 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy Blur: Quantifying Privacy and Utility for Image Data Release
Dec 18, 2025
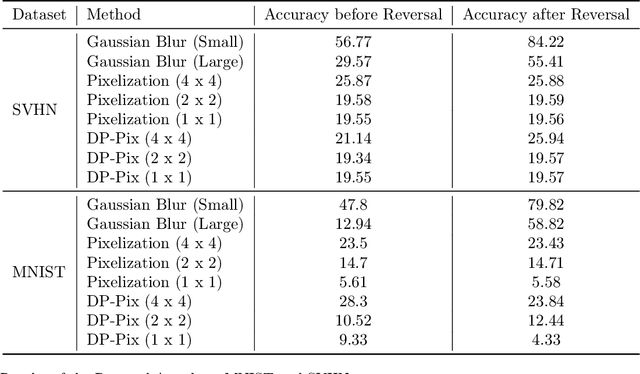

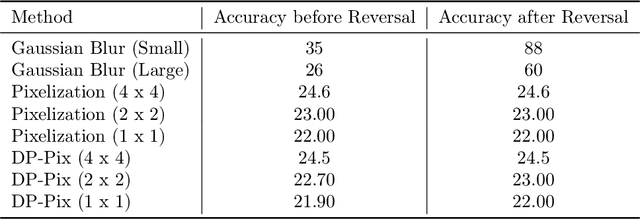
Image data collected in the wild often contains private information such as faces and license plates, and responsible data release must ensure that this information stays hidden. At the same time, released data should retain its usefulness for model-training. The standard method for private information obfuscation in images is Gaussian blurring. In this work, we show that practical implementations of Gaussian blurring are reversible enough to break privacy. We then take a closer look at the privacy-utility tradeoffs offered by three other obfuscation algorithms -- pixelization, pixelization and noise addition (DP-Pix), and cropping. Privacy is evaluated by reversal and discrimination attacks, while utility by the quality of the learnt representations when the model is trained on data with obfuscated faces. We show that the most popular industry-standard method, Gaussian blur is the least private of the four -- being susceptible to reversal attacks in its practical low-precision implementations. In contrast, pixelization and pixelization plus noise addition, when used at the right level of granularity, offer both privacy and utility for a number of computer vision tasks. We make our proposed methods together with suggested parameters available in a software package called Privacy Blur.
AHA! Animating Human Avatars in Diverse Scenes with Gaussian Splatting
Nov 13, 2025We present a novel framework for animating humans in 3D scenes using 3D Gaussian Splatting (3DGS), a neural scene representation that has recently achieved state-of-the-art photorealistic results for novel-view synthesis but remains under-explored for human-scene animation and interaction. Unlike existing animation pipelines that use meshes or point clouds as the underlying 3D representation, our approach introduces the use of 3DGS as the 3D representation to the problem of animating humans in scenes. By representing humans and scenes as Gaussians, our approach allows for geometry-consistent free-viewpoint rendering of humans interacting with 3D scenes. Our key insight is that the rendering can be decoupled from the motion synthesis and each sub-problem can be addressed independently, without the need for paired human-scene data. Central to our method is a Gaussian-aligned motion module that synthesizes motion without explicit scene geometry, using opacity-based cues and projected Gaussian structures to guide human placement and pose alignment. To ensure natural interactions, we further propose a human-scene Gaussian refinement optimization that enforces realistic contact and navigation. We evaluate our approach on scenes from Scannet++ and the SuperSplat library, and on avatars reconstructed from sparse and dense multi-view human capture. Finally, we demonstrate that our framework allows for novel applications such as geometry-consistent free-viewpoint rendering of edited monocular RGB videos with new animated humans, showcasing the unique advantage of 3DGS for monocular video-based human animation.
Pressure2Motion: Hierarchical Motion Synthesis from Ground Pressure with Text Guidance
Nov 07, 2025We present Pressure2Motion, a novel motion capture algorithm that synthesizes human motion from a ground pressure sequence and text prompt. It eliminates the need for specialized lighting setups, cameras, or wearable devices, making it suitable for privacy-preserving, low-light, and low-cost motion capture scenarios. Such a task is severely ill-posed due to the indeterminate nature of the pressure signals to full-body motion. To address this issue, we introduce Pressure2Motion, a generative model that leverages pressure features as input and utilizes a text prompt as a high-level guiding constraint. Specifically, our model utilizes a dual-level feature extractor that accurately interprets pressure data, followed by a hierarchical diffusion model that discerns broad-scale movement trajectories and subtle posture adjustments. Both the physical cues gained from the pressure sequence and the semantic guidance derived from descriptive texts are leveraged to guide the motion generation with precision. To the best of our knowledge, Pressure2Motion is a pioneering work in leveraging both pressure data and linguistic priors for motion generation, and the established MPL benchmark is the first benchmark for this task. Experiments show our method generates high-fidelity, physically plausible motions, establishing a new state-of-the-art for this task. The codes and benchmarks will be publicly released upon publication.
Sketch2PoseNet: Efficient and Generalized Sketch to 3D Human Pose Prediction
Oct 30, 20253D human pose estimation from sketches has broad applications in computer animation and film production. Unlike traditional human pose estimation, this task presents unique challenges due to the abstract and disproportionate nature of sketches. Previous sketch-to-pose methods, constrained by the lack of large-scale sketch-3D pose annotations, primarily relied on optimization with heuristic rules-an approach that is both time-consuming and limited in generalizability. To address these challenges, we propose a novel approach leveraging a "learn from synthesis" strategy. First, a diffusion model is trained to synthesize sketch images from 2D poses projected from 3D human poses, mimicking disproportionate human structures in sketches. This process enables the creation of a synthetic dataset, SKEP-120K, consisting of 120k accurate sketch-3D pose annotation pairs across various sketch styles. Building on this synthetic dataset, we introduce an end-to-end data-driven framework for estimating human poses and shapes from diverse sketch styles. Our framework combines existing 2D pose detectors and generative diffusion priors for sketch feature extraction with a feed-forward neural network for efficient 2D pose estimation. Multiple heuristic loss functions are incorporated to guarantee geometric coherence between the derived 3D poses and the detected 2D poses while preserving accurate self-contacts. Qualitative, quantitative, and subjective evaluations collectively show that our model substantially surpasses previous ones in both estimation accuracy and speed for sketch-to-pose tasks.
Ponimator: Unfolding Interactive Pose for Versatile Human-human Interaction Animation
Oct 16, 2025Close-proximity human-human interactive poses convey rich contextual information about interaction dynamics. Given such poses, humans can intuitively infer the context and anticipate possible past and future dynamics, drawing on strong priors of human behavior. Inspired by this observation, we propose Ponimator, a simple framework anchored on proximal interactive poses for versatile interaction animation. Our training data consists of close-contact two-person poses and their surrounding temporal context from motion-capture interaction datasets. Leveraging interactive pose priors, Ponimator employs two conditional diffusion models: (1) a pose animator that uses the temporal prior to generate dynamic motion sequences from interactive poses, and (2) a pose generator that applies the spatial prior to synthesize interactive poses from a single pose, text, or both when interactive poses are unavailable. Collectively, Ponimator supports diverse tasks, including image-based interaction animation, reaction animation, and text-to-interaction synthesis, facilitating the transfer of interaction knowledge from high-quality mocap data to open-world scenarios. Empirical experiments across diverse datasets and applications demonstrate the universality of the pose prior and the effectiveness and robustness of our framework.
RL Is a Hammer and LLMs Are Nails: A Simple Reinforcement Learning Recipe for Strong Prompt Injection
Oct 06, 2025Prompt injection poses a serious threat to the reliability and safety of LLM agents. Recent defenses against prompt injection, such as Instruction Hierarchy and SecAlign, have shown notable robustness against static attacks. However, to more thoroughly evaluate the robustness of these defenses, it is arguably necessary to employ strong attacks such as automated red-teaming. To this end, we introduce RL-Hammer, a simple recipe for training attacker models that automatically learn to perform strong prompt injections and jailbreaks via reinforcement learning. RL-Hammer requires no warm-up data and can be trained entirely from scratch. To achieve high ASRs against industrial-level models with defenses, we propose a set of practical techniques that enable highly effective, universal attacks. Using this pipeline, RL-Hammer reaches a 98% ASR against GPT-4o and a $72\%$ ASR against GPT-5 with the Instruction Hierarchy defense. We further discuss the challenge of achieving high diversity in attacks, highlighting how attacker models tend to reward-hack diversity objectives. Finally, we show that RL-Hammer can evade multiple prompt injection detectors. We hope our work advances automatic red-teaming and motivates the development of stronger, more principled defenses. Code is available at https://github.com/facebookresearch/rl-injector.
Meta SecAlign: A Secure Foundation LLM Against Prompt Injection Attacks
Jul 03, 2025Prompt injection attacks pose a significant security threat to LLM-integrated applications. Model-level defenses have shown strong effectiveness, but are currently deployed into commercial-grade models in a closed-source manner. We believe open-source models are needed by the AI security community, where co-development of attacks and defenses through open research drives scientific progress in mitigation against prompt injection attacks. To this end, we develop Meta SecAlign, the first open-source and open-weight LLM with built-in model-level defense that achieves commercial-grade model performance. We provide complete details of our training recipe, which utilizes an improved version of the SOTA SecAlign defense. Evaluations on 9 utility benchmarks and 7 security benchmarks show that Meta SecAlign, despite being trained on a generic instruction-tuning dataset, confers security in unseen downstream tasks, including tool-calling and agentic web navigation, in addition general instruction-following. Our best model -- Meta-SecAlign-70B -- achieves state-of-the-art robustness against prompt injection attacks and comparable utility to closed-source commercial LLM with model-level defense.
Machine Learning with Privacy for Protected Attributes
Jun 24, 2025



Differential privacy (DP) has become the standard for private data analysis. Certain machine learning applications only require privacy protection for specific protected attributes. Using naive variants of differential privacy in such use cases can result in unnecessary degradation of utility. In this work, we refine the definition of DP to create a more general and flexible framework that we call feature differential privacy (FDP). Our definition is simulation-based and allows for both addition/removal and replacement variants of privacy, and can handle arbitrary and adaptive separation of protected and non-protected features. We prove the properties of FDP, such as adaptive composition, and demonstrate its implications for limiting attribute inference attacks. We also propose a modification of the standard DP-SGD algorithm that satisfies FDP while leveraging desirable properties such as amplification via sub-sampling. We apply our framework to various machine learning tasks and show that it can significantly improve the utility of DP-trained models when public features are available. For example, we train diffusion models on the AFHQ dataset of animal faces and observe a drastic improvement in FID compared to DP, from 286.7 to 101.9 at $\epsilon=8$, assuming that the blurred version of a training image is available as a public feature. Overall, our work provides a new approach to private data analysis that can help reduce the utility cost of DP while still providing strong privacy guarantees.
How much do language models memorize?
May 30, 2025We propose a new method for estimating how much a model ``knows'' about a datapoint and use it to measure the capacity of modern language models. Prior studies of language model memorization have struggled to disentangle memorization from generalization. We formally separate memorization into two components: \textit{unintended memorization}, the information a model contains about a specific dataset, and \textit{generalization}, the information a model contains about the true data-generation process. When we completely eliminate generalization, we can compute the total memorization, which provides an estimate of model capacity: our measurements estimate that GPT-style models have a capacity of approximately 3.6 bits per parameter. We train language models on datasets of increasing size and observe that models memorize until their capacity fills, at which point ``grokking'' begins, and unintended memorization decreases as models begin to generalize. We train hundreds of transformer language models ranging from $500K$ to $1.5B$ parameters and produce a series of scaling laws relating model capacity and data size to membership inference.
RoFL: Robust Fingerprinting of Language Models
May 19, 2025AI developers are releasing large language models (LLMs) under a variety of different licenses. Many of these licenses restrict the ways in which the models or their outputs may be used. This raises the question how license violations may be recognized. In particular, how can we identify that an API or product uses (an adapted version of) a particular LLM? We present a new method that enable model developers to perform such identification via fingerprints: statistical patterns that are unique to the developer's model and robust to common alterations of that model. Our method permits model identification in a black-box setting using a limited number of queries, enabling identification of models that can only be accessed via an API or product. The fingerprints are non-invasive: our method does not require any changes to the model during training, hence by design, it does not impact model quality. Empirically, we find our method provides a high degree of robustness to common changes in the model or inference settings. In our experiments, it substantially outperforms prior art, including invasive methods that explicitly train watermarks into the model.