 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearly optimal exploration-exploitation decision thresholds
Paper and Code
Jun 04, 2018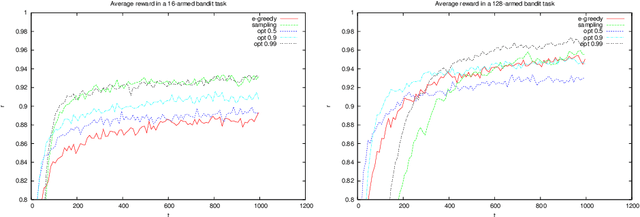
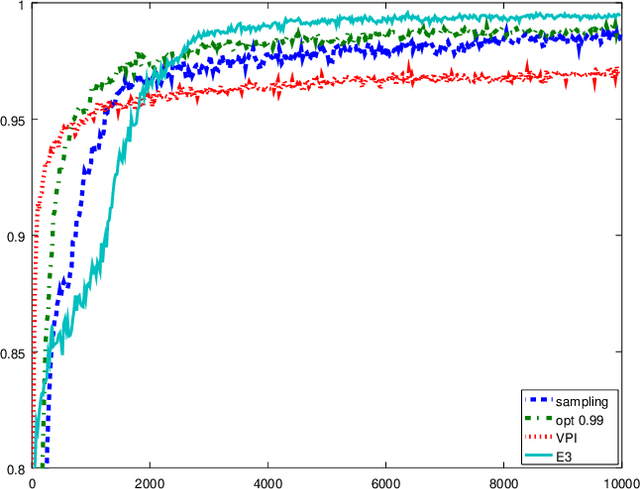
While in general trading off exploration and exploitation in reinforcement learning is hard, under some formulations relatively simple solutions exist. In this paper, we first derive upper bounds for the utility of selecting different actions in the multi-armed bandit setting. Unlike the common statistical upper confidence bounds, these explicitly link the planning horizon, uncertainty and the need for exploration explicit. The resulting algorithm can be seen as a generalisation of the classical Thompson sampling algorithm. We experimentally test these algorithms, as well as $\epsilon$-greedy and the value of perfect information heuristics. Finally, we also introduce the idea of bagging for reinforcement learning. By employing a version of online bootstrapping, we can efficiently sample from an approximate posterior distribution.