counterpart in modelling cross-domain shifts in geometry space lags far behind. This paper presents an innovative Geometry-Aware Domain Adaptation Network (GA-DAN) that is capable of modelling cross-domain shifts concurrently in both geometry space and appearance space and realistically converting images across domains with very different characteristics. In the proposed GA-DAN, a novel multi-modal spatial learning technique is designed which converts a source-domain image into multiple images of different spatial views as in the target domain. A new disentangled cycle-consistency loss is introduced which balances the cycle consistency in appearance and geometry spaces and improves the learning of the whole network greatly. The proposed GA-DAN has been evaluated for the classic scene text detection and recognition tasks, and experiments show that the domain-adapted images achieve superior scene text detection and recognition performance while applied to network training.
MSR: Multi-Scale Shape Regression for Scene Text Detection
Jan 09, 2019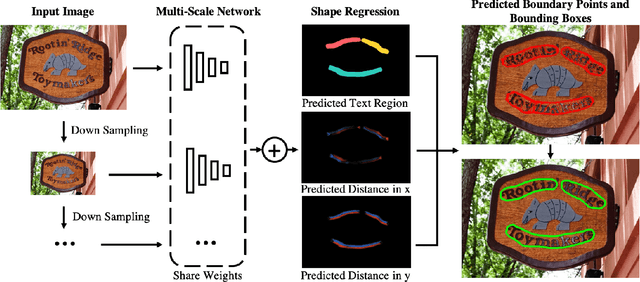
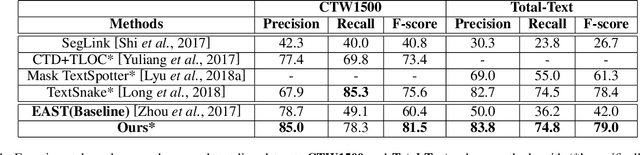
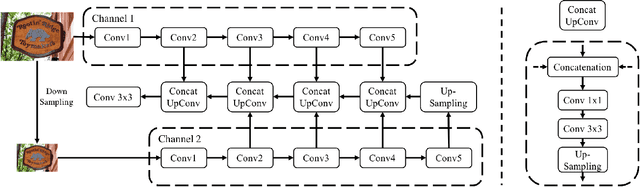
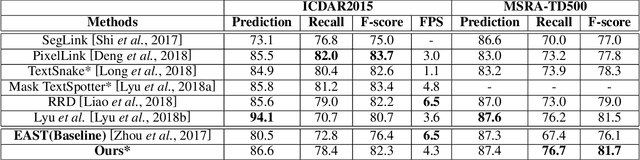
State-of-the-art scene text detection techniques predict quadrilateral boxes which are prone to localization errors while dealing with long or curved text lines in scenes. This paper presents a novel multi-scale shape regression network (MSR) that is capable of locating scene texts of arbitrary orientations, shapes and lengths accurately. The MSR detects scene texts by predicting dense text boundary points instead of sparse quadrilateral vertices which often suffers from regression errors while dealing with long text lines. The detection by linking of dense boundary points also enables accurate localization of scene texts of arbitrary orientations and shapes whereas most existing techniques using quadrilaterals often include undesired background to the ensuing text recognition. Additionally, the multi-scale network extracts and fuses features at different scales concurrently and seamlessly which demonstrates superb tolerance to the text scale variation. Extensive experiments over several public datasets show that MSR obtains superior detection performance for both curved and arbitrarily oriented text lines of different lengths, e.g. 80.7 f-score for the CTW1500, 81.7 f-score for the MSRA-TD500, etc.
Verisimilar Image Synthesis for Accurate Detection and Recognition of Texts in Scenes
Sep 26, 2018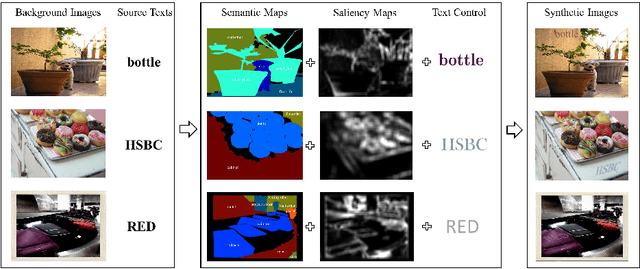
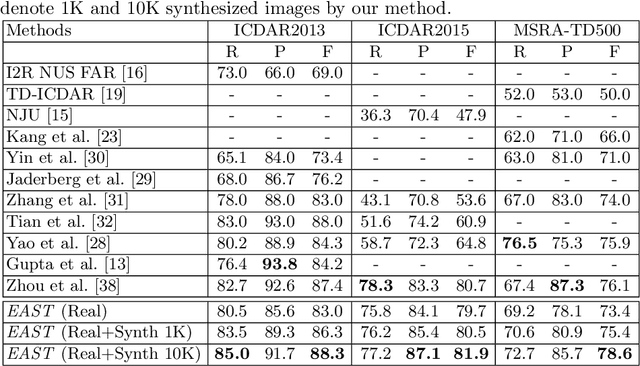

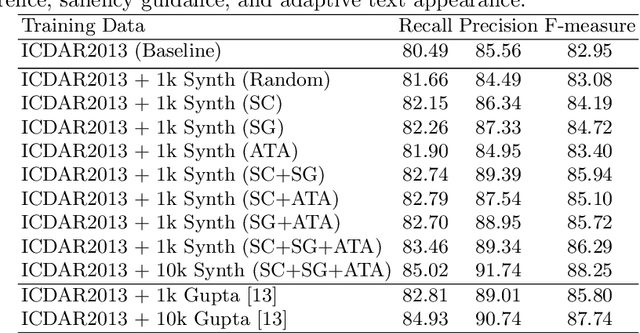
The requirement of large amounts of annotated images has become one grand challenge while training deep neural network models for various visual detection and recognition tasks. This paper presents a novel image synthesis technique that aims to generate a large amount of annotated scene text images for training accurate and robust scene text detection and recognition models. The proposed technique consists of three innovative designs. First, it realizes "semantic coherent" synthesis by embedding texts at semantically sensible regions within the background image, where the semantic coherence is achieved by leveraging the semantic annotations of objects and image regions that have been created in the prior semantic segmentation research. Second, it exploits visual saliency to determine the embedding locations within each semantic sensible region, which coincides with the fact that texts are often placed around homogeneous regions for better visibility in scenes. Third, it designs an adaptive text appearance model that determines the color and brightness of embedded texts by learning from the feature of real scene text images adaptively. The proposed technique has been evaluated over five public datasets and the experiments show its superior performance in training accurate and robust scene text detection and recognition models.
Accurate Scene Text Detection through Border Semantics Awareness and Bootstrapping
Jul 31, 2018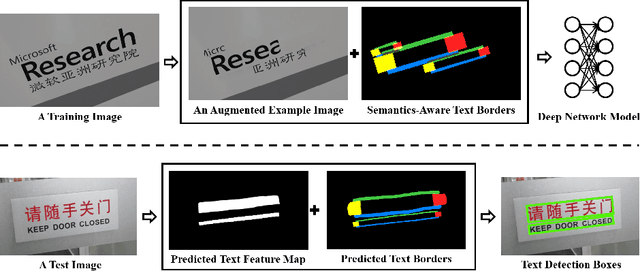
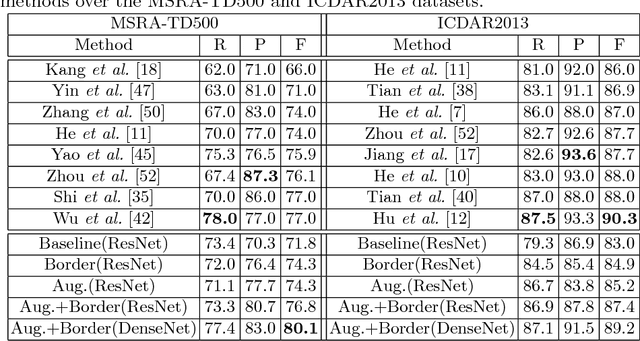

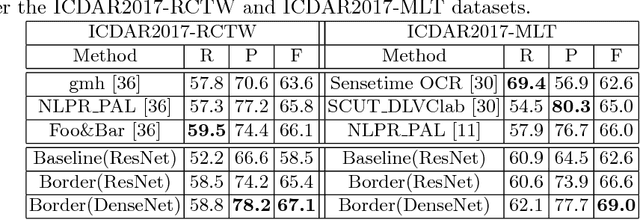
This paper presents a scene text detection technique that exploits bootstrapping and text border semantics for accurate localization of texts in scenes. A novel bootstrapping technique is designed which samples multiple 'subsections' of a word or text line and accordingly relieves the constraint of limited training data effectively. At the same time, the repeated sampling of text 'subsections' improves the consistency of the predicted text feature maps which is critical in predicting a single complete instead of multiple broken boxes for long words or text lines. In addition, a semantics-aware text border detection technique is designed which produces four types of text border segments for each scene text. With semantics-aware text borders, scene texts can be localized more accurately by regressing text pixels around the ends of words or text lines instead of all text pixels which often leads to inaccurate localization while dealing with long words or text lines. Extensive experiments demonstrate the effectiveness of the proposed techniques, and superior performance is obtained over several public datasets, e. g. 80.1 f-score for the MSRA-TD500, 67.1 f-score for the ICDAR2017-RCTW, etc.