 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvalanche: an End-to-End Library for Continual Learning
Apr 01, 2021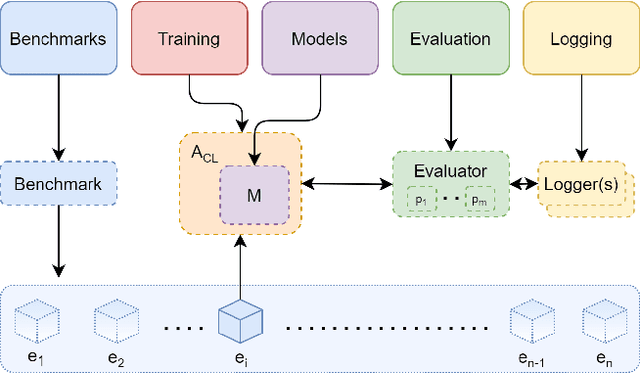

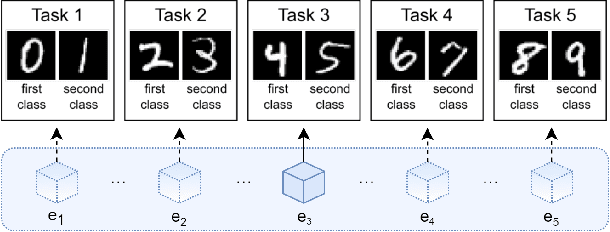

Learning continually from non-stationary data streams is a long-standing goal and a challenging problem in machine learning. Recently, we have witnessed a renewed and fast-growing interest in continual learning, especially within the deep learning community. However, algorithmic solutions are often difficult to re-implement, evaluate and port across different settings, where even results on standard benchmarks are hard to reproduce. In this work, we propose Avalanche, an open-source end-to-end library for continual learning research based on PyTorch. Avalanche is designed to provide a shared and collaborative codebase for fast prototyping, training, and reproducible evaluation of continual learning algorithms.
An Investigation of Critical Issues in Bias Mitigation Techniques
Apr 01, 2021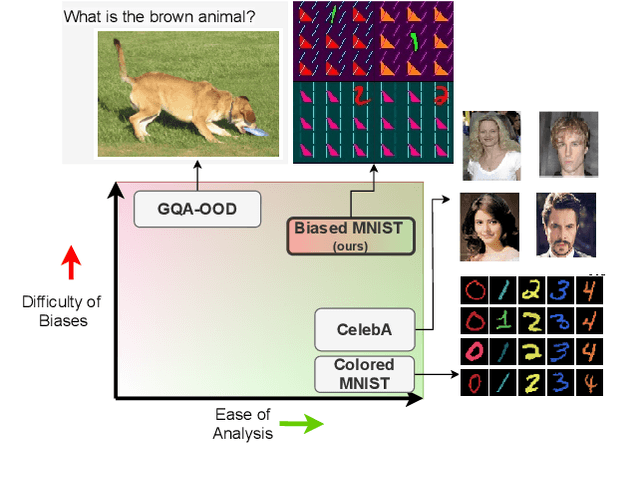
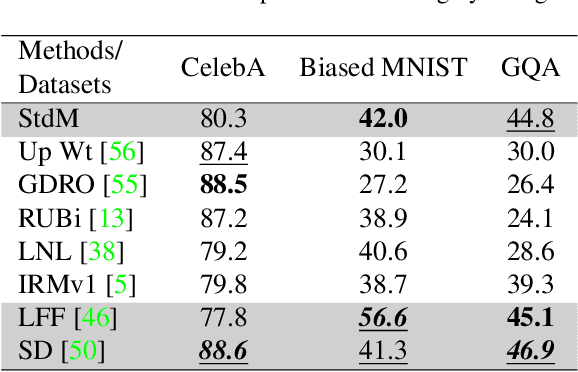
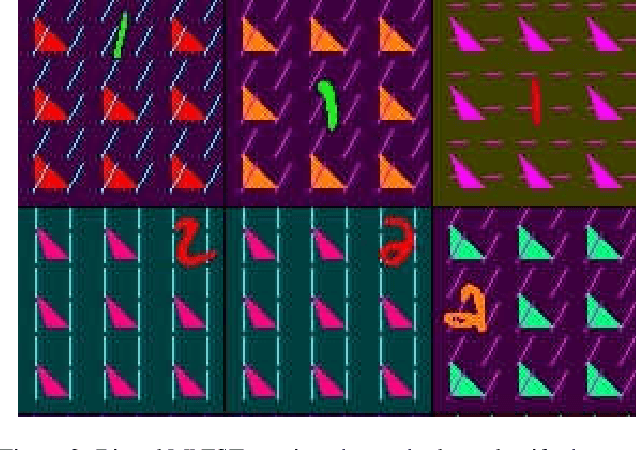
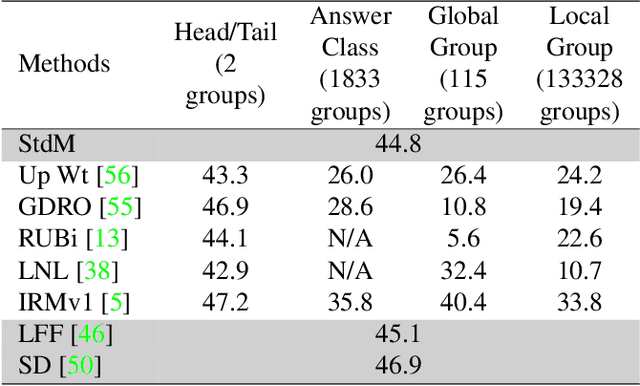
A critical problem in deep learning is that systems learn inappropriate biases, resulting in their inability to perform well on minority groups. This has led to the creation of multiple algorithms that endeavor to mitigate bias. However, it is not clear how effective these methods are. This is because study protocols differ among papers, systems are tested on datasets that fail to test many forms of bias, and systems have access to hidden knowledge or are tuned specifically to the test set. To address this, we introduce an improved evaluation protocol, sensible metrics, and a new dataset, which enables us to ask and answer critical questions about bias mitigation algorithms. We evaluate seven state-of-the-art algorithms using the same network architecture and hyperparameter selection policy across three benchmark datasets. We introduce a new dataset called Biased MNIST that enables assessment of robustness to multiple bias sources. We use Biased MNIST and a visual question answering (VQA) benchmark to assess robustness to hidden biases. Rather than only tuning to the test set distribution, we study robustness across different tuning distributions, which is critical because for many applications the test distribution may not be known during development. We find that algorithms exploit hidden biases, are unable to scale to multiple forms of bias, and are highly sensitive to the choice of tuning set. Based on our findings, we implore the community to adopt more rigorous assessment of future bias mitigation methods. All data, code, and results are publicly available at: https://github.com/erobic/bias-mitigators.
Self-Supervised Training Enhances Online Continual Learning
Mar 25, 2021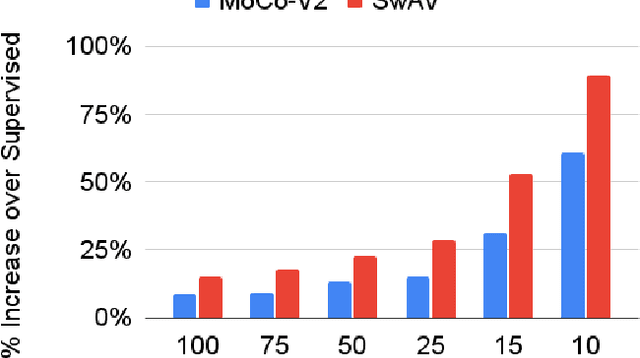
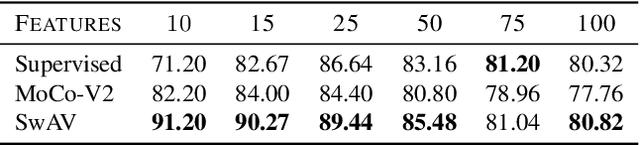
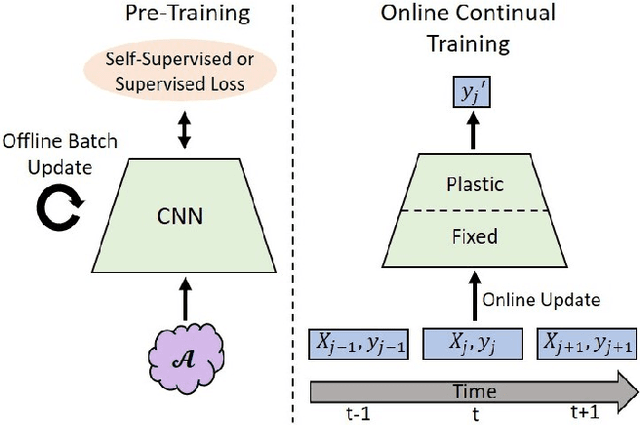
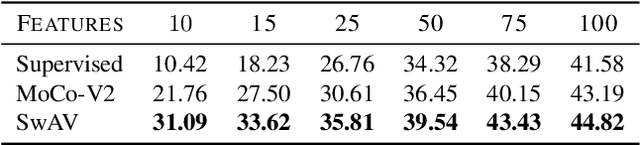
In continual learning, a system must incrementally learn from a non-stationary data stream without catastrophic forgetting. Recently, multiple methods have been devised for incrementally learning classes on large-scale image classification tasks, such as ImageNet. State-of-the-art continual learning methods use an initial supervised pre-training phase, in which the first 10% - 50% of the classes in a dataset are used to learn representations in an offline manner before continual learning of new classes begins. We hypothesize that self-supervised pre-training could yield features that generalize better than supervised learning, especially when the number of samples used for pre-training is small. We test this hypothesis using the self-supervised MoCo-V2 and SwAV algorithms. On ImageNet, we find that both outperform supervised pre-training considerably for online continual learning, and the gains are larger when fewer samples are available. Our findings are consistent across three continual learning algorithms. Our best system achieves a 14.95% relative increase in top-1 accuracy on class incremental ImageNet over the prior state of the art for online continual learning.
Selective Replay Enhances Learning in Online Continual Analogical Reasoning
Mar 06, 2021
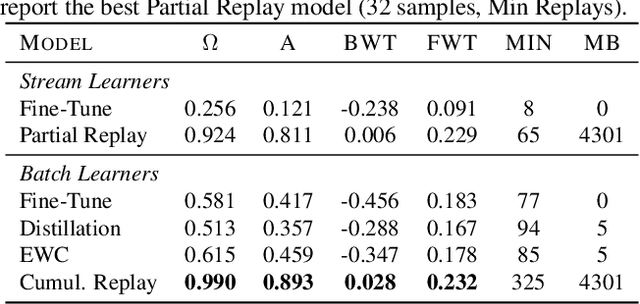

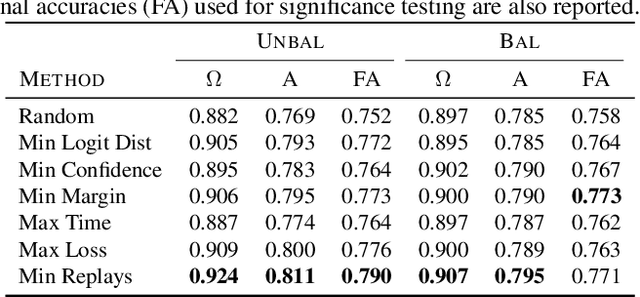
In continual learning, a system learns from non-stationary data streams or batches without catastrophic forgetting. While this problem has been heavily studied in supervised image classification and reinforcement learning, continual learning in neural networks designed for abstract reasoning has not yet been studied. Here, we study continual learning of analogical reasoning. Analogical reasoning tests such as Raven's Progressive Matrices (RPMs) are commonly used to measure non-verbal abstract reasoning in humans, and recently offline neural networks for the RPM problem have been proposed. In this paper, we establish experimental baselines, protocols, and forward and backward transfer metrics to evaluate continual learners on RPMs. We employ experience replay to mitigate catastrophic forgetting. Prior work using replay for image classification tasks has found that selectively choosing the samples to replay offers little, if any, benefit over random selection. In contrast, we find that selective replay can significantly outperform random selection for the RPM task.
Detecting Spurious Correlations with Sanity Tests for Artificial Intelligence Guided Radiology Systems
Mar 04, 2021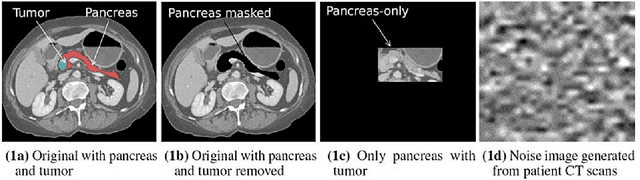

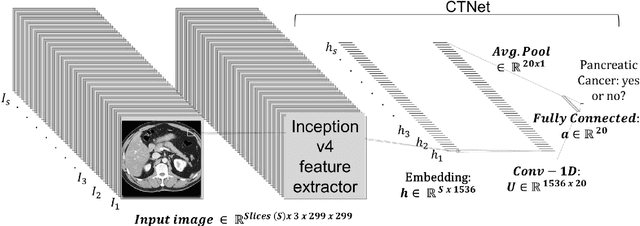

Artificial intelligence (AI) has been successful at solving numerous problems in machine perception. In radiology, AI systems are rapidly evolving and show progress in guiding treatment decisions, diagnosing, localizing disease on medical images, and improving radiologists' efficiency. A critical component to deploying AI in radiology is to gain confidence in a developed system's efficacy and safety. The current gold standard approach is to conduct an analytical validation of performance on a generalization dataset from one or more institutions, followed by a clinical validation study of the system's efficacy during deployment. Clinical validation studies are time-consuming, and best practices dictate limited re-use of analytical validation data, so it is ideal to know ahead of time if a system is likely to fail analytical or clinical validation. In this paper, we describe a series of sanity tests to identify when a system performs well on development data for the wrong reasons. We illustrate the sanity tests' value by designing a deep learning system to classify pancreatic cancer seen in computed tomography scans.
Improved Robustness to Open Set Inputs via Tempered Mixup
Sep 10, 2020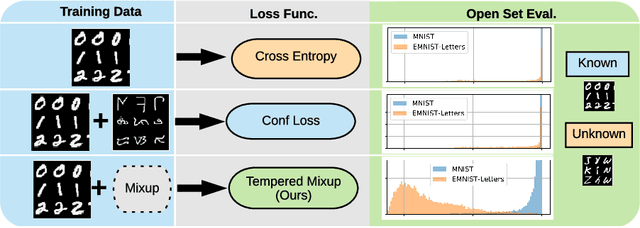
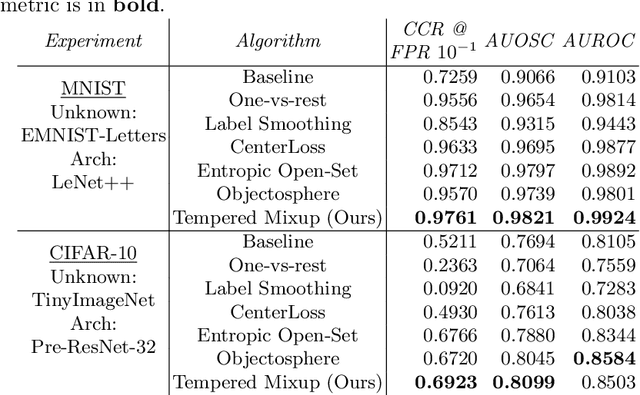
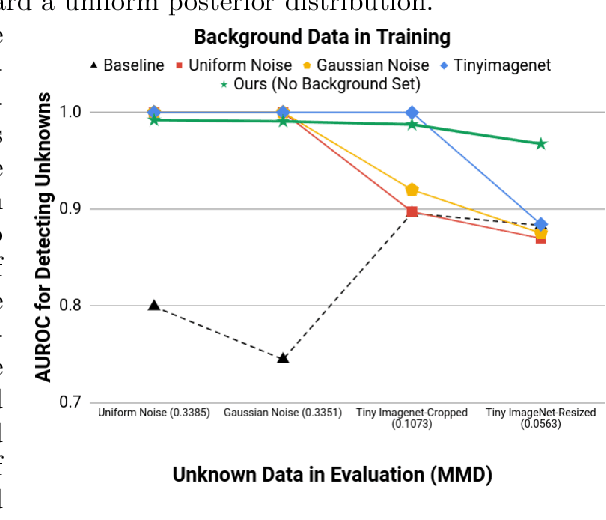
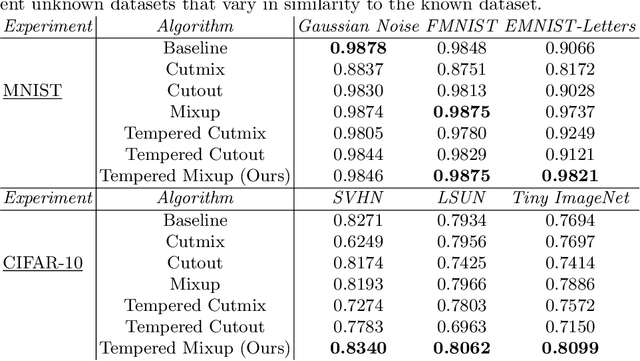
Supervised classification methods often assume that evaluation data is drawn from the same distribution as training data and that all classes are present for training. However, real-world classifiers must handle inputs that are far from the training distribution including samples from unknown classes. Open set robustness refers to the ability to properly label samples from previously unseen categories as novel and avoid high-confidence, incorrect predictions. Existing approaches have focused on either novel inference methods, unique training architectures, or supplementing the training data with additional background samples. Here, we propose a simple regularization technique easily applied to existing convolutional neural network architectures that improves open set robustness without a background dataset. Our method achieves state-of-the-art results on open set classification baselines and easily scales to large-scale open set classification problems.
RODEO: Replay for Online Object Detection
Aug 14, 2020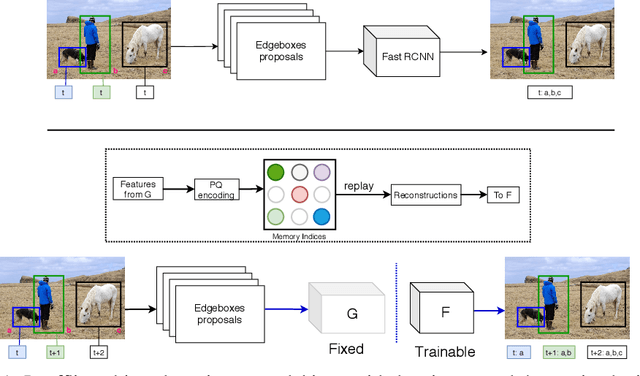
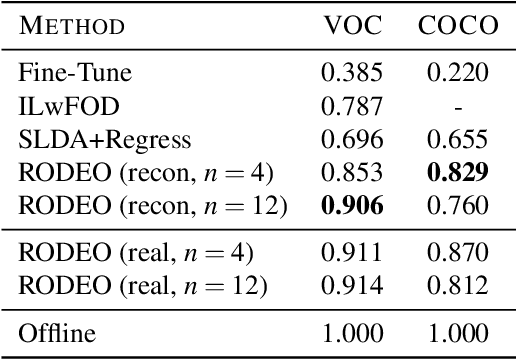
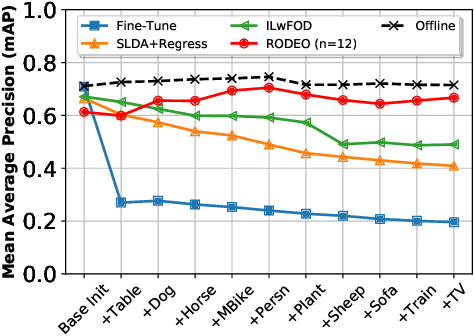
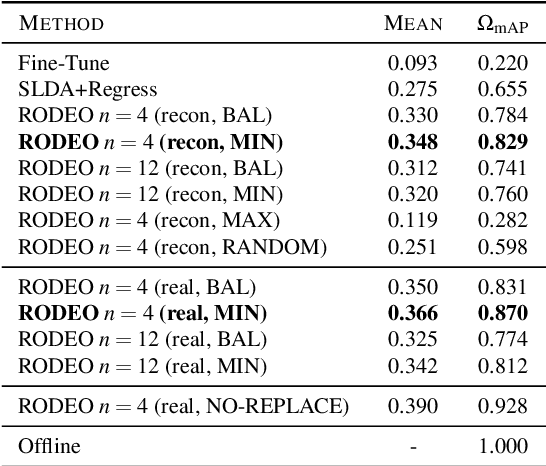
Humans can incrementally learn to do new visual detection tasks, which is a huge challenge for today's computer vision systems. Incrementally trained deep learning models lack backwards transfer to previously seen classes and suffer from a phenomenon known as $"catastrophic forgetting."$ In this paper, we pioneer online streaming learning for object detection, where an agent must learn examples one at a time with severe memory and computational constraints. In object detection, a system must output all bounding boxes for an image with the correct label. Unlike earlier work, the system described in this paper can learn this task in an online manner with new classes being introduced over time. We achieve this capability by using a novel memory replay mechanism that efficiently replays entire scenes. We achieve state-of-the-art results on both the PASCAL VOC 2007 and MS COCO datasets.
On the Value of Out-of-Distribution Testing: An Example of Goodhart's Law
May 19, 2020Out-of-distribution (OOD) testing is increasingly popular for evaluating a machine learning system's ability to generalize beyond the biases of a training set. OOD benchmarks are designed to present a different joint distribution of data and labels between training and test time. VQA-CP has become the standard OOD benchmark for visual question answering, but we discovered three troubling practices in its current use. First, most published methods rely on explicit knowledge of the construction of the OOD splits. They often rely on ``inverting'' the distribution of labels, e.g. answering mostly 'yes' when the common training answer is 'no'. Second, the OOD test set is used for model selection. Third, a model's in-domain performance is assessed after retraining it on in-domain splits (VQA v2) that exhibit a more balanced distribution of labels. These three practices defeat the objective of evaluating generalization, and put into question the value of methods specifically designed for this dataset. We show that embarrassingly-simple methods, including one that generates answers at random, surpass the state of the art on some question types. We provide short- and long-term solutions to avoid these pitfalls and realize the benefits of OOD evaluation.
Do We Need Fully Connected Output Layers in Convolutional Networks?
Apr 29, 2020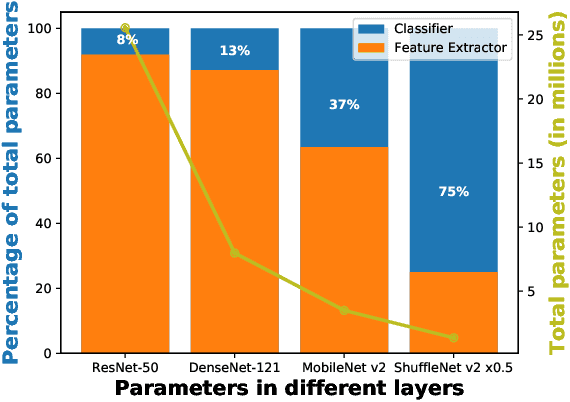
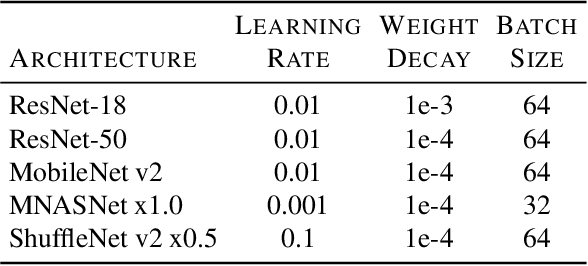
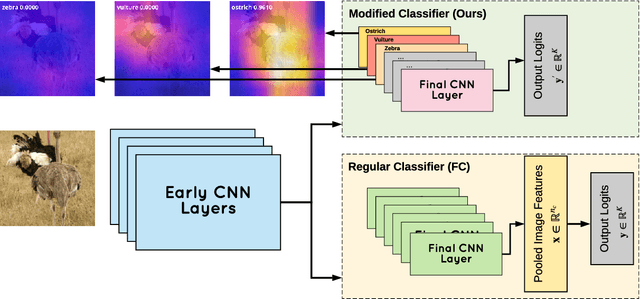
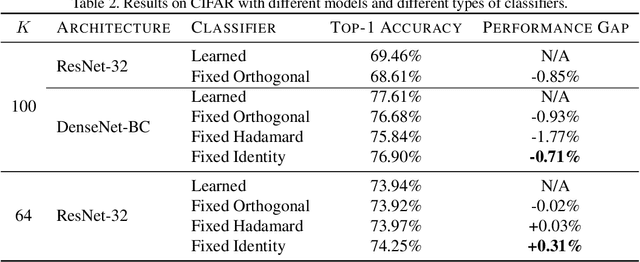
Traditionally, deep convolutional neural networks consist of a series of convolutional and pooling layers followed by one or more fully connected (FC) layers to perform the final classification. While this design has been successful, for datasets with a large number of categories, the fully connected layers often account for a large percentage of the network's parameters. For applications with memory constraints, such as mobile devices and embedded platforms, this is not ideal. Recently, a family of architectures that involve replacing the learned fully connected output layer with a fixed layer has been proposed as a way to achieve better efficiency. In this paper we examine this idea further and demonstrate that fixed classifiers offer no additional benefit compared to simply removing the output layer along with its parameters. We further demonstrate that the typical approach of having a fully connected final output layer is inefficient in terms of parameter count. We are able to achieve comparable performance to a traditionally learned fully connected classification output layer on the ImageNet-1K, CIFAR-100, Stanford Cars-196, and Oxford Flowers-102 datasets, while not having a fully connected output layer at all.
A negative case analysis of visual grounding methods for VQA
Apr 15, 2020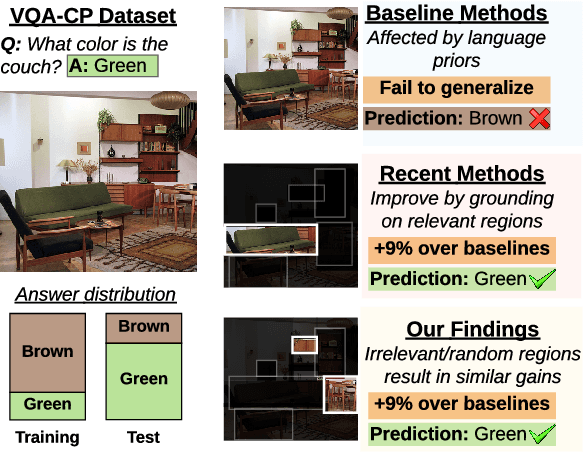
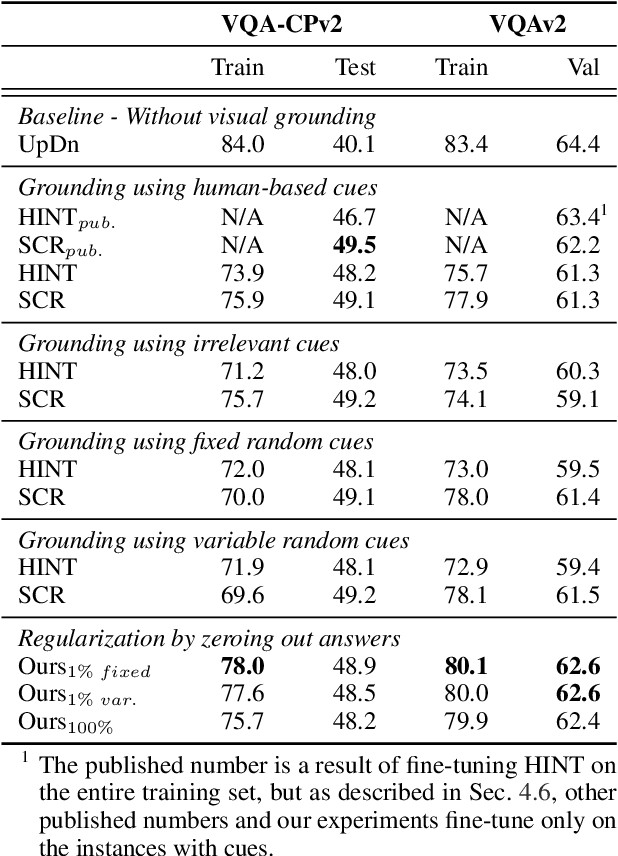
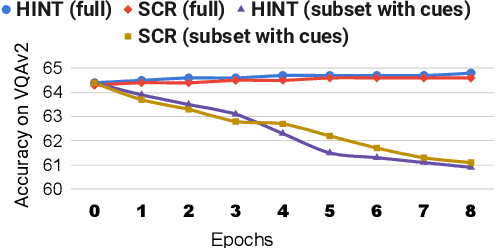

Existing Visual Question Answering (VQA) methods tend to exploit dataset biases and spurious statistical correlations, instead of producing right answers for the right reasons. To address this issue, recent bias mitigation methods for VQA propose to incorporate visual cues (e.g., human attention maps) to better ground the VQA models, showcasing impressive gains. However, we show that the performance improvements are not a result of improved visual grounding, but a regularization effect which prevents over-fitting to linguistic priors. For instance, we find that it is not actually necessary to provide proper, human-based cues; random, insensible cues also result in similar improvements. Based on this observation, we propose a simpler regularization scheme that does not require any external annotations and yet achieves near state-of-the-art performance on VQA-CPv2.