 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Dense States: Elevating Sparse Transcoders to Active Operators for Latent Reasoning
Feb 02, 2026Latent reasoning compresses the chain-of-thought (CoT) into continuous hidden states, yet existing methods rely on dense latent transitions that remain difficult to interpret and control. Meanwhile, sparse representation models uncover human-interpretable semantic features but remain largely confined to post-hoc analysis. We reconcile this tension by proposing LSTR (Latent Sparse Transcoder Reasoning), a latent reasoning framework that elevates functional sparse transcoders into active reasoning operators to perform multi-step computation through sparse semantic transitions. At its core, LSTR employs a Latent Transition Transcoder (LTT) with a residual skip architecture that decouples linear manifold transport from sparse semantic updates, enabling controllable semantic resolution via explicit sparsity constraints. Extensive experiments show that LSTR preserves reasoning accuracy and compression efficiency while substantially improving interpretability over dense latent baselines. Causal interventions and trajectory analyses further demonstrate that these sparse features act as both interpretable and causally effective operators in the reasoning process.
LoD: Loss-difference OOD Detection by Intentionally Label-Noisifying Unlabeled Wild Data
May 19, 2025Using unlabeled wild data containing both in-distribution (ID) and out-of-distribution (OOD) data to improve the safety and reliability of models has recently received increasing attention. Existing methods either design customized losses for labeled ID and unlabeled wild data then perform joint optimization, or first filter out OOD data from the latter then learn an OOD detector. While achieving varying degrees of success, two potential issues remain: (i) Labeled ID data typically dominates the learning of models, inevitably making models tend to fit OOD data as IDs; (ii) The selection of thresholds for identifying OOD data in unlabeled wild data usually faces dilemma due to the unavailability of pure OOD samples. To address these issues, we propose a novel loss-difference OOD detection framework (LoD) by \textit{intentionally label-noisifying} unlabeled wild data. Such operations not only enable labeled ID data and OOD data in unlabeled wild data to jointly dominate the models' learning but also ensure the distinguishability of the losses between ID and OOD samples in unlabeled wild data, allowing the classic clustering technique (e.g., K-means) to filter these OOD samples without requiring thresholds any longer. We also provide theoretical foundation for LoD's viability, and extensive experiments verify its superiority.
ULFine: Unbiased Lightweight Fine-tuning for Foundation-Model-Assisted Long-Tailed Semi-Supervised Learning
May 08, 2025Based on the success of large-scale visual foundation models like CLIP in various downstream tasks, this paper initially attempts to explore their impact on Long-Tailed Semi-Supervised Learning (LTSSL) by employing the foundation model with three strategies: Linear Probing (LP), Lightweight Fine-Tuning (LFT), and Full Fine-Tuning (FFT). Our analysis presents the following insights: i) Compared to LTSSL algorithms trained from scratch, FFT results in a decline in model performance, whereas LP and LFT, although boosting overall model performance, exhibit negligible benefits to tail classes. ii) LP produces numerous false pseudo-labels due to \textit{underlearned} training data, while LFT can reduce the number of these false labels but becomes overconfident about them owing to \textit{biased fitting} training data. This exacerbates the pseudo-labeled and classifier biases inherent in LTSSL, limiting performance improvement in the tail classes. With these insights, we propose a Unbiased Lightweight Fine-tuning strategy, \textbf{ULFine}, which mitigates the overconfidence via confidence-aware adaptive fitting of textual prototypes and counteracts the pseudo-labeled and classifier biases via complementary fusion of dual logits. Extensive experiments demonstrate that ULFine markedly decreases training costs by over ten times and substantially increases prediction accuracies compared to state-of-the-art methods.
Recent Advances in Out-of-Distribution Detection with CLIP-Like Models: A Survey
May 05, 2025Out-of-distribution detection (OOD) is a pivotal task for real-world applications that trains models to identify samples that are distributionally different from the in-distribution (ID) data during testing. Recent advances in AI, particularly Vision-Language Models (VLMs) like CLIP, have revolutionized OOD detection by shifting from traditional unimodal image detectors to multimodal image-text detectors. This shift has inspired extensive research; however, existing categorization schemes (e.g., few- or zero-shot types) still rely solely on the availability of ID images, adhering to a unimodal paradigm. To better align with CLIP's cross-modal nature, we propose a new categorization framework rooted in both image and text modalities. Specifically, we categorize existing methods based on how visual and textual information of OOD data is utilized within image + text modalities, and further divide them into four groups: OOD Images (i.e., outliers) Seen or Unseen, and OOD Texts (i.e., learnable vectors or class names) Known or Unknown, across two training strategies (i.e., train-free or training-required). More importantly, we discuss open problems in CLIP-like OOD detection and highlight promising directions for future research, including cross-domain integration, practical applications, and theoretical understanding.
Filter, Obstruct and Dilute: Defending Against Backdoor Attacks on Semi-Supervised Learning
Feb 09, 2025Recent studies have verified that semi-supervised learning (SSL) is vulnerable to data poisoning backdoor attacks. Even a tiny fraction of contaminated training data is sufficient for adversaries to manipulate up to 90\% of the test outputs in existing SSL methods. Given the emerging threat of backdoor attacks designed for SSL, this work aims to protect SSL against such risks, marking it as one of the few known efforts in this area. Specifically, we begin by identifying that the spurious correlations between the backdoor triggers and the target class implanted by adversaries are the primary cause of manipulated model predictions during the test phase. To disrupt these correlations, we utilize three key techniques: Gaussian Filter, complementary learning and trigger mix-up, which collectively filter, obstruct and dilute the influence of backdoor attacks in both data pre-processing and feature learning. Experimental results demonstrate that our proposed method, Backdoor Invalidator (BI), significantly reduces the average attack success rate from 84.7\% to 1.8\% across different state-of-the-art backdoor attacks. It is also worth mentioning that BI does not sacrifice accuracy on clean data and is supported by a theoretical guarantee of its generalization capability.
Forgetting, Ignorance or Myopia: Revisiting Key Challenges in Online Continual Learning
Sep 28, 2024Online continual learning requires the models to learn from constant, endless streams of data. While significant efforts have been made in this field, most were focused on mitigating the catastrophic forgetting issue to achieve better classification ability, at the cost of a much heavier training workload. They overlooked that in real-world scenarios, e.g., in high-speed data stream environments, data do not pause to accommodate slow models. In this paper, we emphasize that model throughput -- defined as the maximum number of training samples that a model can process within a unit of time -- is equally important. It directly limits how much data a model can utilize and presents a challenging dilemma for current methods. With this understanding, we revisit key challenges in OCL from both empirical and theoretical perspectives, highlighting two critical issues beyond the well-documented catastrophic forgetting: Model's ignorance: the single-pass nature of OCL challenges models to learn effective features within constrained training time and storage capacity, leading to a trade-off between effective learning and model throughput; Model's myopia: the local learning nature of OCL on the current task leads the model to adopt overly simplified, task-specific features and excessively sparse classifier, resulting in the gap between the optimal solution for the current task and the global objective. To tackle these issues, we propose the Non-sparse Classifier Evolution framework (NsCE) to facilitate effective global discriminative feature learning with minimal time cost. NsCE integrates non-sparse maximum separation regularization and targeted experience replay techniques with the help of pre-trained models, enabling rapid acquisition of new globally discriminative features.
All-around Neural Collapse for Imbalanced Classification
Aug 14, 2024



Neural Collapse (NC) presents an elegant geometric structure that enables individual activations (features), class means and classifier (weights) vectors to reach \textit{optimal} inter-class separability during the terminal phase of training on a \textit{balanced} dataset. Once shifted to imbalanced classification, such an optimal structure of NC can be readily destroyed by the notorious \textit{minority collapse}, where the classifier vectors corresponding to the minority classes are squeezed. In response, existing works endeavor to recover NC typically by optimizing classifiers. However, we discover that this squeezing phenomenon is not only confined to classifier vectors but also occurs with class means. Consequently, reconstructing NC solely at the classifier aspect may be futile, as the feature means remain compressed, leading to the violation of inherent \textit{self-duality} in NC (\textit{i.e.}, class means and classifier vectors converge mutually) and incidentally, resulting in an unsatisfactory collapse of individual activations towards the corresponding class means. To shake off these dilemmas, we present a unified \textbf{All}-around \textbf{N}eural \textbf{C}ollapse framework (AllNC), aiming to comprehensively restore NC across multiple aspects including individual activations, class means and classifier vectors. We thoroughly analyze its effectiveness and verify on multiple benchmark datasets that it achieves state-of-the-art in both balanced and imbalanced settings.
Dynamic Against Dynamic: An Open-set Self-learning Framework
Apr 27, 2024In open-set recognition, existing methods generally learn statically fixed decision boundaries using known classes to reject unknown classes. Though they have achieved promising results, such decision boundaries are evidently insufficient for universal unknown classes in dynamic and open scenarios as they can potentially appear at any position in the feature space. Moreover, these methods just simply reject unknown class samples during testing without any effective utilization for them. In fact, such samples completely can constitute the true instantiated representation of the unknown classes to further enhance the model's performance. To address these issues, this paper proposes a novel dynamic against dynamic idea, i.e., dynamic method against dynamic changing open-set world, where an open-set self-learning (OSSL) framework is correspondingly developed. OSSL starts with a good closed-set classifier trained by known classes and utilizes available test samples for model adaptation during testing, thus gaining the adaptability to changing data distributions. In particular, a novel self-matching module is designed for OSSL, which can achieve the adaptation in automatically identifying known class samples while rejecting unknown class samples which are further utilized to enhance the discriminability of the model as the instantiated representation of unknown classes. Our method establishes new performance milestones respectively in almost all standard and cross-data benchmarks.
All Beings Are Equal in Open Set Recognition
Jan 31, 2024In open-set recognition (OSR), a promising strategy is exploiting pseudo-unknown data outside given $K$ known classes as an additional $K$+$1$-th class to explicitly model potential open space. However, treating unknown classes without distinction is unequal for them relative to known classes due to the category-agnostic and scale-agnostic of the unknowns. This inevitably not only disrupts the inherent distributions of unknown classes but also incurs both class-wise and instance-wise imbalances between known and unknown classes. Ideally, the OSR problem should model the whole class space as $K$+$\infty$, but enumerating all unknowns is impractical. Since the core of OSR is to effectively model the boundaries of known classes, this means just focusing on the unknowns nearing the boundaries of targeted known classes seems sufficient. Thus, as a compromise, we convert the open classes from infinite to $K$, with a novel concept Target-Aware Universum (TAU) and propose a simple yet effective framework Dual Contrastive Learning with Target-Aware Universum (DCTAU). In details, guided by the targeted known classes, TAU automatically expands the unknown classes from the previous $1$ to $K$, effectively alleviating the distribution disruption and the imbalance issues mentioned above. Then, a novel Dual Contrastive (DC) loss is designed, where all instances irrespective of known or TAU are considered as positives to contrast with their respective negatives. Experimental results indicate DCTAU sets a new state-of-the-art.
Class-Aware Universum Inspired Re-Balance Learning for Long-Tailed Recognition
Aug 11, 2022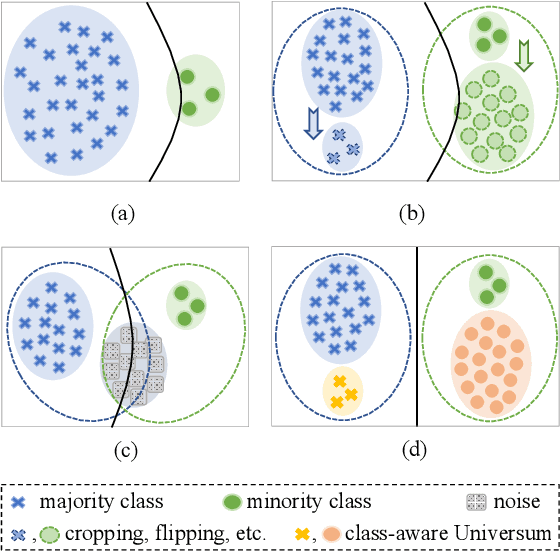

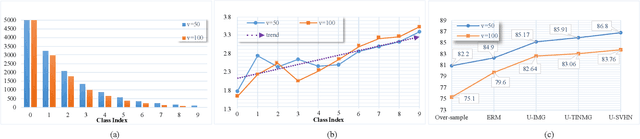

Data augmentation for minority classes is an effective strategy for long-tailed recognition, thus developing a large number of methods. Although these methods all ensure the balance in sample quantity, the quality of the augmented samples is not always satisfactory for recognition, being prone to such problems as over-fitting, lack of diversity, semantic drift, etc. For these issues, we propose the Class-aware Universum Inspired Re-balance Learning(CaUIRL) for long-tailed recognition, which endows the Universum with class-aware ability to re-balance individual minority classes from both sample quantity and quality. In particular, we theoretically prove that the classifiers learned by CaUIRL are consistent with those learned under the balanced condition from a Bayesian perspective. In addition, we further develop a higher-order mixup approach, which can automatically generate class-aware Universum(CaU) data without resorting to any external data. Unlike the traditional Universum, such generated Universum additionally takes the domain similarity, class separability, and sample diversity into account. Extensive experiments on benchmark datasets demonstrate the surprising advantages of our method, especially the top1 accuracy in minority classes is improved by 1.9% 6% compared to the state-of-the-art method.