 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Train Your HiPPO: State Space Models with Generalized Orthogonal Basis Projections
Jun 24, 2022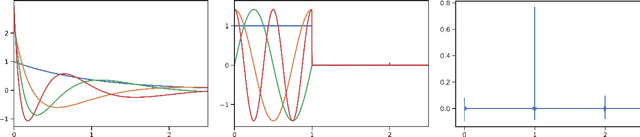

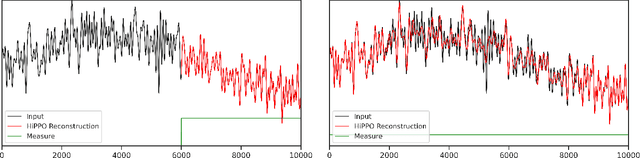

Linear time-invariant state space models (SSM) are a classical model from engineering and statistics, that have recently been shown to be very promising in machine learning through the Structured State Space sequence model (S4). A core component of S4 involves initializing the SSM state matrix to a particular matrix called a HiPPO matrix, which was empirically important for S4's ability to handle long sequences. However, the specific matrix that S4 uses was actually derived in previous work for a particular time-varying dynamical system, and the use of this matrix as a time-invariant SSM had no known mathematical interpretation. Consequently, the theoretical mechanism by which S4 models long-range dependencies actually remains unexplained. We derive a more general and intuitive formulation of the HiPPO framework, which provides a simple mathematical interpretation of S4 as a decomposition onto exponentially-warped Legendre polynomials, explaining its ability to capture long dependencies. Our generalization introduces a theoretically rich class of SSMs that also lets us derive more intuitive S4 variants for other bases such as the Fourier basis, and explains other aspects of training S4, such as how to initialize the important timescale parameter. These insights improve S4's performance to 86% on the Long Range Arena benchmark, with 96% on the most difficult Path-X task.
On the Parameterization and Initialization of Diagonal State Space Models
Jun 23, 2022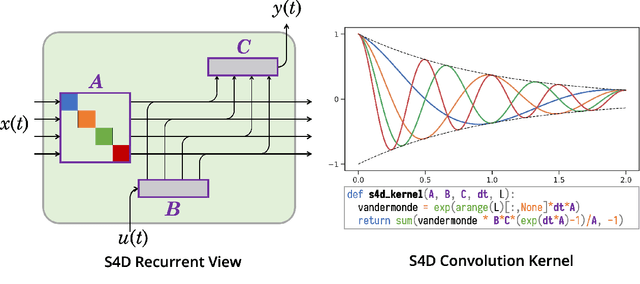

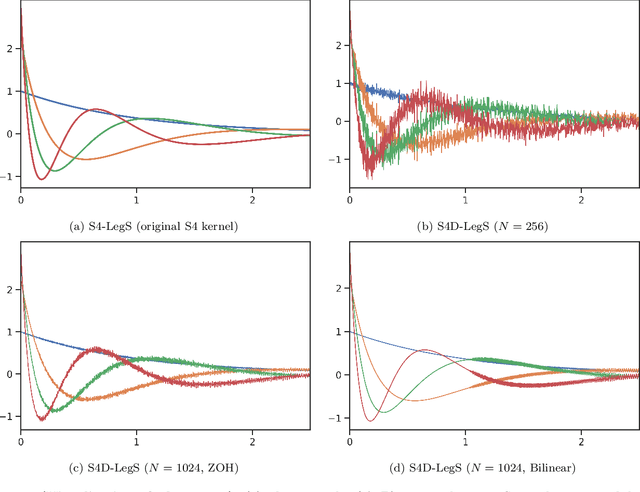

State space models (SSM) have recently been shown to be very effective as a deep learning layer as a promising alternative to sequence models such as RNNs, CNNs, or Transformers. The first version to show this potential was the S4 model, which is particularly effective on tasks involving long-range dependencies by using a prescribed state matrix called the HiPPO matrix. While this has an interpretable mathematical mechanism for modeling long dependencies, it introduces a custom representation and algorithm that can be difficult to implement. On the other hand, a recent variant of S4 called DSS showed that restricting the state matrix to be fully diagonal can still preserve the performance of the original model when using a specific initialization based on approximating S4's matrix. This work seeks to systematically understand how to parameterize and initialize such diagonal state space models. While it follows from classical results that almost all SSMs have an equivalent diagonal form, we show that the initialization is critical for performance. We explain why DSS works mathematically, by showing that the diagonal restriction of S4's matrix surprisingly recovers the same kernel in the limit of infinite state dimension. We also systematically describe various design choices in parameterizing and computing diagonal SSMs, and perform a controlled empirical study ablating the effects of these choices. Our final model S4D is a simple diagonal version of S4 whose kernel computation requires just 2 lines of code and performs comparably to S4 in almost all settings, with state-of-the-art results for image, audio, and medical time-series domains, and averaging 85\% on the Long Range Arena benchmark.
The Importance of Background Information for Out of Distribution Generalization
Jun 17, 2022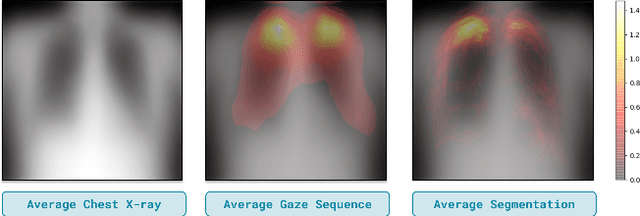
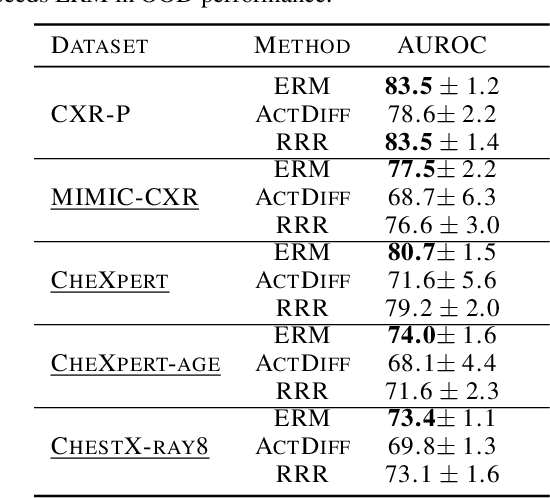

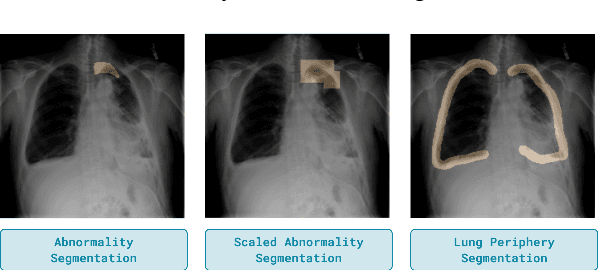
Domain generalization in medical image classification is an important problem for trustworthy machine learning to be deployed in healthcare. We find that existing approaches for domain generalization which utilize ground-truth abnormality segmentations to control feature attributions have poor out-of-distribution (OOD) performance relative to the standard baseline of empirical risk minimization (ERM). We investigate what regions of an image are important for medical image classification and show that parts of the background, that which is not contained in the abnormality segmentation, provides helpful signal. We then develop a new task-specific mask which covers all relevant regions. Utilizing this new segmentation mask significantly improves the performance of the existing methods on the OOD test sets. To obtain better generalization results than ERM, we find it necessary to scale up the training data size in addition to the usage of these task-specific masks.
Comparing interpretation methods in mental state decoding analyses with deep learning models
May 31, 2022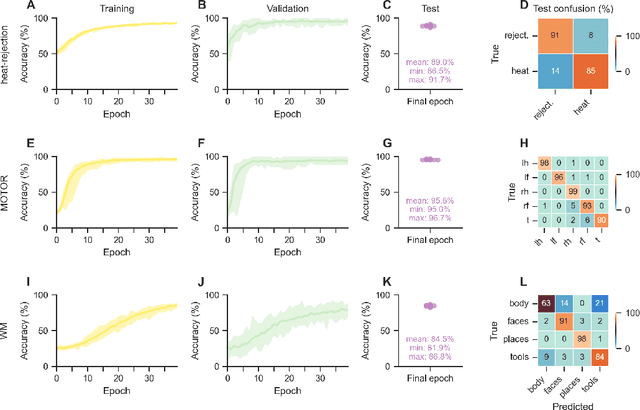
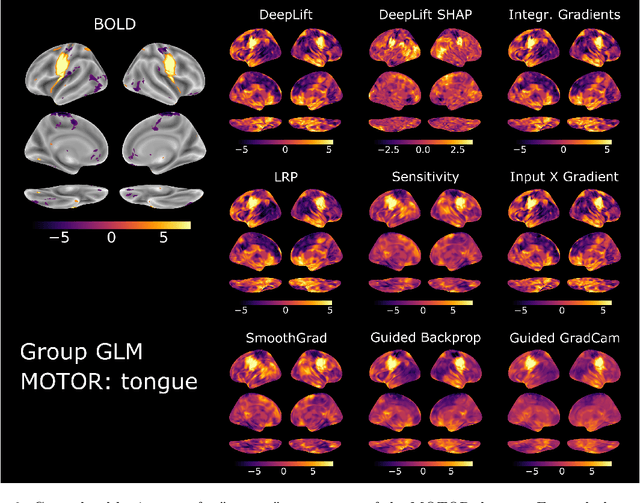
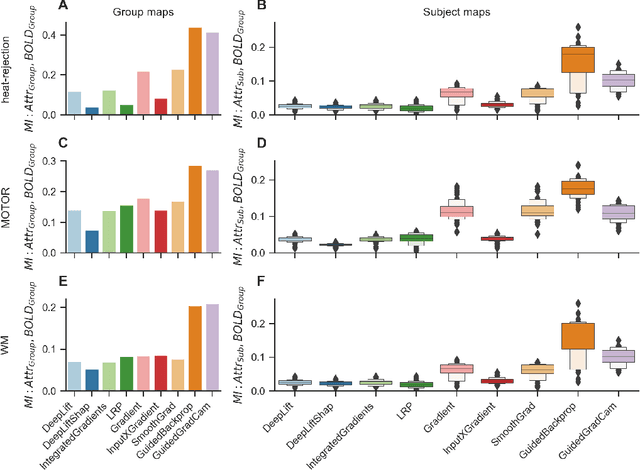
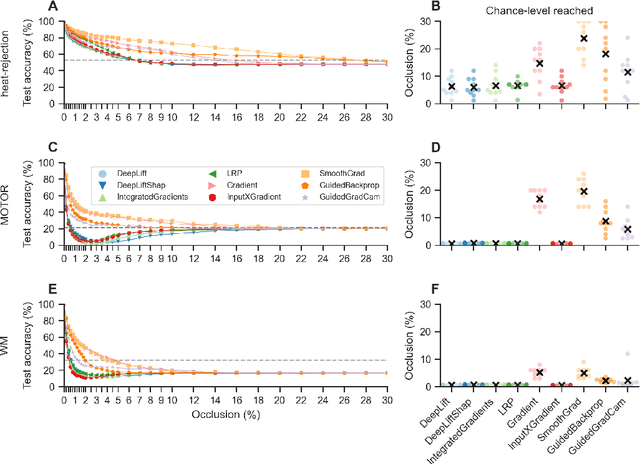
Deep learning (DL) methods find increasing application in mental state decoding, where researchers seek to understand the mapping between mental states (such as accepting or rejecting a gamble) and brain activity, by identifying those brain regions (and networks) whose activity allows to accurately identify (i.e., decode) these states. Once DL models have been trained to accurately decode a set of mental states, neuroimaging researchers often make use of interpretation methods from explainable artificial intelligence research to understand their learned mappings between mental states and brain activity. Here, we compare the explanations of prominent interpretation methods for the mental state decoding decisions of DL models trained on three functional Magnetic Resonance Imaging (fMRI) datasets. We find that interpretation methods that capture the model's decision process well, by producing faithful explanations, generally produce explanations that are less in line with the results of standard analyses of the fMRI data, when compared to the explanations of interpretation methods with less explanation faithfulness. Specifically, we find that interpretation methods that focus on how sensitively a model's decoding decision changes with the values of the input produce explanations that better match with the results of a standard general linear model analysis of the fMRI data, while interpretation methods that focus on identifying the specific contribution of an input feature's value to the decoding decision produce overall more faithful explanations that align less well with the results of standard analyses of the fMRI data.
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
May 27, 2022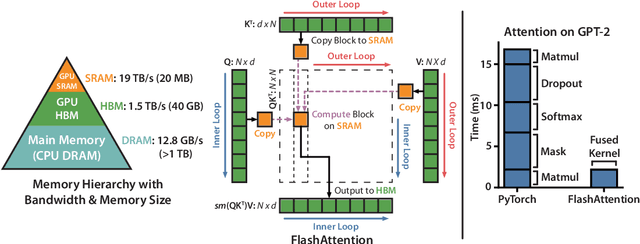

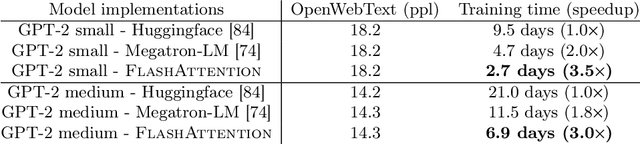
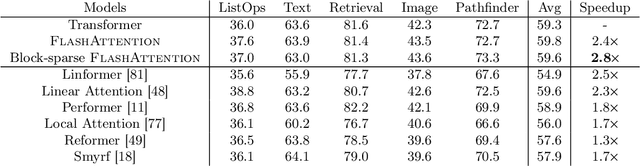
Transformers are slow and memory-hungry on long sequences, since the time and memory complexity of self-attention are quadratic in sequence length. Approximate attention methods have attempted to address this problem by trading off model quality to reduce the compute complexity, but often do not achieve wall-clock speedup. We argue that a missing principle is making attention algorithms IO-aware -- accounting for reads and writes between levels of GPU memory. We propose FlashAttention, an IO-aware exact attention algorithm that uses tiling to reduce the number of memory reads/writes between GPU high bandwidth memory (HBM) and GPU on-chip SRAM. We analyze the IO complexity of FlashAttention, showing that it requires fewer HBM accesses than standard attention, and is optimal for a range of SRAM sizes. We also extend FlashAttention to block-sparse attention, yielding an approximate attention algorithm that is faster than any existing approximate attention method. FlashAttention trains Transformers faster than existing baselines: 15% end-to-end wall-clock speedup on BERT-large (seq. length 512) compared to the MLPerf 1.1 training speed record, 3$\times$ speedup on GPT-2 (seq. length 1K), and 2.4$\times$ speedup on long-range arena (seq. length 1K-4K). FlashAttention and block-sparse FlashAttention enable longer context in Transformers, yielding higher quality models (0.7 better perplexity on GPT-2 and 6.4 points of lift on long-document classification) and entirely new capabilities: the first Transformers to achieve better-than-chance performance on the Path-X challenge (seq. length 16K, 61.4% accuracy) and Path-256 (seq. length 64K, 63.1% accuracy).
Can Foundation Models Help Us Achieve Perfect Secrecy?
May 27, 2022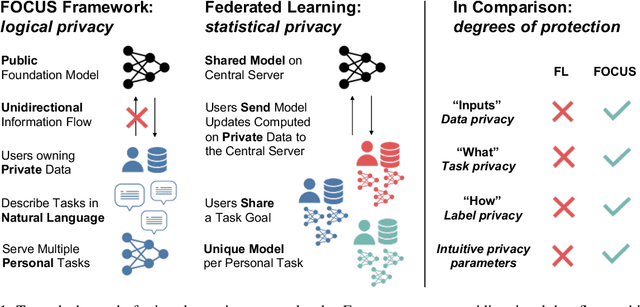
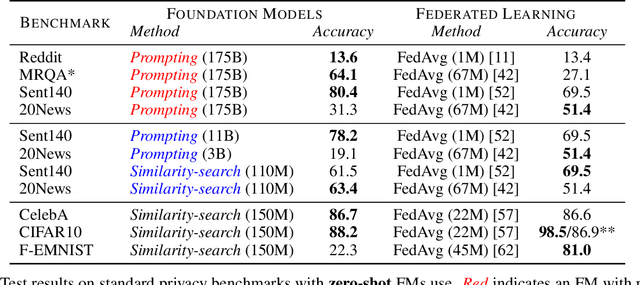
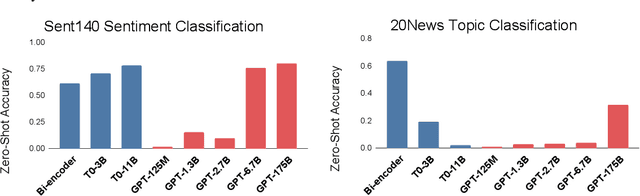

A key promise of machine learning is the ability to assist users with personal tasks. Because the personal context required to make accurate predictions is often sensitive, we require systems that protect privacy. A gold standard privacy-preserving system will satisfy perfect secrecy, meaning that interactions with the system provably reveal no additional private information to adversaries. This guarantee should hold even as we perform multiple personal tasks over the same underlying data. However, privacy and quality appear to be in tension in existing systems for personal tasks. Neural models typically require lots of training to perform well, while individual users typically hold a limited scale of data, so the systems propose to learn from the aggregate data of multiple users. This violates perfect secrecy and instead, in the last few years, academics have defended these solutions using statistical notions of privacy -- i.e., the probability of learning private information about a user should be reasonably low. Given the vulnerabilities of these solutions, we explore whether the strong perfect secrecy guarantee can be achieved using recent zero-to-few sample adaptation techniques enabled by foundation models. In response, we propose FOCUS, a framework for personal tasks. Evaluating on popular privacy benchmarks, we find the approach, satisfying perfect secrecy, competes with strong collaborative learning baselines on 6 of 7 tasks. We empirically analyze the proposal, highlighting the opportunities and limitations across task types, and model inductive biases and sizes.
Can Foundation Models Wrangle Your Data?
May 20, 2022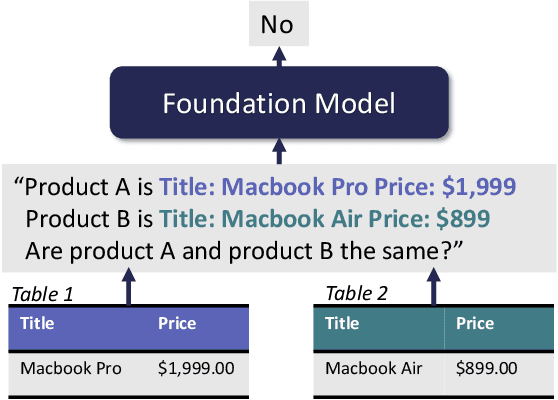
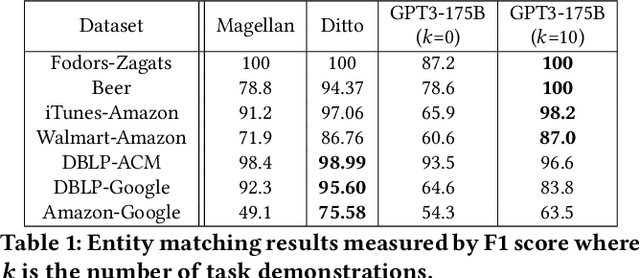
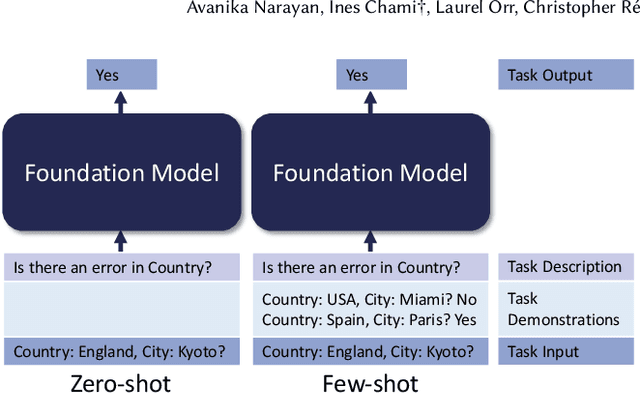
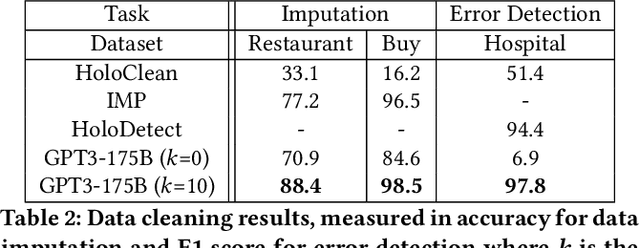
Foundation Models (FMs) are models trained on large corpora of data that, at very large scale, can generalize to new tasks without any task-specific finetuning. As these models continue to grow in size, innovations continue to push the boundaries of what these models can do on language and image tasks. This paper aims to understand an underexplored area of FMs: classical data tasks like cleaning and integration. As a proof-of-concept, we cast three data cleaning and integration tasks as prompting tasks and evaluate the performance of FMs on these tasks. We find that large FMs generalize and achieve SoTA performance on data cleaning and integration tasks, even though they are not trained for these data tasks. We identify specific research challenges and opportunities that these models present, including challenges with private and temporal data, and opportunities to make data driven systems more accessible to non-experts. We make our code and experiments publicly available at: https://github.com/HazyResearch/fm_data_tasks.
TABi: Type-Aware Bi-Encoders for Open-Domain Entity Retrieval
Apr 18, 2022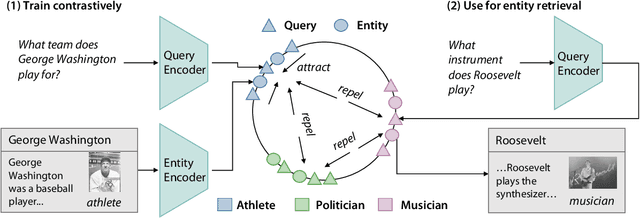
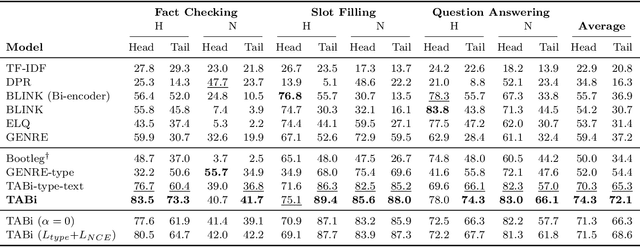

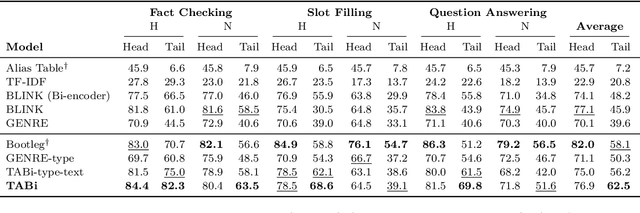
Entity retrieval--retrieving information about entity mentions in a query--is a key step in open-domain tasks, such as question answering or fact checking. However, state-of-the-art entity retrievers struggle to retrieve rare entities for ambiguous mentions due to biases towards popular entities. Incorporating knowledge graph types during training could help overcome popularity biases, but there are several challenges: (1) existing type-based retrieval methods require mention boundaries as input, but open-domain tasks run on unstructured text, (2) type-based methods should not compromise overall performance, and (3) type-based methods should be robust to noisy and missing types. In this work, we introduce TABi, a method to jointly train bi-encoders on knowledge graph types and unstructured text for entity retrieval for open-domain tasks. TABi leverages a type-enforced contrastive loss to encourage entities and queries of similar types to be close in the embedding space. TABi improves retrieval of rare entities on the Ambiguous Entity Retrieval (AmbER) sets, while maintaining strong overall retrieval performance on open-domain tasks in the KILT benchmark compared to state-of-the-art retrievers. TABi is also robust to incomplete type systems, improving rare entity retrieval over baselines with only 5% type coverage of the training dataset. We make our code publicly available at https://github.com/HazyResearch/tabi.
Perfectly Balanced: Improving Transfer and Robustness of Supervised Contrastive Learning
Apr 15, 2022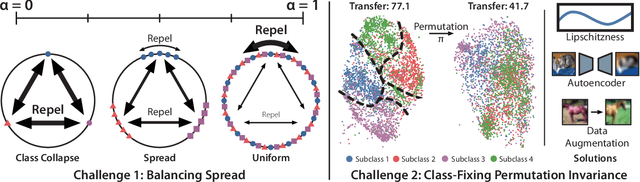

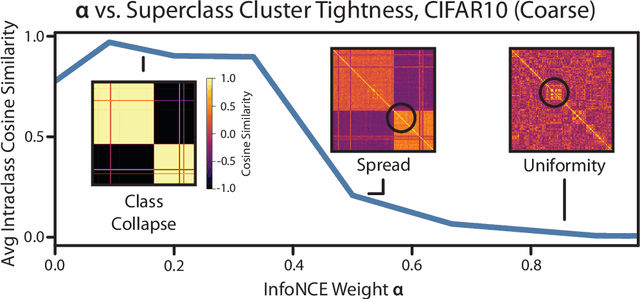
An ideal learned representation should display transferability and robustness. Supervised contrastive learning (SupCon) is a promising method for training accurate models, but produces representations that do not capture these properties due to class collapse -- when all points in a class map to the same representation. Recent work suggests that "spreading out" these representations improves them, but the precise mechanism is poorly understood. We argue that creating spread alone is insufficient for better representations, since spread is invariant to permutations within classes. Instead, both the correct degree of spread and a mechanism for breaking this invariance are necessary. We first prove that adding a weighted class-conditional InfoNCE loss to SupCon controls the degree of spread. Next, we study three mechanisms to break permutation invariance: using a constrained encoder, adding a class-conditional autoencoder, and using data augmentation. We show that the latter two encourage clustering of latent subclasses under more realistic conditions than the former. Using these insights, we show that adding a properly-weighted class-conditional InfoNCE loss and a class-conditional autoencoder to SupCon achieves 11.1 points of lift on coarse-to-fine transfer across 5 standard datasets and 4.7 points on worst-group robustness on 3 datasets, setting state-of-the-art on CelebA by 11.5 points.
Domino: Discovering Systematic Errors with Cross-Modal Embeddings
Apr 11, 2022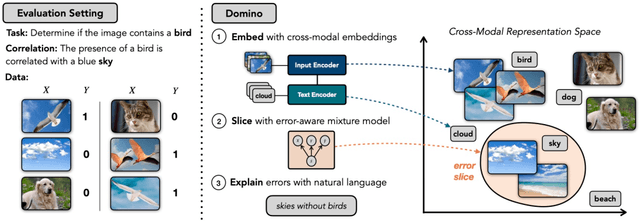
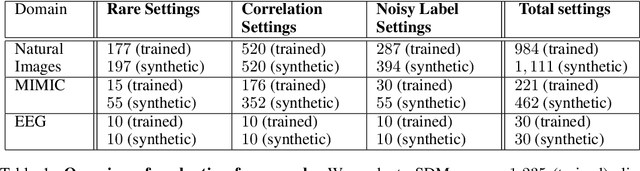
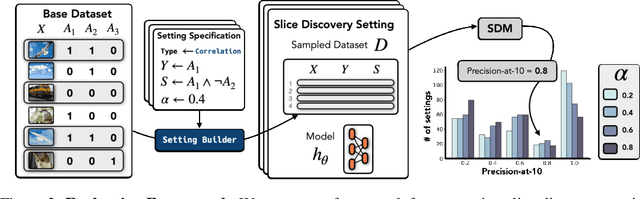
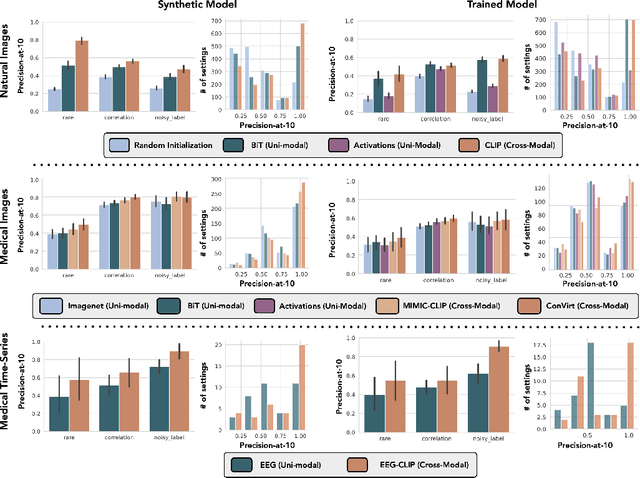
Machine learning models that achieve high overall accuracy often make systematic errors on important subsets (or slices) of data. Identifying underperforming slices is particularly challenging when working with high-dimensional inputs (e.g. images, audio), where important slices are often unlabeled. In order to address this issue, recent studies have proposed automated slice discovery methods (SDMs), which leverage learned model representations to mine input data for slices on which a model performs poorly. To be useful to a practitioner, these methods must identify slices that are both underperforming and coherent (i.e. united by a human-understandable concept). However, no quantitative evaluation framework currently exists for rigorously assessing SDMs with respect to these criteria. Additionally, prior qualitative evaluations have shown that SDMs often identify slices that are incoherent. In this work, we address these challenges by first designing a principled evaluation framework that enables a quantitative comparison of SDMs across 1,235 slice discovery settings in three input domains (natural images, medical images, and time-series data). Then, motivated by the recent development of powerful cross-modal representation learning approaches, we present Domino, an SDM that leverages cross-modal embeddings and a novel error-aware mixture model to discover and describe coherent slices. We find that Domino accurately identifies 36% of the 1,235 slices in our framework - a 12 percentage point improvement over prior methods. Further, Domino is the first SDM that can provide natural language descriptions of identified slices, correctly generating the exact name of the slice in 35% of settings.