 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe S-ICDF Dataset: Sionna-Simulated Dynamic Interference Characterization and Direction Finding
Jul 03, 2026Jamming and spoofing threaten wireless and satellite navigation by disrupting or manipulating radio frequency (RF) signals, undermining availability, integrity, and trust. Robust interference monitoring (i.e., detection, classification, characterization, and direction finding) is therefore essential to identify and localize anomalous signals. While machine learning (ML) promises improved performance in complex environments, its development and validation depend on large-scale datasets that capture realistic signal and channel variability. Collecting such data in the real world is difficult because intentional jamming is illegal and ground-truth attribution is confounded by propagation, hardware, and environmental effects. To address this gap, we create and publish S-ICDF, a large-scale indoor interference dataset generated with Sionna, a GPU-accelerated simulation library for physical-layer wireless communications. S-ICDF covers 102 interference configurations, including diverse antenna array patterns, bandwidths, and simulation settings such as noise level and reflection depth. We further provide baseline results by benchmarking S-ICDF with classical estimation and direction finding (DF) methods (MUSIC, ESPRIT, and CAPON) and with modern ML approaches. The dataset is publicly available at: https://gitlab.cc-asp.fraunhofer.de/darcy_gnss/sicdf_dataset
Exploitation of Hidden Context in Dynamic Movement Forecasting: A Neural Network Journey from Recurrent to Graph Neural Networks and General Purpose Transformers
May 14, 2026Forecasting within signal processing pipelines is crucial for mitigating delays, particularly in predicting the dynamic movements of objects such as NBA players. This task poses significant challenges due to the inherently interactive and unpredictable nature of sports, where abrupt changes in velocity and direction are prevalent. Traditional approaches, including (S)ARIMA(X), Kalman filters (KF), and Particle filters (PF), often struggle to model the non-linear dynamics present in such scenarios. Machine learning (ML) methods, such as long short-term memory (LSTM) networks, graph neural networks (GNNs), and Transformers, offer greater flexibility and accuracy but frequently fail to explicitly capture the interplay between temporal dependencies and contextual interactions, which are critical in chaotic sports environments. In this paper, we evaluate these models and assess their strengths and weaknesses. Experimental results reveal key performance trade-offs across input history length, generalizability, and the ability to incorporate contextual information. ML-based methods demonstrated substantial improvements over linear models across forecast horizons of up to 2s. Among the tested architectures, our hybrid LSTM augmented with contextual information achieved the lowest final displacement error (FDE) of 1.51m, outperforming temporal convolutional neural network (TCNN), graph attention network (GAT), and Transformers, while also requiring less data and training time compared to GAT and Transformers. Our findings indicate that no single architecture excels across all metrics, emphasizing the need for task-specific considerations in trajectory prediction for fast-paced, dynamic environments such as NBA gameplay.
* 12 pages
Resilient Channel Charting Under Varying Radio Link Availability
Feb 04, 2026Channel charting (CC) has become a key technology for RF-based localization, enabling unsupervised radio fingerprinting, even in non line of sight scenarios, with a minimum of reference position labels. However, most CC models assume fixed-size inputs, such as a constant number of antennas or channel measurements. In practical systems, antennas may fail, signals may be blocked, or antenna sets may change during handovers, making fixed-input architectures fragile. Existing radio-fingerprinting approaches address this by training separate models for each antenna configuration, but the resulting training effort scales prohibitively with the array size. We propose Adaptive Positioning (AdaPos), a CC architecture that natively handles variable numbers of channel measurements. AdaPos combines convolutional feature extraction with a transformer-based encoder using learnable antenna identifiers and self-attention to fuse arbitrary subsets of CSI inputs. Experiments on two public real-world datasets (SISO and MIMO) show that AdaPos maintains state-of-the-art accuracy under missing-antenna conditions and replaces roughly 57 configuration-specific models with a single unified model. With AdaPos and our novel training strategies, we provide resilience to both individual antenna failures and full-array outages.
Simplicity is Key: An Unsupervised Pretraining Approach for Sparse Radio Channels
May 19, 2025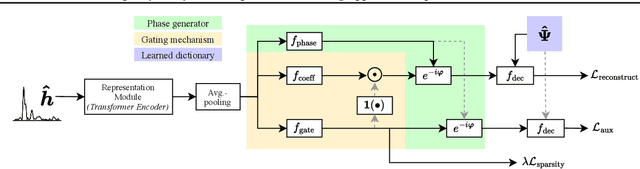

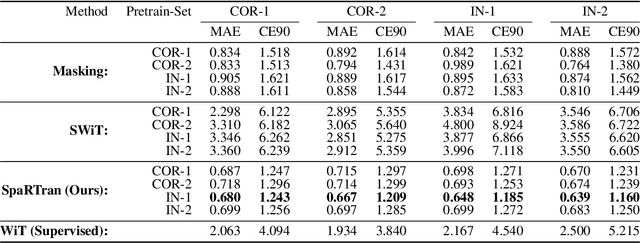
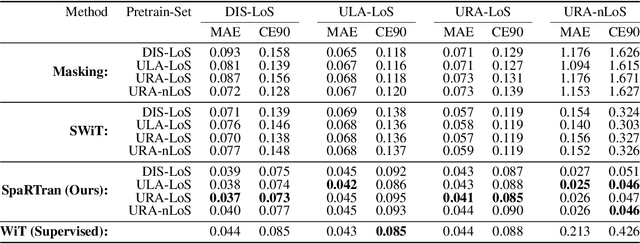
We introduce the Sparse pretrained Radio Transformer (SpaRTran), an unsupervised representation learning approach based on the concept of compressed sensing for radio channels. Our approach learns embeddings that focus on the physical properties of radio propagation, to create the optimal basis for fine-tuning on radio-based downstream tasks. SpaRTran uses a sparse gated autoencoder that induces a simplicity bias to the learned representations, resembling the sparse nature of radio propagation. For signal reconstruction, it learns a dictionary that holds atomic features, which increases flexibility across signal waveforms and spatiotemporal signal patterns. Our experiments show that SpaRTran reduces errors by up to 85 % compared to state-of-the-art methods when fine-tuned on radio fingerprinting, a challenging downstream task. In addition, our method requires less pretraining effort and offers greater flexibility, as we train it solely on individual radio signals. SpaRTran serves as an excellent base model that can be fine-tuned for various radio-based downstream tasks, effectively reducing the cost for labeling. In addition, it is significantly more versatile than existing methods and demonstrates superior generalization.
Radio Foundation Models: Pre-training Transformers for 5G-based Indoor Localization
Oct 01, 2024Artificial Intelligence (AI)-based radio fingerprinting (FP) outperforms classic localization methods in propagation environments with strong multipath effects. However, the model and data orchestration of FP are time-consuming and costly, as it requires many reference positions and extensive measurement campaigns for each environment. Instead, modern unsupervised and self-supervised learning schemes require less reference data for localization, but either their accuracy is low or they require additional sensor information, rendering them impractical. In this paper we propose a self-supervised learning framework that pre-trains a general transformer (TF) neural network on 5G channel measurements that we collect on-the-fly without expensive equipment. Our novel pretext task randomly masks and drops input information to learn to reconstruct it. So, it implicitly learns the spatiotemporal patterns and information of the propagation environment that enable FP-based localization. Most interestingly, when we optimize this pre-trained model for localization in a given environment, it achieves the accuracy of state-of-the-art methods but requires ten times less reference data and significantly reduces the time from training to operation.