 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudonorm Approachability and Applications to Regret Minimization
Feb 03, 2023Blackwell's celebrated approachability theory provides a general framework for a variety of learning problems, including regret minimization. However, Blackwell's proof and implicit algorithm measure approachability using the $\ell_2$ (Euclidean) distance. We argue that in many applications such as regret minimization, it is more useful to study approachability under other distance metrics, most commonly the $\ell_\infty$-metric. But, the time and space complexity of the algorithms designed for $\ell_\infty$-approachability depend on the dimension of the space of the vectorial payoffs, which is often prohibitively large. Thus, we present a framework for converting high-dimensional $\ell_\infty$-approachability problems to low-dimensional pseudonorm approachability problems, thereby resolving such issues. We first show that the $\ell_\infty$-distance between the average payoff and the approachability set can be equivalently defined as a pseudodistance between a lower-dimensional average vector payoff and a new convex set we define. Next, we develop an algorithmic theory of pseudonorm approachability, analogous to previous work on approachability for $\ell_2$ and other norms, showing that it can be achieved via online linear optimization (OLO) over a convex set given by the Fenchel dual of the unit pseudonorm ball. We then use that to show, modulo mild normalization assumptions, that there exists an $\ell_\infty$-approachability algorithm whose convergence is independent of the dimension of the original vectorial payoff. We further show that that algorithm admits a polynomial-time complexity, assuming that the original $\ell_\infty$-distance can be computed efficiently. We also give an $\ell_\infty$-approachability algorithm whose convergence is logarithmic in that dimension using an FTRL algorithm with a maximum-entropy regularizer.
Learning in POMDPs is Sample-Efficient with Hindsight Observability
Feb 03, 2023POMDPs capture a broad class of decision making problems, but hardness results suggest that learning is intractable even in simple settings due to the inherent partial observability. However, in many realistic problems, more information is either revealed or can be computed during some point of the learning process. Motivated by diverse applications ranging from robotics to data center scheduling, we formulate a Hindsight Observable Markov Decision Process (HOMDP) as a POMDP where the latent states are revealed to the learner in hindsight and only during training. We introduce new algorithms for the tabular and function approximation settings that are provably sample-efficient with hindsight observability, even in POMDPs that would otherwise be statistically intractable. We give a lower bound showing that the tabular algorithm is optimal in its dependence on latent state and observation cardinalities.
A Unified Algorithm for Stochastic Path Problems
Oct 17, 2022
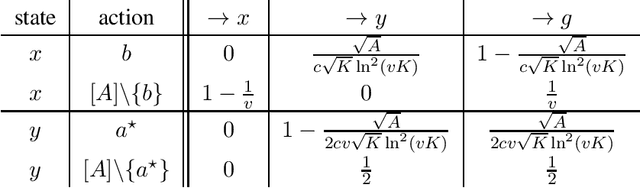
We study reinforcement learning in stochastic path (SP) problems. The goal in these problems is to maximize the expected sum of rewards until the agent reaches a terminal state. We provide the first regret guarantees in this general problem by analyzing a simple optimistic algorithm. Our regret bound matches the best known results for the well-studied special case of stochastic shortest path (SSP) with all non-positive rewards. For SSP, we present an adaptation procedure for the case when the scale of rewards $B_\star$ is unknown. We show that there is no price for adaptation, and our regret bound matches that with a known $B_\star$. We also provide a scale adaptation procedure for the special case of stochastic longest paths (SLP) where all rewards are non-negative. However, unlike in SSP, we show through a lower bound that there is an unavoidable price for adaptation.
A Provably Efficient Model-Free Posterior Sampling Method for Episodic Reinforcement Learning
Aug 23, 2022Thompson Sampling is one of the most effective methods for contextual bandits and has been generalized to posterior sampling for certain MDP settings. However, existing posterior sampling methods for reinforcement learning are limited by being model-based or lack worst-case theoretical guarantees beyond linear MDPs. This paper proposes a new model-free formulation of posterior sampling that applies to more general episodic reinforcement learning problems with theoretical guarantees. We introduce novel proof techniques to show that under suitable conditions, the worst-case regret of our posterior sampling method matches the best known results of optimization based methods. In the linear MDP setting with dimension, the regret of our algorithm scales linearly with the dimension as compared to a quadratic dependence of the existing posterior sampling-based exploration algorithms.
Best of Both Worlds Model Selection
Jun 29, 2022We study the problem of model selection in bandit scenarios in the presence of nested policy classes, with the goal of obtaining simultaneous adversarial and stochastic ("best of both worlds") high-probability regret guarantees. Our approach requires that each base learner comes with a candidate regret bound that may or may not hold, while our meta algorithm plays each base learner according to a schedule that keeps the base learner's candidate regret bounds balanced until they are detected to violate their guarantees. We develop careful mis-specification tests specifically designed to blend the above model selection criterion with the ability to leverage the (potentially benign) nature of the environment. We recover the model selection guarantees of the CORRAL algorithm for adversarial environments, but with the additional benefit of achieving high probability regret bounds, specifically in the case of nested adversarial linear bandits. More importantly, our model selection results also hold simultaneously in stochastic environments under gap assumptions. These are the first theoretical results that achieve best of both world (stochastic and adversarial) guarantees while performing model selection in (linear) bandit scenarios.
Guarantees for Epsilon-Greedy Reinforcement Learning with Function Approximation
Jun 19, 2022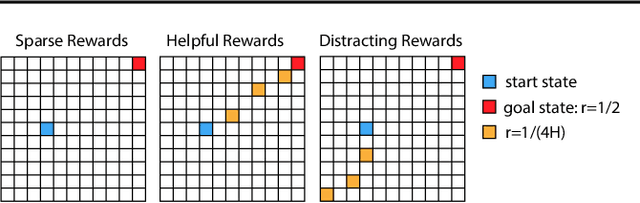
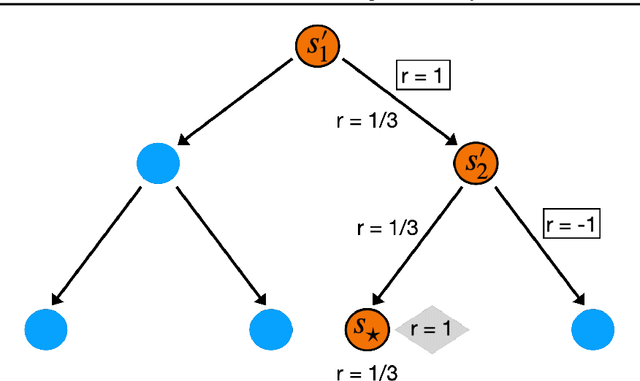
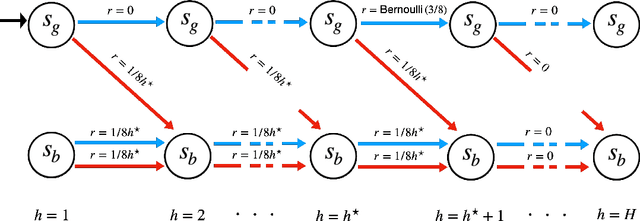
Myopic exploration policies such as epsilon-greedy, softmax, or Gaussian noise fail to explore efficiently in some reinforcement learning tasks and yet, they perform well in many others. In fact, in practice, they are often selected as the top choices, due to their simplicity. But, for what tasks do such policies succeed? Can we give theoretical guarantees for their favorable performance? These crucial questions have been scarcely investigated, despite the prominent practical importance of these policies. This paper presents a theoretical analysis of such policies and provides the first regret and sample-complexity bounds for reinforcement learning with myopic exploration. Our results apply to value-function-based algorithms in episodic MDPs with bounded Bellman Eluder dimension. We propose a new complexity measure called myopic exploration gap, denoted by alpha, that captures a structural property of the MDP, the exploration policy and the given value function class. We show that the sample-complexity of myopic exploration scales quadratically with the inverse of this quantity, 1 / alpha^2. We further demonstrate through concrete examples that myopic exploration gap is indeed favorable in several tasks where myopic exploration succeeds, due to the corresponding dynamics and reward structure.
Same Cause; Different Effects in the Brain
Feb 21, 2022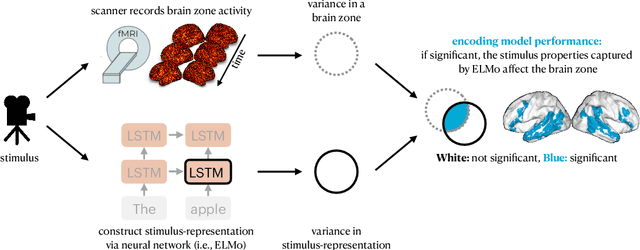
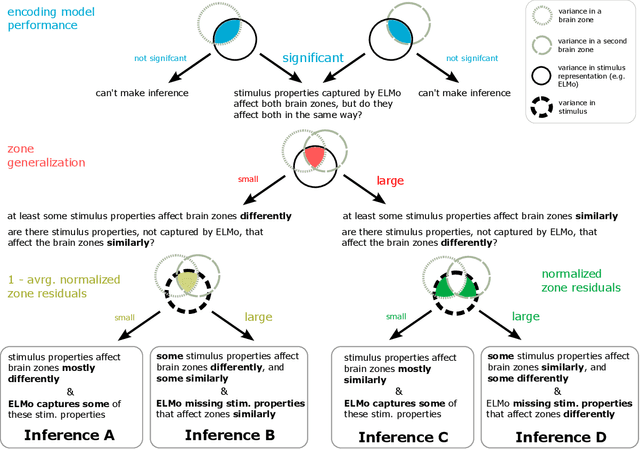
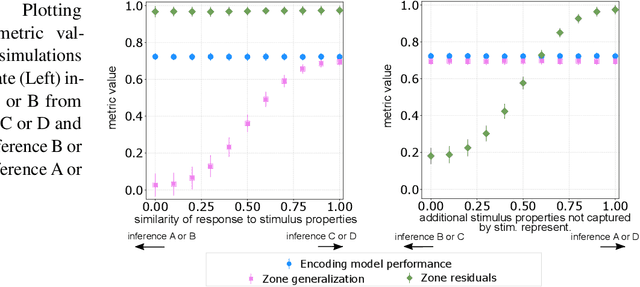
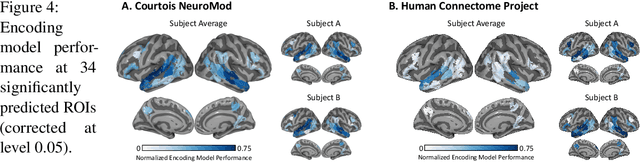
To study information processing in the brain, neuroscientists manipulate experimental stimuli while recording participant brain activity. They can then use encoding models to find out which brain "zone" (e.g. which region of interest, volume pixel or electrophysiology sensor) is predicted from the stimulus properties. Given the assumptions underlying this setup, when stimulus properties are predictive of the activity in a zone, these properties are understood to cause activity in that zone. In recent years, researchers have used neural networks to construct representations that capture the diverse properties of complex stimuli, such as natural language or natural images. Encoding models built using these high-dimensional representations are often able to significantly predict the activity in large swathes of cortex, suggesting that the activity in all these brain zones is caused by stimulus properties captured in the representation. It is then natural to ask: "Is the activity in these different brain zones caused by the stimulus properties in the same way?" In neuroscientific terms, this corresponds to asking if these different zones process the stimulus properties in the same way. Here, we propose a new framework that enables researchers to ask if the properties of a stimulus affect two brain zones in the same way. We use simulated data and two real fMRI datasets with complex naturalistic stimuli to show that our framework enables us to make such inferences. Our inferences are strikingly consistent between the two datasets, indicating that the proposed framework is a promising new tool for neuroscientists to understand how information is processed in the brain.
A Model Selection Approach for Corruption Robust Reinforcement Learning
Oct 07, 2021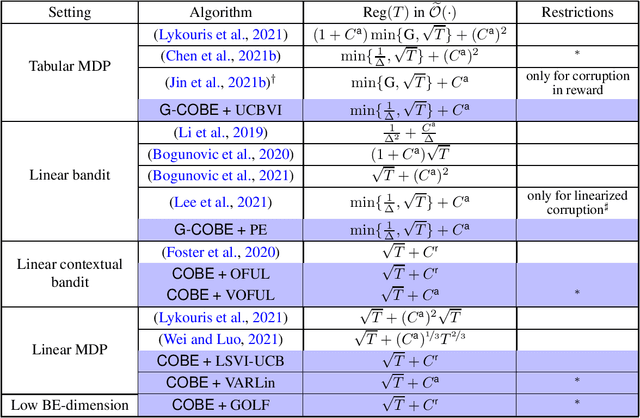
We develop a model selection approach to tackle reinforcement learning with adversarial corruption in both transition and reward. For finite-horizon tabular MDPs, without prior knowledge on the total amount of corruption, our algorithm achieves a regret bound of $\widetilde{\mathcal{O}}(\min\{\frac{1}{\Delta}, \sqrt{T}\}+C)$ where $T$ is the number of episodes, $C$ is the total amount of corruption, and $\Delta$ is the reward gap between the best and the second-best policy. This is the first worst-case optimal bound achieved without knowledge of $C$, improving previous results of Lykouris et al. (2021); Chen et al. (2021); Wu et al. (2021). For finite-horizon linear MDPs, we develop a computationally efficient algorithm with a regret bound of $\widetilde{\mathcal{O}}(\sqrt{(1+C)T})$, and another computationally inefficient one with $\widetilde{\mathcal{O}}(\sqrt{T}+C)$, improving the result of Lykouris et al. (2021) and answering an open question by Zhang et al. (2021b). Finally, our model selection framework can be easily applied to other settings including linear bandits, linear contextual bandits, and MDPs with general function approximation, leading to several improved or new results.
Beyond Value-Function Gaps: Improved Instance-Dependent Regret Bounds for Episodic Reinforcement Learning
Jul 02, 2021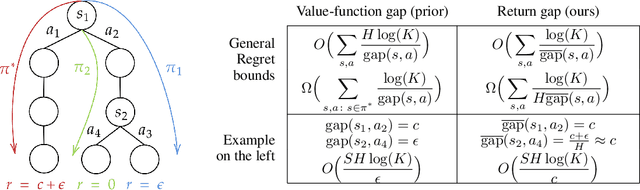
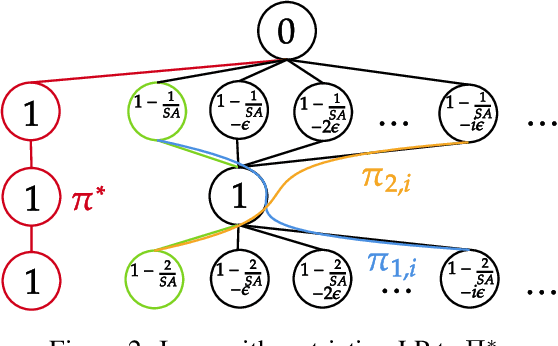
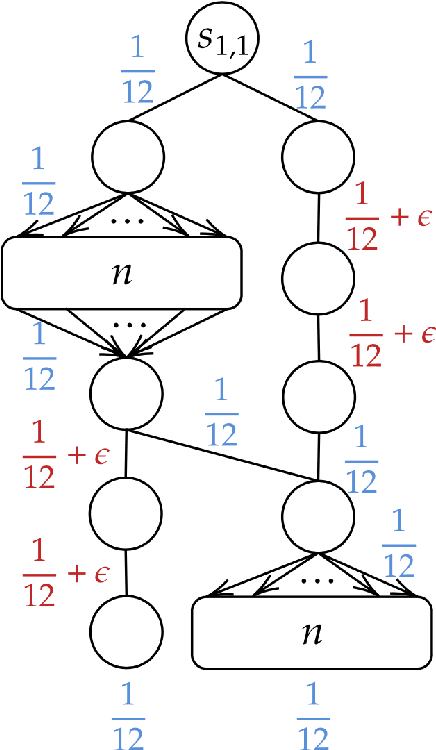
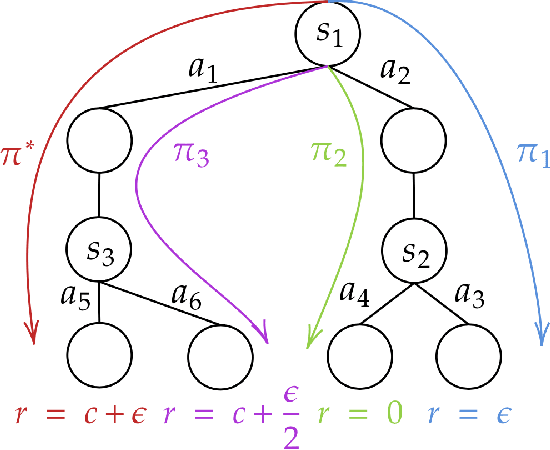
We provide improved gap-dependent regret bounds for reinforcement learning in finite episodic Markov decision processes. Compared to prior work, our bounds depend on alternative definitions of gaps. These definitions are based on the insight that, in order to achieve a favorable regret, an algorithm does not need to learn how to behave optimally in states that are not reached by an optimal policy. We prove tighter upper regret bounds for optimistic algorithms and accompany them with new information-theoretic lower bounds for a large class of MDPs. Our results show that optimistic algorithms can not achieve the information-theoretic lower bounds even in deterministic MDPs unless there is a unique optimal policy.
Agnostic Reinforcement Learning with Low-Rank MDPs and Rich Observations
Jun 22, 2021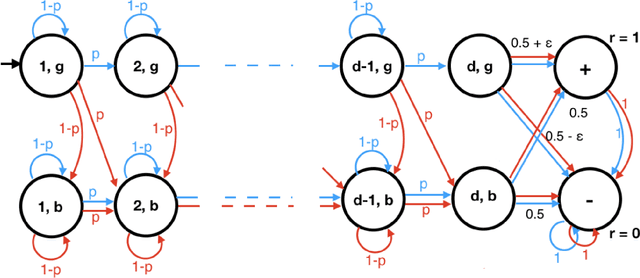
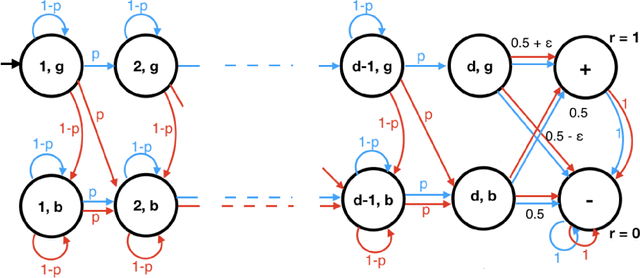
There have been many recent advances on provably efficient Reinforcement Learning (RL) in problems with rich observation spaces. However, all these works share a strong realizability assumption about the optimal value function of the true MDP. Such realizability assumptions are often too strong to hold in practice. In this work, we consider the more realistic setting of agnostic RL with rich observation spaces and a fixed class of policies $\Pi$ that may not contain any near-optimal policy. We provide an algorithm for this setting whose error is bounded in terms of the rank $d$ of the underlying MDP. Specifically, our algorithm enjoys a sample complexity bound of $\widetilde{O}\left((H^{4d} K^{3d} \log |\Pi|)/\epsilon^2\right)$ where $H$ is the length of episodes, $K$ is the number of actions and $\epsilon>0$ is the desired sub-optimality. We also provide a nearly matching lower bound for this agnostic setting that shows that the exponential dependence on rank is unavoidable, without further assumptions.