 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Optimal Online Egalitarian learning in General Sum Repeated Matrix Games
Jun 04, 2019
We study two-player general sum repeated finite games where the rewards of each player are generated from an unknown distribution. Our aim is to find the egalitarian bargaining solution (EBS) for the repeated game, which can lead to much higher rewards than the maximin value of both players. Our most important contribution is the derivation of an algorithm that achieves simultaneously, for both players, a high-probability regret bound of order $\mathcal{O}(\sqrt[3]{\ln T}\cdot T^{2/3})$ after any $T$ rounds of play. We demonstrate that our upper bound is nearly optimal by proving a lower bound of $\Omega(T^{2/3})$ for any algorithm.
Differential Privacy for Multi-armed Bandits: What Is It and What Is Its Cost?
May 29, 2019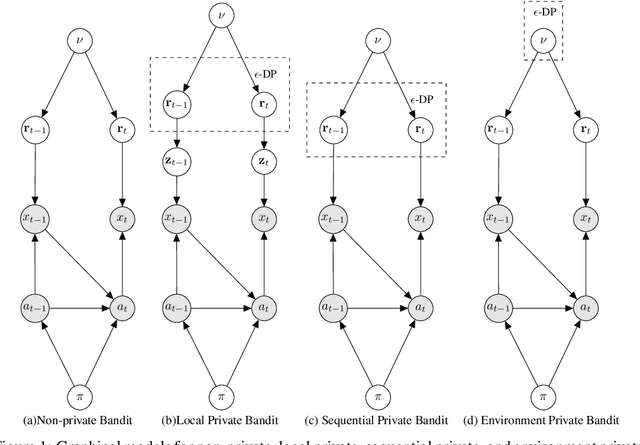
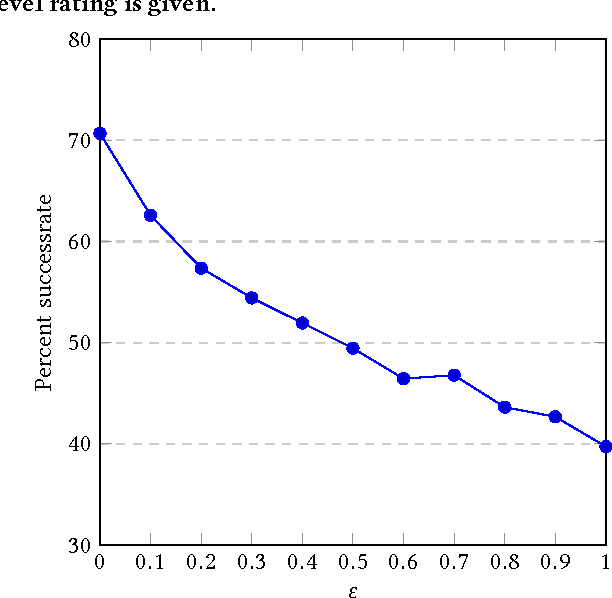
We introduce a number of privacy definitions for the multi-armed bandit problem, based on differential privacy. We relate them through a unifying graphical model representation and connect them to existing definitions. We then derive and contrast lower bounds on the regret of bandit algorithms satisfying these definitions. We show that for all of them, the learner's regret is increased by a multiplicative factor dependent on the privacy level $\epsilon$, but that the dependency is weaker when we do not require local differential privacy for the rewards.
Near-optimal Optimistic Reinforcement Learning using Empirical Bernstein Inequalities
May 27, 2019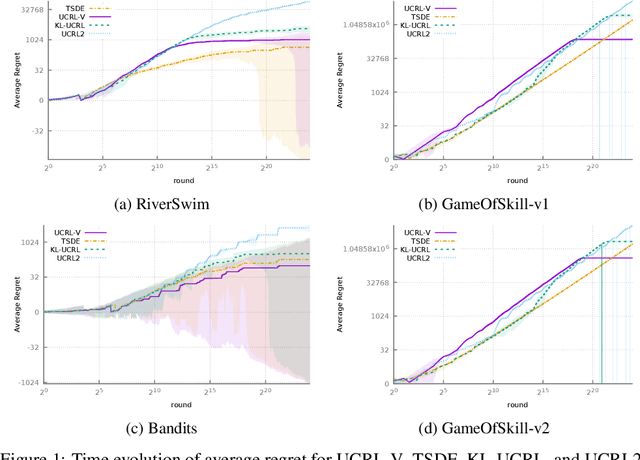

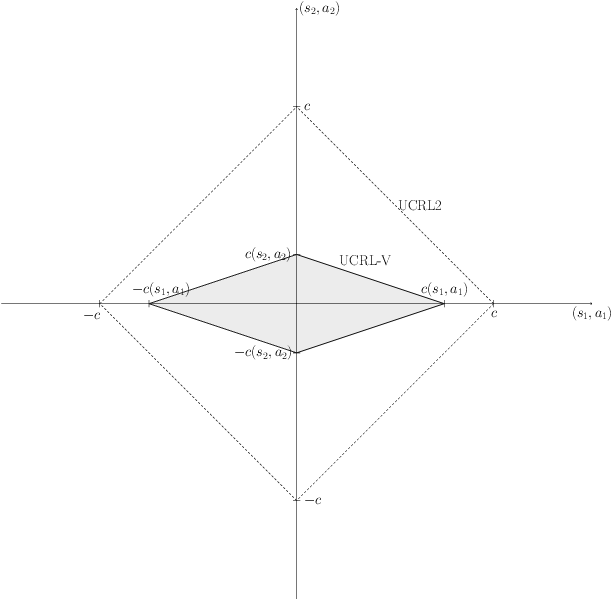
We study model-based reinforcement learning in an unknown finite communicating Markov decision process. We propose a simple algorithm that leverages a variance based confidence interval. We show that the proposed algorithm, UCRL-V, achieves the optimal regret $\tilde{\mathcal{O}}(\sqrt{DSAT})$ up to logarithmic factors, and so our work closes a gap with the lower bound without additional assumptions on the MDP. We perform experiments in a variety of environments that validates the theoretical bounds as well as prove UCRL-V to be better than the state-of-the-art algorithms.
Randomised Bayesian Least-Squares Policy Iteration
Apr 06, 2019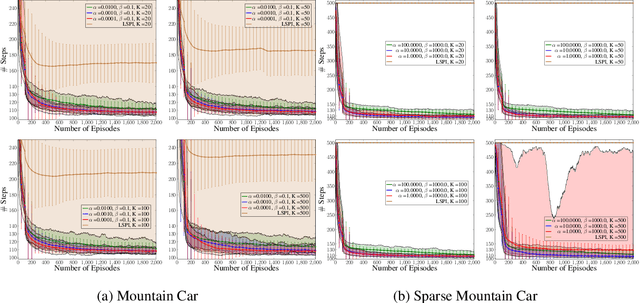
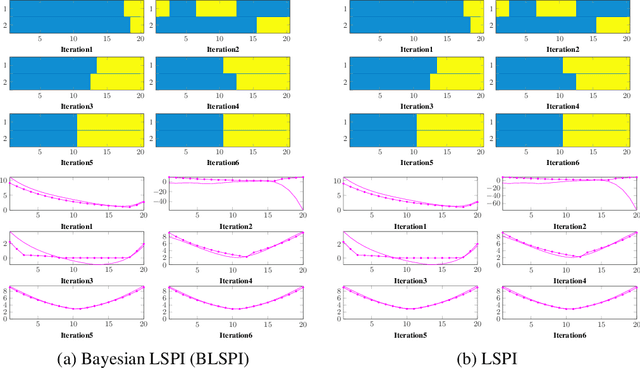
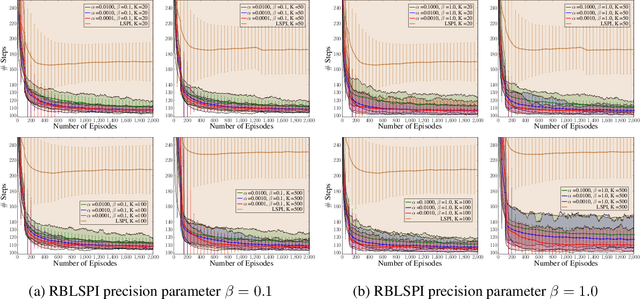
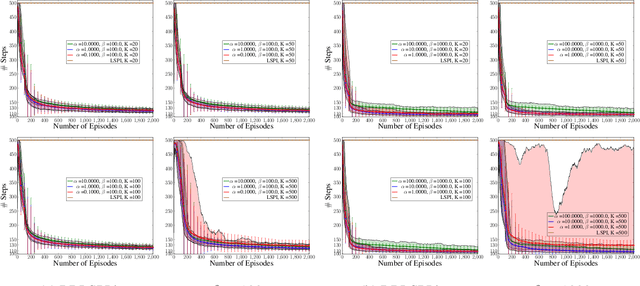
We introduce Bayesian least-squares policy iteration (BLSPI), an off-policy, model-free, policy iteration algorithm that uses the Bayesian least-squares temporal-difference (BLSTD) learning algorithm to evaluate policies. An online variant of BLSPI has been also proposed, called randomised BLSPI (RBLSPI), that improves its policy based on an incomplete policy evaluation step. In online setting, the exploration-exploitation dilemma should be addressed as we try to discover the optimal policy by using samples collected by ourselves. RBLSPI exploits the advantage of BLSTD to quantify our uncertainty about the value function. Inspired by Thompson sampling, RBLSPI first samples a value function from a posterior distribution over value functions, and then selects actions based on the sampled value function. The effectiveness and the exploration abilities of RBLSPI are demonstrated experimentally in several environments.
Deeper & Sparser Exploration
Feb 07, 2019

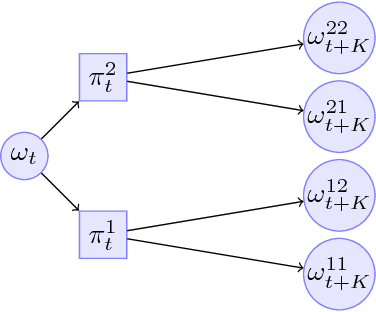
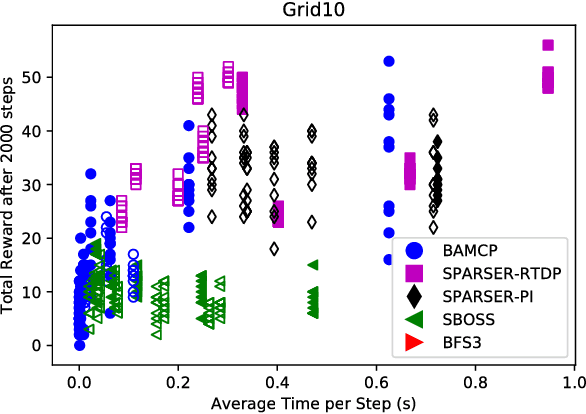
We address the problem of efficient exploration by proposing a new meta algorithm in the context of model-based online planning for Bayesian Reinforcement Learning (BRL). We beat the state-of-the-art, while staying computationally faster, in some cases by two orders of magnitude. This is the first Optimism free BRL algorithm to beat all previous state-of-the-art in tabular RL. The main novelty is the use of a candidate policy generator, to generate long-term options in the belief tree, which allows us to create much sparser and deeper trees. We present results on many standard environments and empirically prove its performance.
Bayesian fairness
Nov 04, 2018



We consider the problem of how decision making can be fair when the underlying probabilistic model of the world is not known with certainty. We argue that recent notions of fairness in machine learning need to explicitly incorporate parameter uncertainty, hence we introduce the notion of {\em Bayesian fairness} as a suitable candidate for fair decision rules. Using balance, a definition of fairness introduced by Kleinberg et al (2016), we show how a Bayesian perspective can lead to well-performing, fair decision rules even under high uncertainty.
On The Differential Privacy of Thompson Sampling With Gaussian Prior
Jun 24, 2018We show that Thompson Sampling with Gaussian Prior as detailed by Algorithm 2 in (Agrawal & Goyal, 2013) is already differentially private. Theorem 1 show that it enjoys a very competitive privacy loss of only $\mathcal{O}(\ln^2 T)$ after T rounds. Finally, Theorem 2 show that one can control the privacy loss to any desirable $\epsilon$ level by appropriately increasing the variance of the samples from the Gaussian posterior. And this increases the regret only by a term of $\mathcal{O}(\frac{\ln^2 T}{\epsilon})$. This compares favorably to the previous result for Thompson Sampling in the literature ((Mishra & Thakurta, 2015)) which adds a term of $\mathcal{O}(\frac{K \ln^3 T}{\epsilon^2})$ to the regret in order to achieve the same privacy level. Furthermore, our result use the basic Thompson Sampling with few modifications whereas the result of (Mishra & Thakurta, 2015) required sophisticated constructions.
Nearly optimal exploration-exploitation decision thresholds
Jun 04, 2018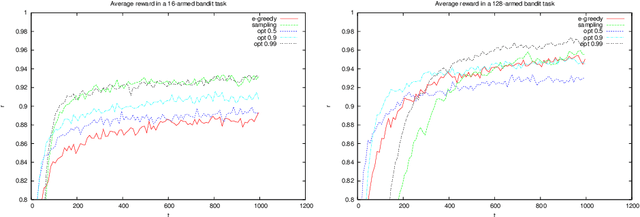
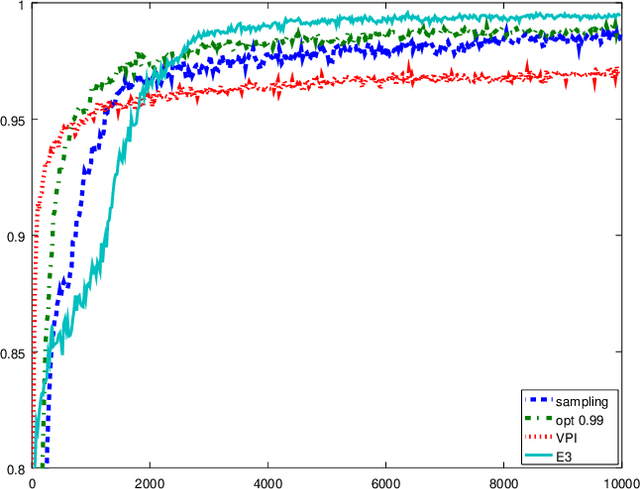
While in general trading off exploration and exploitation in reinforcement learning is hard, under some formulations relatively simple solutions exist. In this paper, we first derive upper bounds for the utility of selecting different actions in the multi-armed bandit setting. Unlike the common statistical upper confidence bounds, these explicitly link the planning horizon, uncertainty and the need for exploration explicit. The resulting algorithm can be seen as a generalisation of the classical Thompson sampling algorithm. We experimentally test these algorithms, as well as $\epsilon$-greedy and the value of perfect information heuristics. Finally, we also introduce the idea of bagging for reinforcement learning. By employing a version of online bootstrapping, we can efficiently sample from an approximate posterior distribution.
Learning to Match
Jul 30, 2017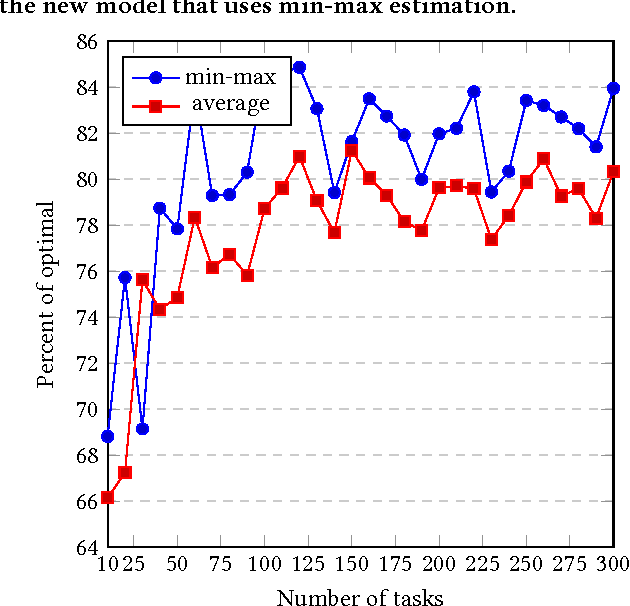

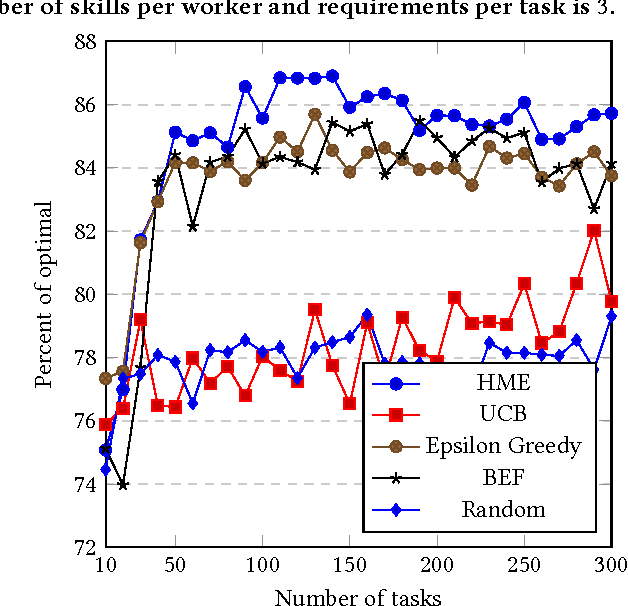
Outsourcing tasks to previously unknown parties is becoming more common. One specific such problem involves matching a set of workers to a set of tasks. Even if the latter have precise requirements, the quality of individual workers is usually unknown. The problem is thus a version of matching under uncertainty. We believe that this type of problem is going to be increasingly important. When the problem involves only a single skill or type of job, it is essentially a type of bandit problem, and can be solved with standard algorithms. However, we develop an algorithm that can perform matching for workers with multiple skills hired for multiple jobs with multiple requirements. We perform an experimental evaluation in both single-task and multi-task problems, comparing with the bounded $\epsilon$-first algorithm, as well as an oracle that knows the true skills of workers. One of the algorithms we developed gives results approaching 85\% of oracle's performance. We invite the community to take a closer look at this problem and develop real-world benchmarks.
Calibrated Fairness in Bandits
Jul 06, 2017We study fairness within the stochastic, \emph{multi-armed bandit} (MAB) decision making framework. We adapt the fairness framework of "treating similar individuals similarly" to this setting. Here, an `individual' corresponds to an arm and two arms are `similar' if they have a similar quality distribution. First, we adopt a {\em smoothness constraint} that if two arms have a similar quality distribution then the probability of selecting each arm should be similar. In addition, we define the {\em fairness regret}, which corresponds to the degree to which an algorithm is not calibrated, where perfect calibration requires that the probability of selecting an arm is equal to the probability with which the arm has the best quality realization. We show that a variation on Thompson sampling satisfies smooth fairness for total variation distance, and give an $\tilde{O}((kT)^{2/3})$ bound on fairness regret. This complements prior work, which protects an on-average better arm from being less favored. We also explain how to extend our algorithm to the dueling bandit setting.