 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Data in Human Analysis: A Survey
Aug 19, 2022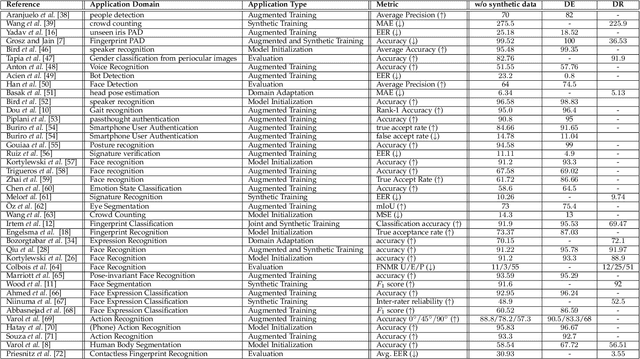



Deep neural networks have become prevalent in human analysis, boosting the performance of applications, such as biometric recognition, action recognition, as well as person re-identification. However, the performance of such networks scales with the available training data. In human analysis, the demand for large-scale datasets poses a severe challenge, as data collection is tedious, time-expensive, costly and must comply with data protection laws. Current research investigates the generation of \textit{synthetic data} as an efficient and privacy-ensuring alternative to collecting real data in the field. This survey introduces the basic definitions and methodologies, essential when generating and employing synthetic data for human analysis. We conduct a survey that summarises current state-of-the-art methods and the main benefits of using synthetic data. We also provide an overview of publicly available synthetic datasets and generation models. Finally, we discuss limitations, as well as open research problems in this field. This survey is intended for researchers and practitioners in the field of human analysis.
Time flies by: Analyzing the Impact of Face Ageing on the Recognition Performance with Synthetic Data
Aug 17, 2022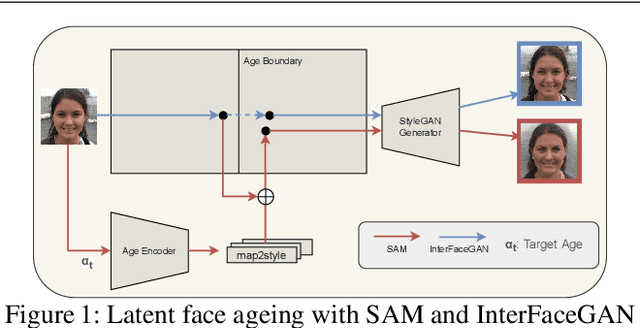
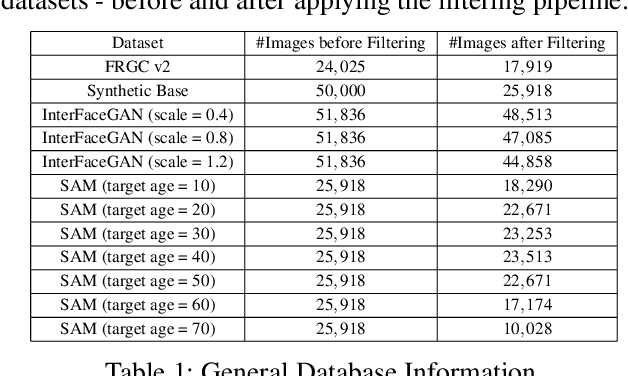
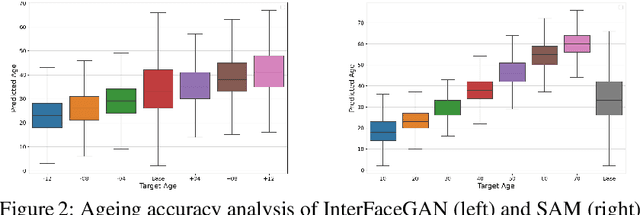
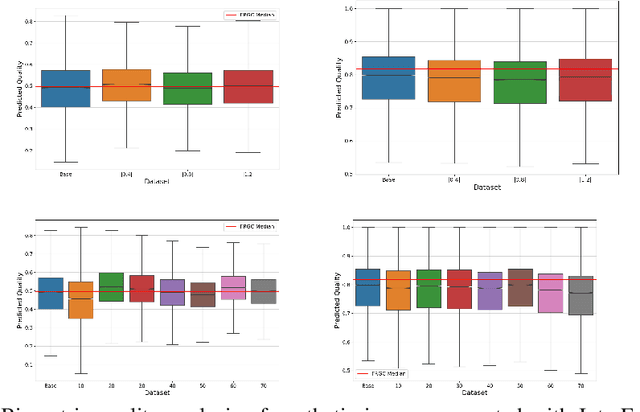
The vast progress in synthetic image synthesis enables the generation of facial images in high resolution and photorealism. In biometric applications, the main motivation for using synthetic data is to solve the shortage of publicly-available biometric data while reducing privacy risks when processing such sensitive information. These advantages are exploited in this work by simulating human face ageing with recent face age modification algorithms to generate mated samples, thereby studying the impact of ageing on the performance of an open-source biometric recognition system. Further, a real dataset is used to evaluate the effects of short-term ageing, comparing the biometric performance to the synthetic domain. The main findings indicate that short-term ageing in the range of 1-5 years has only minor effects on the general recognition performance. However, the correct verification of mated faces with long-term age differences beyond 20 years poses still a significant challenge and requires further investigation.
Single Morphing Attack Detection using Siamese Network and Few-shot Learning
Jun 22, 2022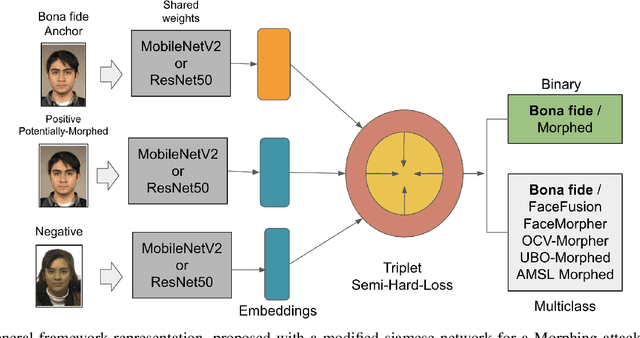


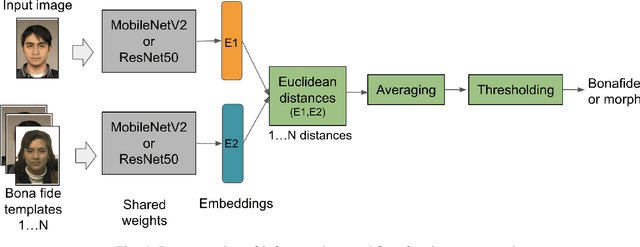
Face morphing attack detection is challenging and presents a concrete and severe threat for face verification systems. Reliable detection mechanisms for such attacks, which have been tested with a robust cross-database protocol and unknown morphing tools still is a research challenge. This paper proposes a framework following the Few-Shot-Learning approach that shares image information based on the siamese network using triplet-semi-hard-loss to tackle the morphing attack detection and boost the clustering classification process. This network compares a bona fide or potentially morphed image with triplets of morphing and bona fide face images. Our results show that this new network cluster the data points, and assigns them to classes in order to obtain a lower equal error rate in a cross-database scenario sharing only small image numbers from an unknown database. Few-shot learning helps to boost the learning process. Experimental results using a cross-datasets trained with FRGCv2 and tested with FERET and the AMSL open-access databases reduced the BPCER10 from 43% to 4.91% using ResNet50 and 5.50% for MobileNetV2.
An Overview of Privacy-enhancing Technologies in Biometric Recognition
Jun 21, 2022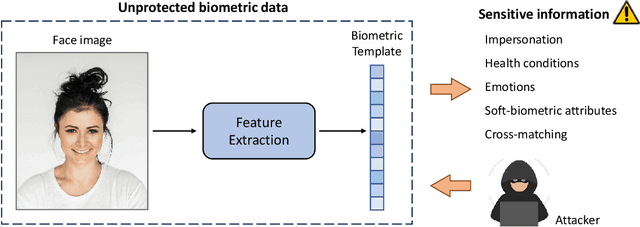

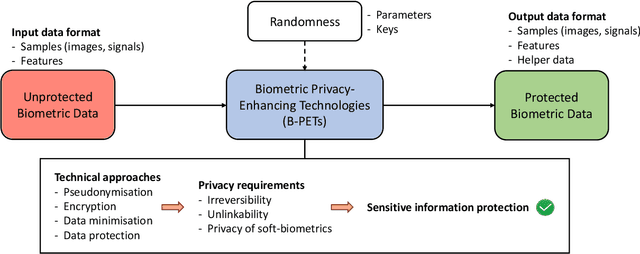
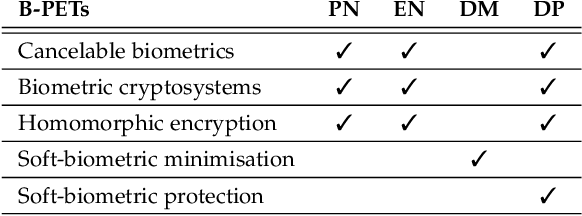
Privacy-enhancing technologies are technologies that implement fundamental data protection principles. With respect to biometric recognition, different types of privacy-enhancing technologies have been introduced for protecting stored biometric data which are generally classified as sensitive. In this regard, various taxonomies and conceptual categorizations have been proposed and standardization activities have been carried out. However, these efforts have mainly been devoted to certain sub-categories of privacy-enhancing technologies and therefore lack generalization. This work provides an overview of concepts of privacy-enhancing technologies for biometrics in a unified framework. Key aspects and differences between existing concepts are highlighted in detail at each processing step. Fundamental properties and limitations of existing approaches are discussed and related to data protection techniques and principles. Moreover, scenarios and methods for the assessment of privacy-enhancing technologies for biometrics are presented. This paper is meant as a point of entry to the field of biometric data protection and is directed towards experienced researchers as well as non-experts.
Morphing Attack Potential
Apr 28, 2022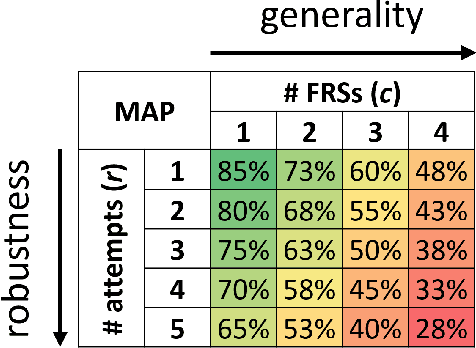
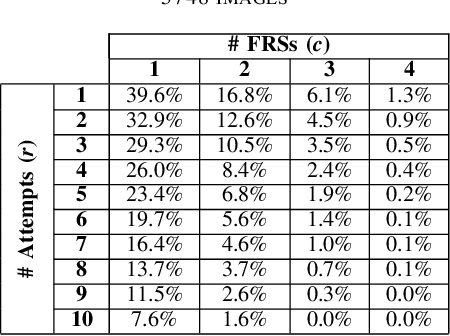
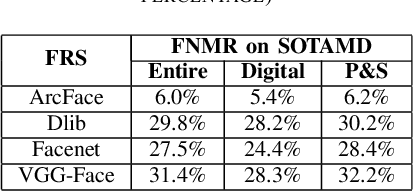
In security systems the risk assessment in the sense of common criteria testing is a very relevant topic; this requires quantifying the attack potential in terms of the expertise of the attacker, his knowledge about the target and access to equipment. Contrary to those attacks, the recently revealed morphing attacks against Face Recognition Systems (FRSs) can not be assessed by any of the above criteria. But not all morphing techniques pose the same risk for an operational face recognition system. This paper introduces with the Morphing Attack Potential (MAP) a consistent methodology, that can quantify the risk, which a certain morphing attack creates.
Analyzing Human Observer Ability in Morphing Attack Detection -- Where Do We Stand?
Mar 04, 2022
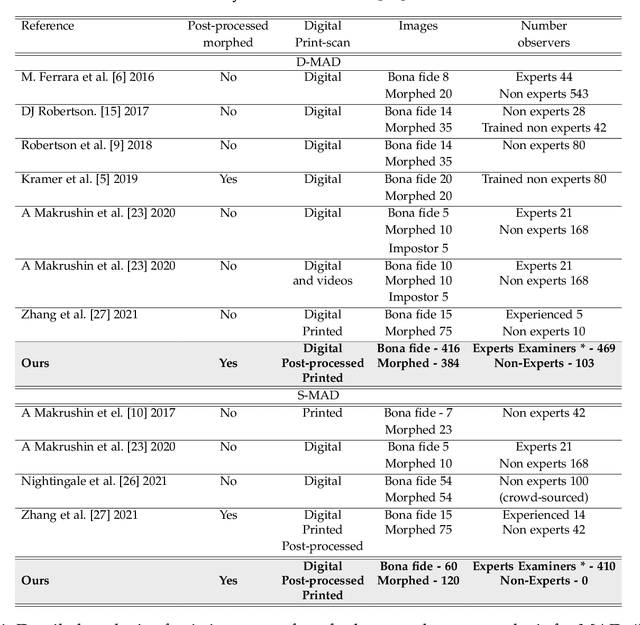
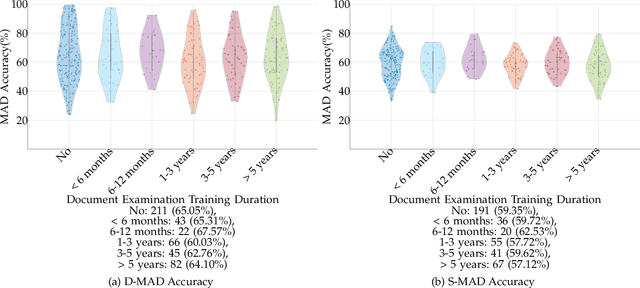
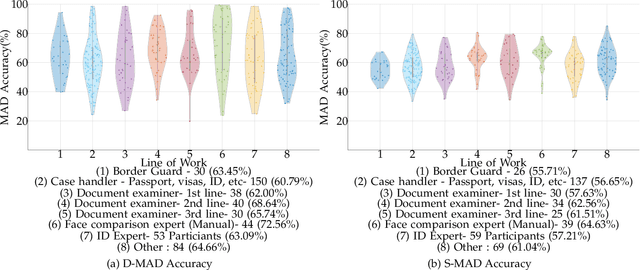
While several works have studied the vulnerability of automated FRS and have proposed morphing attack detection (MAD) methods, very few have focused on studying the human ability to detect morphing attacks. The examiner/observer's face morph detection ability is based on their observation, domain knowledge, experience, and familiarity with the problem, and no works report the detailed findings from observers who check identity documents as a part of their everyday professional life. This work creates a new benchmark database of realistic morphing attacks from 48 unique subjects leading to 400 morphed images presented to the observers in a Differential-MAD (D-MAD) setting. Unlike the existing databases, the newly created morphed image database has been created with careful considerations to age, gender and ethnicity to create realistic morph attacks. Further, unlike the previous works, we also capture ten images from Automated Border Control (ABC) gates to mimic the realistic D-MAD setting leading to 400 probe images in border crossing scenarios. The newly created dataset is further used to study the ability of human observers' ability to detect morphed images. In addition, a new dataset of 180 morphed images is also created using the FRGCv2 dataset under the Single Image-MAD (S-MAD) setting. Further, to benchmark the human ability in detecting morphs, a new evaluation platform is created to conduct S-MAD and D-MAD analysis. The benchmark study employs 469 observers for D-MAD and 410 observers for S-MAD who are primarily governmental employees from more than 40 countries. The analysis provides interesting insights and points to expert observers' missing competence and failure to detect a considerable amount of morphing attacks. Human observers tend to detect morphed images to a lower accuracy as compared to the automated MAD algorithms evaluated in this work.
Fun Selfie Filters in Face Recognition: Impact Assessment and Removal
Feb 12, 2022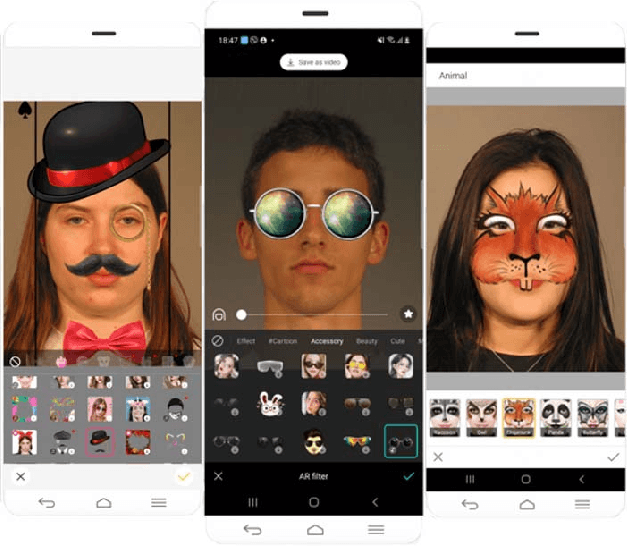
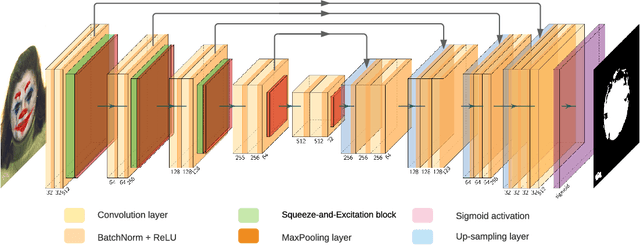


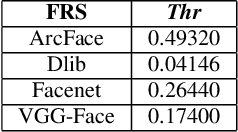
This work investigates the impact of fun selfie filters, which are frequently used to modify selfies, on face recognition systems. Based on a qualitative assessment and classification of freely available mobile applications, ten relevant fun selfie filters are selected to create a database. To this end, the selected filters are automatically applied to face images of public face image databases. Different state-of-the-art methods are used to evaluate the influence of fun selfie filters on the performance of face detection using dlib, RetinaFace, and a COTS method, sample quality estimated by FaceQNet and MagFace, and recognition accuracy employing ArcFace and a COTS algorithm. The obtained results indicate that selfie filters negatively affect face recognition modules, especially if fun selfie filters cover a large region of the face, where the mouth, nose, and eyes are covered. To mitigate such unwanted effects, a GAN-based selfie filter removal algorithm is proposed which consists of a segmentation module, a perceptual network, and a generation module. In a cross-database experiment the application of the presented selfie filter removal technique has shown to significantly improve the biometric performance of the underlying face recognition systems.
Face Beneath the Ink: Synthetic Data and Tattoo Removal with Application to Face Recognition
Feb 10, 2022


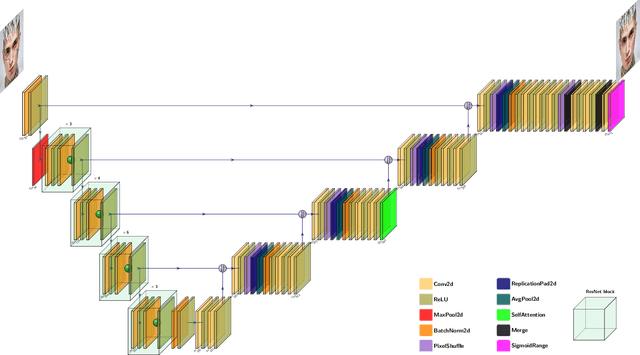
Systems that analyse faces have seen significant improvements in recent years and are today used in numerous application scenarios. However, these systems have been found to be negatively affected by facial alterations such as tattoos. To better understand and mitigate the effect of facial tattoos in facial analysis systems, large datasets of images of individuals with and without tattoos are needed. To this end, we propose a generator for automatically adding realistic tattoos to facial images. Moreover, we demonstrate the feasibility of the generation by training a deep learning-based model for removing tattoos from face images. The experimental results show that it is possible to remove facial tattoos from real images without degrading the quality of the image. Additionally, we show that it is possible to improve face recognition accuracy by using the proposed deep learning-based tattoo removal before extracting and comparing facial features.
Crowd-powered Face Manipulation Detection: Fusing Human Examiner Decisions
Jan 31, 2022



We investigate the potential of fusing human examiner decisions for the task of digital face manipulation detection. To this end, various decision fusion methods are proposed incorporating the examiners' decision confidence, experience level, and their time to take a decision. Conducted experiments are based on a psychophysical evaluation of digital face image manipulation detection capabilities of humans in which different manipulation techniques were applied, i.e. face morphing, face swapping and retouching. The decisions of 223 participants were fused to simulate crowds of up to seven human examiners. Experimental results reveal that (1) despite the moderate detection performance achieved by single human examiners, a high accuracy can be obtained through decision fusion and (2) a weighted fusion which takes the examiners' decision confidence into account yields the most competitive detection performance.
Psychophysical Evaluation of Human Performance in Detecting Digital Face Image Manipulations
Jan 28, 2022
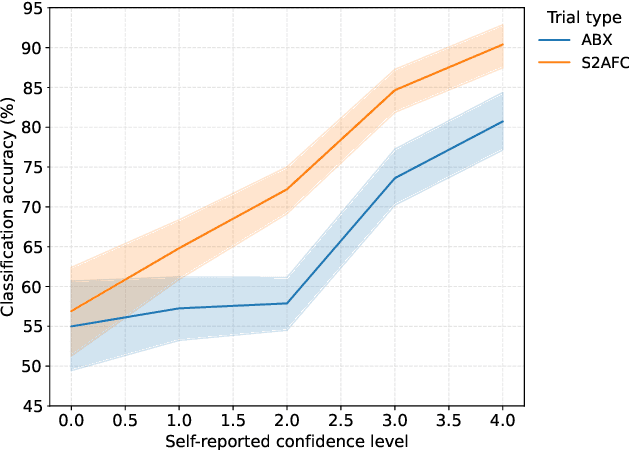
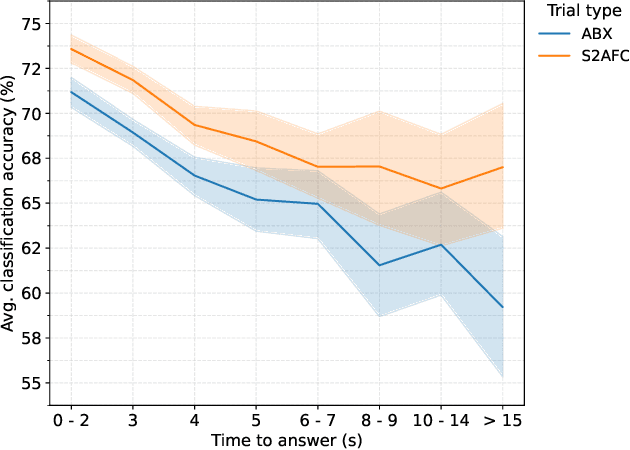
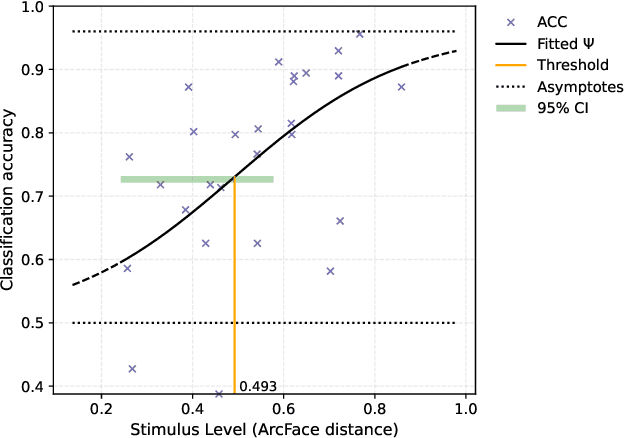
In recent years, increasing deployment of face recognition technology in security-critical settings, such as border control or law enforcement, has led to considerable interest in the vulnerability of face recognition systems to attacks utilising legitimate documents, which are issued on the basis of digitally manipulated face images. As automated manipulation and attack detection remains a challenging task, conventional processes with human inspectors performing identity verification remain indispensable. These circumstances merit a closer investigation of human capabilities in detecting manipulated face images, as previous work in this field is sparse and often concentrated only on specific scenarios and biometric characteristics. This work introduces a web-based, remote visual discrimination experiment on the basis of principles adopted from the field of psychophysics and subsequently discusses interdisciplinary opportunities with the aim of examining human proficiency in detecting different types of digitally manipulated face images, specifically face swapping, morphing, and retouching. In addition to analysing appropriate performance measures, a possible metric of detectability is explored. Experimental data of 306 probands indicate that detection performance is widely distributed across the population and detection of certain types of face image manipulations is much more challenging than others.