 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose-Free Omnidirectional Gaussian Splatting for 360-Degree Videos with Consistent Depth Priors
Mar 24, 2026Omnidirectional 3D Gaussian Splatting with panoramas is a key technique for 3D scene representation, and existing methods typically rely on slow SfM to provide camera poses and sparse points priors. In this work, we propose a pose-free omnidirectional 3DGS method, named PFGS360, that reconstructs 3D Gaussians from unposed omnidirectional videos. To achieve accurate camera pose estimation, we first construct a spherical consistency-aware pose estimation module, which recovers poses by establishing consistent 2D-3D correspondences between the reconstructed Gaussians and the unposed images using Gaussians' internal depth priors. Besides, to enhance the fidelity of novel view synthesis, we introduce a depth-inlier-aware densification module to extract depth inliers and Gaussian outliers with consistent monocular depth priors, enabling efficient Gaussian densification and achieving photorealistic novel view synthesis. The experiments show significant outperformance over existing pose-free and pose-aware 3DGS methods on both real-world and synthetic 360-degree videos. Code is available at https://github.com/zcq15/PFGS360.
Memory-Guided View Refinement for Dynamic Human-in-the-loop EQA
Mar 10, 2026Embodied Question Answering (EQA) has traditionally been evaluated in temporally stable environments where visual evidence can be accumulated reliably. However, in dynamic, human-populated scenes, human activities and occlusions introduce significant perceptual non-stationarity: task-relevant cues are transient and view-dependent, while a store-then-retrieve strategy over-accumulates redundant evidence and increases inference cost. This setting exposes two practical challenges for EQA agents: resolving ambiguity caused by viewpoint-dependent occlusions, and maintaining compact yet up-to-date evidence for efficient inference. To enable systematic study of this setting, we introduce DynHiL-EQA, a human-in-the-loop EQA dataset with two subsets: a Dynamic subset featuring human activities and temporal changes, and a Static subset with temporally stable observations. To address the above challenges, we present DIVRR (Dynamic-Informed View Refinement and Relevance-guided Adaptive Memory Selection), a training-free framework that couples relevance-guided view refinement with selective memory admission. By verifying ambiguous observations before committing them and retaining only informative evidence, DIVRR improves robustness under occlusions while preserving fast inference with compact memory. Extensive experiments on DynHiL-EQA and the established HM-EQA dataset demonstrate that DIVRR consistently improves over existing baselines in both dynamic and static settings while maintaining high inference efficiency.
ACDNet: Adaptively Combined Dilated Convolution for Monocular Panorama Depth Estimation
Dec 29, 2021
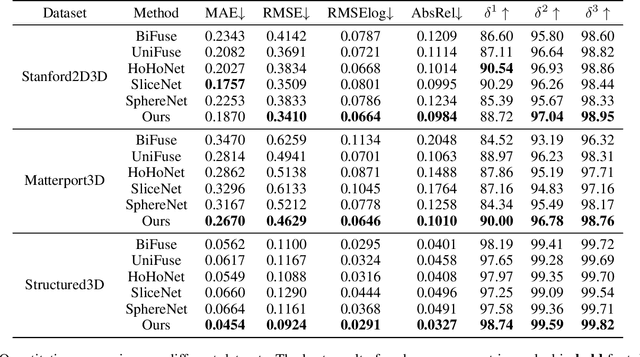
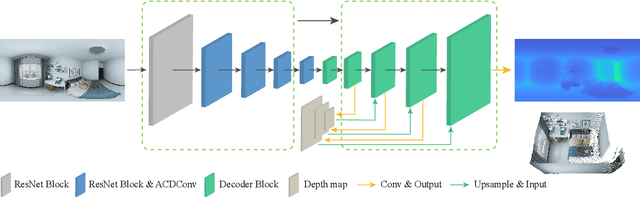
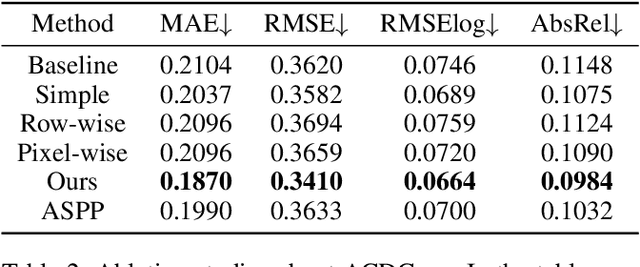
Depth estimation is a crucial step for 3D reconstruction with panorama images in recent years. Panorama images maintain the complete spatial information but introduce distortion with equirectangular projection. In this paper, we propose an ACDNet based on the adaptively combined dilated convolution to predict the dense depth map for a monocular panoramic image. Specifically, we combine the convolution kernels with different dilations to extend the receptive field in the equirectangular projection. Meanwhile, we introduce an adaptive channel-wise fusion module to summarize the feature maps and get diverse attention areas in the receptive field along the channels. Due to the utilization of channel-wise attention in constructing the adaptive channel-wise fusion module, the network can capture and leverage the cross-channel contextual information efficiently. Finally, we conduct depth estimation experiments on three datasets (both virtual and real-world) and the experimental results demonstrate that our proposed ACDNet substantially outperforms the current state-of-the-art (SOTA) methods. Our codes and model parameters are accessed in https://github.com/zcq15/ACDNet.