 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn The Differential Privacy of Thompson Sampling With Gaussian Prior
Jun 24, 2018We show that Thompson Sampling with Gaussian Prior as detailed by Algorithm 2 in (Agrawal & Goyal, 2013) is already differentially private. Theorem 1 show that it enjoys a very competitive privacy loss of only $\mathcal{O}(\ln^2 T)$ after T rounds. Finally, Theorem 2 show that one can control the privacy loss to any desirable $\epsilon$ level by appropriately increasing the variance of the samples from the Gaussian posterior. And this increases the regret only by a term of $\mathcal{O}(\frac{\ln^2 T}{\epsilon})$. This compares favorably to the previous result for Thompson Sampling in the literature ((Mishra & Thakurta, 2015)) which adds a term of $\mathcal{O}(\frac{K \ln^3 T}{\epsilon^2})$ to the regret in order to achieve the same privacy level. Furthermore, our result use the basic Thompson Sampling with few modifications whereas the result of (Mishra & Thakurta, 2015) required sophisticated constructions.
Thompson Sampling For Stochastic Bandits with Graph Feedback
Jan 16, 2017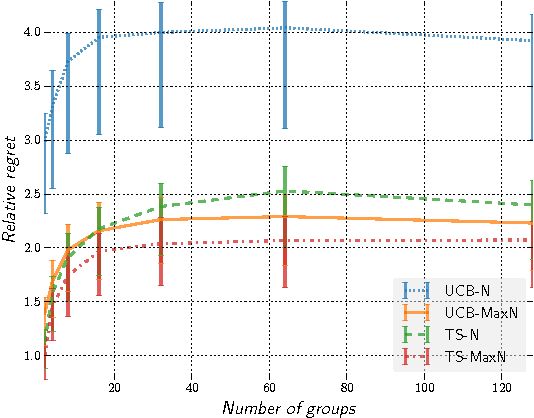
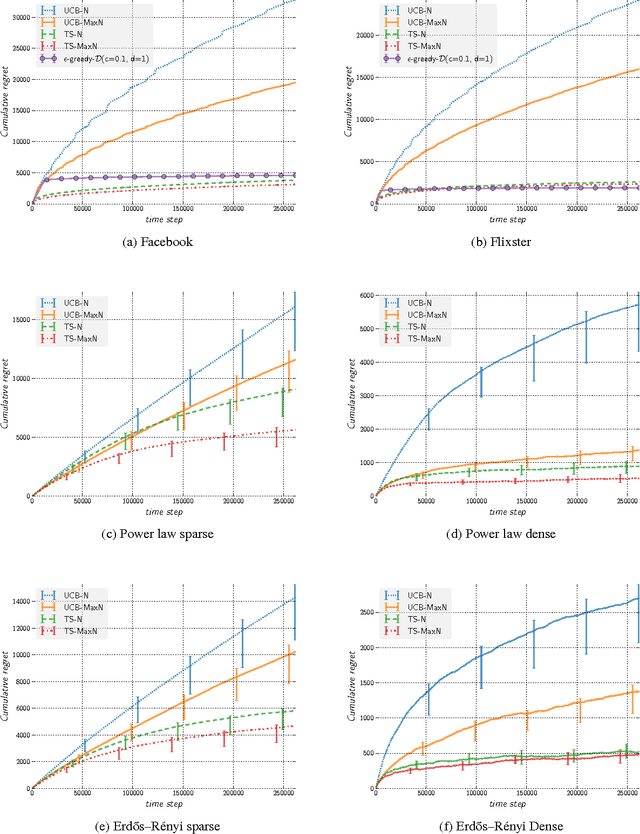
We present a novel extension of Thompson Sampling for stochastic sequential decision problems with graph feedback, even when the graph structure itself is unknown and/or changing. We provide theoretical guarantees on the Bayesian regret of the algorithm, linking its performance to the underlying properties of the graph. Thompson Sampling has the advantage of being applicable without the need to construct complicated upper confidence bounds for different problems. We illustrate its performance through extensive experimental results on real and simulated networks with graph feedback. More specifically, we tested our algorithms on power law, planted partitions and Erdo's-Renyi graphs, as well as on graphs derived from Facebook and Flixster data. These all show that our algorithms clearly outperform related methods that employ upper confidence bounds, even if the latter use more information about the graph.
Achieving Privacy in the Adversarial Multi-Armed Bandit
Jan 16, 2017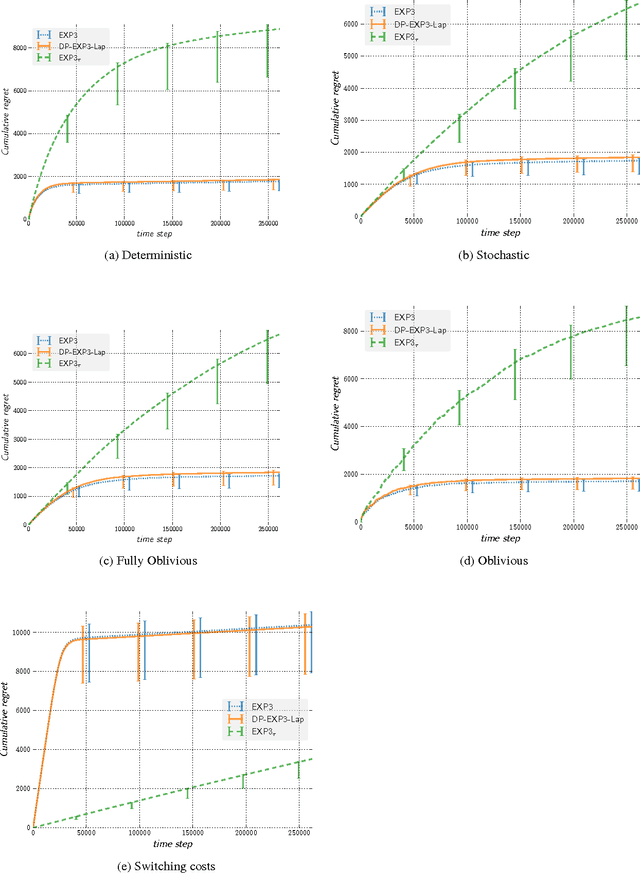
In this paper, we improve the previously best known regret bound to achieve $\epsilon$-differential privacy in oblivious adversarial bandits from $\mathcal{O}{(T^{2/3}/\epsilon)}$ to $\mathcal{O}{(\sqrt{T} \ln T /\epsilon)}$. This is achieved by combining a Laplace Mechanism with EXP3. We show that though EXP3 is already differentially private, it leaks a linear amount of information in $T$. However, we can improve this privacy by relying on its intrinsic exponential mechanism for selecting actions. This allows us to reach $\mathcal{O}{(\sqrt{\ln T})}$-DP, with a regret of $\mathcal{O}{(T^{2/3})}$ that holds against an adaptive adversary, an improvement from the best known of $\mathcal{O}{(T^{3/4})}$. This is done by using an algorithm that run EXP3 in a mini-batch loop. Finally, we run experiments that clearly demonstrate the validity of our theoretical analysis.