 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Reinforcement Learning under Mixed Observability
Apr 05, 2022

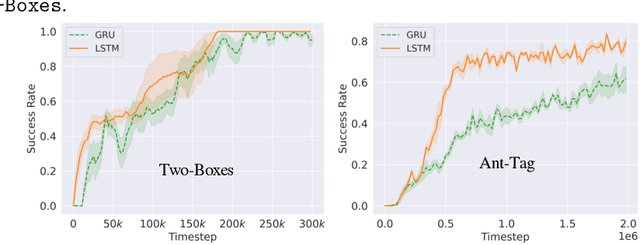
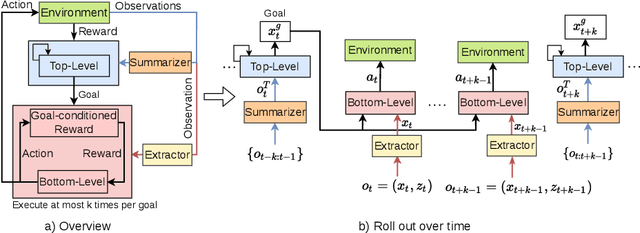
The framework of mixed observable Markov decision processes (MOMDP) models many robotic domains in which some state variables are fully observable while others are not. In this work, we identify a significant subclass of MOMDPs defined by how actions influence the fully observable components of the state and how those, in turn, influence the partially observable components and the rewards. This unique property allows for a two-level hierarchical approach we call HIerarchical Reinforcement Learning under Mixed Observability (HILMO), which restricts partial observability to the top level while the bottom level remains fully observable, enabling higher learning efficiency. The top level produces desired goals to be reached by the bottom level until the task is solved. We further develop theoretical guarantees to show that our approach can achieve optimal and quasi-optimal behavior under mild assumptions. Empirical results on long-horizon continuous control tasks demonstrate the efficacy and efficiency of our approach in terms of improved success rate, sample efficiency, and wall-clock training time. We also deploy policies learned in simulation on a real robot.
BADDr: Bayes-Adaptive Deep Dropout RL for POMDPs
Feb 17, 2022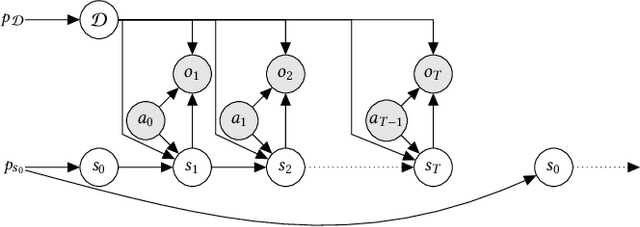

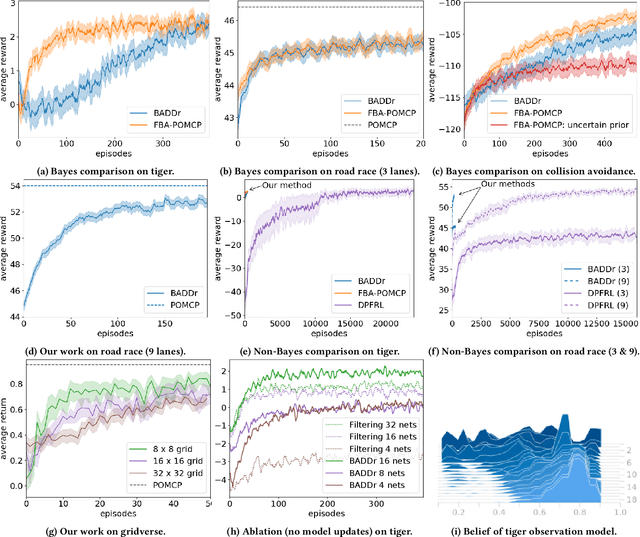

While reinforcement learning (RL) has made great advances in scalability, exploration and partial observability are still active research topics. In contrast, Bayesian RL (BRL) provides a principled answer to both state estimation and the exploration-exploitation trade-off, but struggles to scale. To tackle this challenge, BRL frameworks with various prior assumptions have been proposed, with varied success. This work presents a representation-agnostic formulation of BRL under partially observability, unifying the previous models under one theoretical umbrella. To demonstrate its practical significance we also propose a novel derivation, Bayes-Adaptive Deep Dropout rl (BADDr), based on dropout networks. Under this parameterization, in contrast to previous work, the belief over the state and dynamics is a more scalable inference problem. We choose actions through Monte-Carlo tree search and empirically show that our method is competitive with state-of-the-art BRL methods on small domains while being able to solve much larger ones.
A Deeper Understanding of State-Based Critics in Multi-Agent Reinforcement Learning
Jan 03, 2022

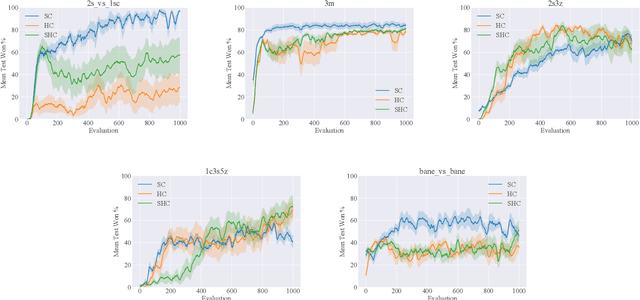
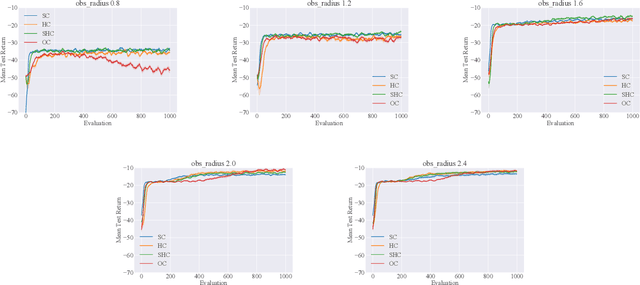
Centralized Training for Decentralized Execution, where training is done in a centralized offline fashion, has become a popular solution paradigm in Multi-Agent Reinforcement Learning. Many such methods take the form of actor-critic with state-based critics, since centralized training allows access to the true system state, which can be useful during training despite not being available at execution time. State-based critics have become a common empirical choice, albeit one which has had limited theoretical justification or analysis. In this paper, we show that state-based critics can introduce bias in the policy gradient estimates, potentially undermining the asymptotic guarantees of the algorithm. We also show that, even if the state-based critics do not introduce any bias, they can still result in a larger gradient variance, contrary to the common intuition. Finally, we show the effects of the theories in practice by comparing different forms of centralized critics on a wide range of common benchmarks, and detail how various environmental properties are related to the effectiveness of different types of critics.
Improving the Efficiency of Off-Policy Reinforcement Learning by Accounting for Past Decisions
Dec 23, 2021Off-policy learning from multistep returns is crucial for sample-efficient reinforcement learning, particularly in the experience replay setting now commonly used with deep neural networks. Classically, off-policy estimation bias is corrected in a per-decision manner: past temporal-difference errors are re-weighted by the instantaneous Importance Sampling (IS) ratio (via eligibility traces) after each action. Many important off-policy algorithms such as Tree Backup and Retrace rely on this mechanism along with differing protocols for truncating ("cutting") the ratios ("traces") to counteract the excessive variance of the IS estimator. Unfortunately, cutting traces on a per-decision basis is not necessarily efficient; once a trace has been cut according to local information, the effect cannot be reversed later, potentially resulting in the premature truncation of estimated returns and slower learning. In the interest of motivating efficient off-policy algorithms, we propose a multistep operator that permits arbitrary past-dependent traces. We prove that our operator is convergent for policy evaluation, and for optimal control when targeting greedy-in-the-limit policies. Our theorems establish the first convergence guarantees for many existing algorithms including Truncated IS, Non-Markov Retrace, and history-dependent TD($\lambda$). Our theoretical results also provide guidance for the development of new algorithms that jointly consider multiple past decisions for better credit assignment and faster learning.
Virtual Replay Cache
Dec 06, 2021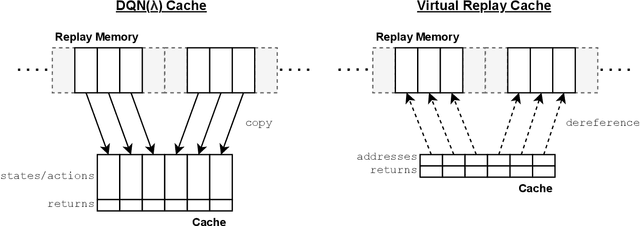
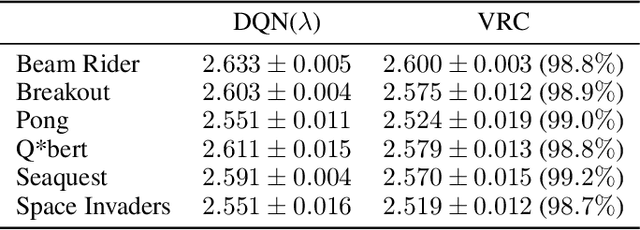

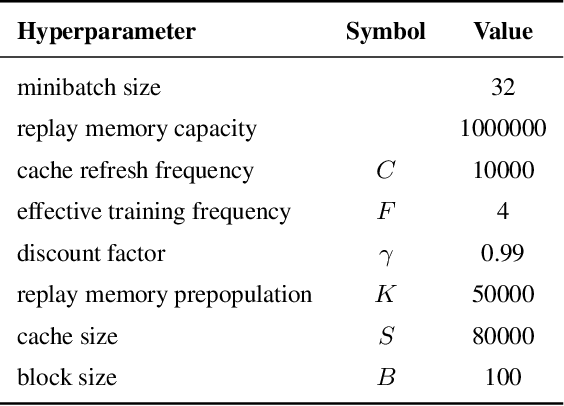
Return caching is a recent strategy that enables efficient minibatch training with multistep estimators (e.g. the {\lambda}-return) for deep reinforcement learning. By precomputing return estimates in sequential batches and then storing the results in an auxiliary data structure for later sampling, the average computation spent per estimate can be greatly reduced. Still, the efficiency of return caching could be improved, particularly with regard to its large memory usage and repetitive data copies. We propose a new data structure, the Virtual Replay Cache (VRC), to address these shortcomings. When learning to play Atari 2600 games, the VRC nearly eliminates DQN({\lambda})'s cache memory footprint and slightly reduces the total training time on our hardware.
Local Advantage Actor-Critic for Robust Multi-Agent Deep Reinforcement Learning
Nov 02, 2021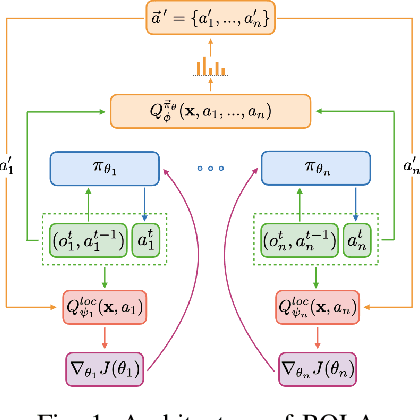
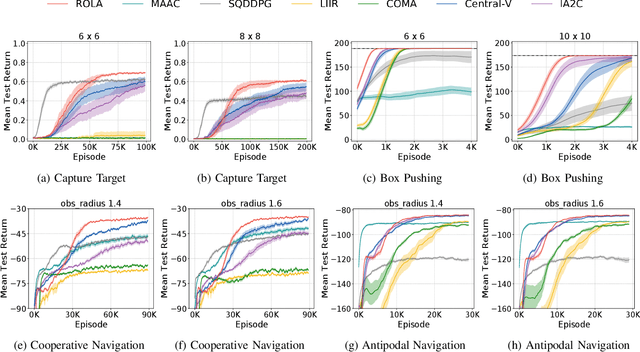
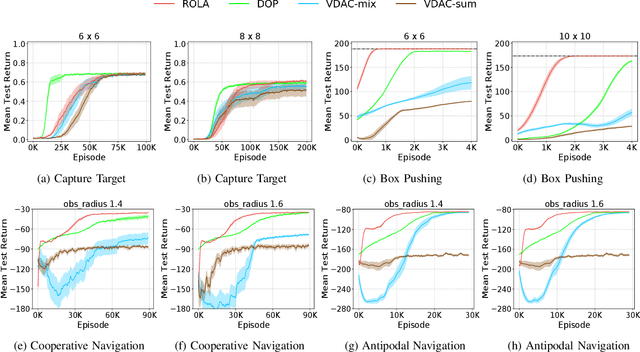
Policy gradient methods have become popular in multi-agent reinforcement learning, but they suffer from high variance due to the presence of environmental stochasticity and exploring agents (i.e., non-stationarity), which is potentially worsened by the difficulty in credit assignment. As a result, there is a need for a method that is not only capable of efficiently solving the above two problems but also robust enough to solve a variety of tasks. To this end, we propose a new multi-agent policy gradient method, called Robust Local Advantage (ROLA) Actor-Critic. ROLA allows each agent to learn an individual action-value function as a local critic as well as ameliorating environment non-stationarity via a novel centralized training approach based on a centralized critic. By using this local critic, each agent calculates a baseline to reduce variance on its policy gradient estimation, which results in an expected advantage action-value over other agents' choices that implicitly improves credit assignment. We evaluate ROLA across diverse benchmarks and show its robustness and effectiveness over a number of state-of-the-art multi-agent policy gradient algorithms.
Human-Level Control without Server-Grade Hardware
Nov 01, 2021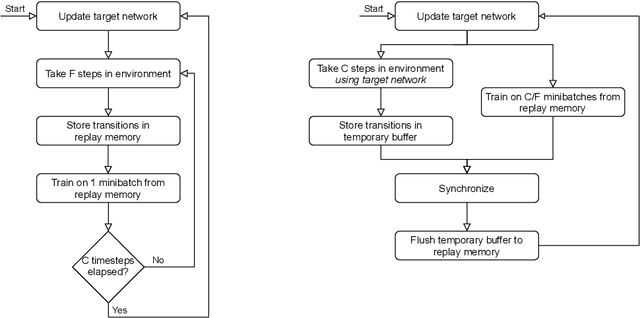

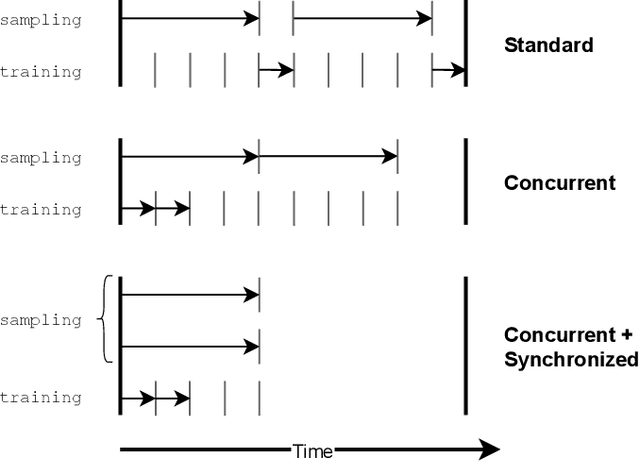

Deep Q-Network (DQN) marked a major milestone for reinforcement learning, demonstrating for the first time that human-level control policies could be learned directly from raw visual inputs via reward maximization. Even years after its introduction, DQN remains highly relevant to the research community since many of its innovations have been adopted by successor methods. Nevertheless, despite significant hardware advances in the interim, DQN's original Atari 2600 experiments remain costly to replicate in full. This poses an immense barrier to researchers who cannot afford state-of-the-art hardware or lack access to large-scale cloud computing resources. To facilitate improved access to deep reinforcement learning research, we introduce a DQN implementation that leverages a novel concurrent and synchronized execution framework designed to maximally utilize a heterogeneous CPU-GPU desktop system. With just one NVIDIA GeForce GTX 1080 GPU, our implementation reduces the training time of a 200-million-frame Atari experiment from 25 hours to just 9 hours. The ideas introduced in our paper should be generalizable to a large number of off-policy deep reinforcement learning methods.
Investigating Alternatives to the Root Mean Square for Adaptive Gradient Methods
Jun 10, 2021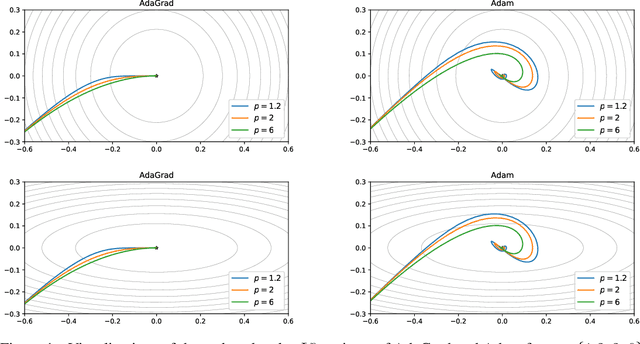

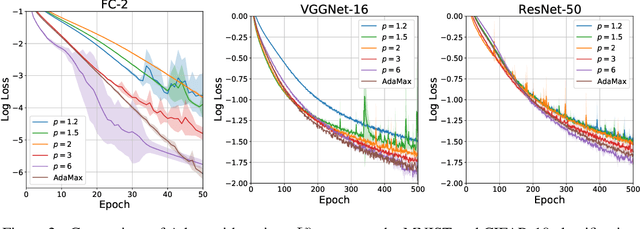
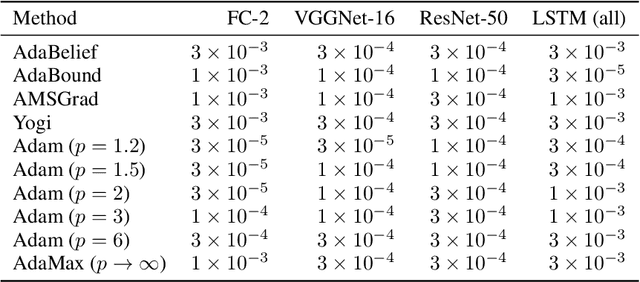
Adam is an adaptive gradient method that has experienced widespread adoption due to its fast and reliable training performance. Recent approaches have not offered significant improvement over Adam, often because they do not innovate upon one of its core features: normalization by the root mean square (RMS) of recent gradients. However, as noted by Kingma and Ba (2015), any number of $L^p$ normalizations are possible, with the RMS corresponding to the specific case of $p=2$. In our work, we theoretically and empirically characterize the influence of different $L^p$ norms on adaptive gradient methods for the first time. We show mathematically how the choice of $p$ influences the size of the steps taken, while leaving other desirable properties unaffected. We evaluate Adam with various $L^p$ norms on a suite of deep learning benchmarks, and find that $p > 2$ consistently leads to improved learning speed and final performance. The choices of $p=3$ or $p=6$ also match or outperform state-of-the-art methods in all of our experiments.
Reconciling Rewards with Predictive State Representations
Jun 07, 2021
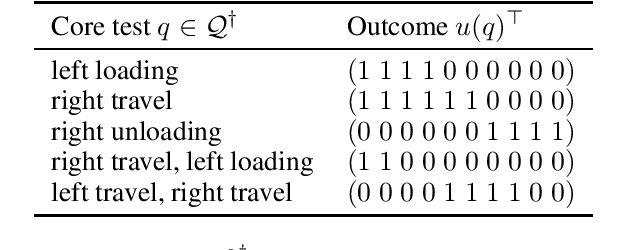

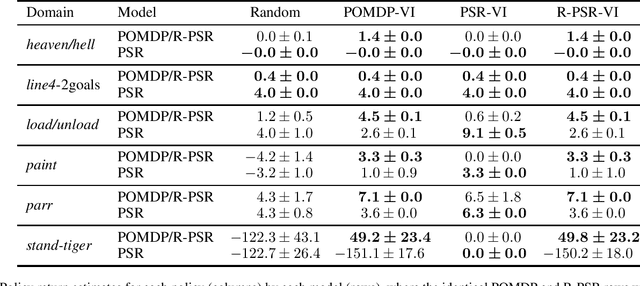
Predictive state representations (PSRs) are models of controlled non-Markov observation sequences which exhibit the same generative process governing POMDP observations without relying on an underlying latent state. In that respect, a PSR is indistinguishable from the corresponding POMDP. However, PSRs notoriously ignore the notion of rewards, which undermines the general utility of PSR models for control, planning, or reinforcement learning. Therefore, we describe a sufficient and necessary accuracy condition which determines whether a PSR is able to accurately model POMDP rewards, we show that rewards can be approximated even when the accuracy condition is not satisfied, and we find that a non-trivial number of POMDPs taken from a well-known third-party repository do not satisfy the accuracy condition. We propose reward-predictive state representations (R-PSRs), a generalization of PSRs which accurately models both observations and rewards, and develop value iteration for R-PSRs. We show that there is a mismatch between optimal POMDP policies and the optimal PSR policies derived from approximate rewards. On the other hand, optimal R-PSR policies perfectly match optimal POMDP policies, reconfirming R-PSRs as accurate state-less generative models of observations and rewards.
Hierarchical Robot Navigation in Novel Environments using Rough 2-D Maps
Jun 07, 2021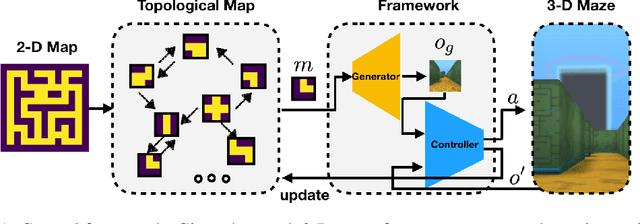

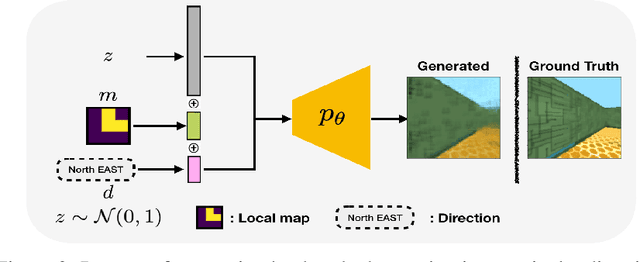
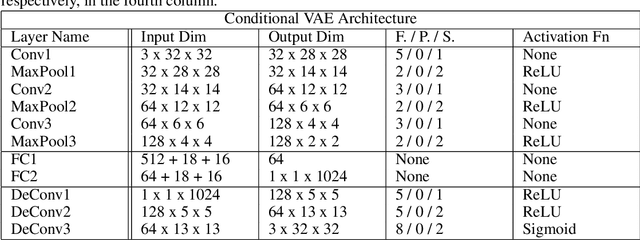
In robot navigation, generalizing quickly to unseen environments is essential. Hierarchical methods inspired by human navigation have been proposed, typically consisting of a high-level landmark proposer and a low-level controller. However, these methods either require precise high-level information to be given in advance or need to construct such guidance from extensive interaction with the environment. In this work, we propose an approach that leverages a rough 2-D map of the environment to navigate in novel environments without requiring further learning. In particular, we introduce a dynamic topological map that can be initialized from the rough 2-D map along with a high-level planning approach for proposing reachable 2-D map patches of the intermediate landmarks between the start and goal locations. To use proposed 2-D patches, we train a deep generative model to generate intermediate landmarks in observation space which are used as subgoals by low-level goal-conditioned reinforcement learning. Importantly, because the low-level controller is only trained with local behaviors (e.g. go across the intersection, turn left at a corner) on existing environments, this framework allows us to generalize to novel environments given only a rough 2-D map, without requiring further learning. Experimental results demonstrate the effectiveness of the proposed framework in both seen and novel environments.