 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Data Pruning through Score Extrapolation
Jun 10, 2025Training advanced machine learning models demands massive datasets, resulting in prohibitive computational costs. To address this challenge, data pruning techniques identify and remove redundant training samples while preserving model performance. Yet, existing pruning techniques predominantly require a full initial training pass to identify removable samples, negating any efficiency benefits for single training runs. To overcome this limitation, we introduce a novel importance score extrapolation framework that requires training on only a small subset of data. We present two initial approaches in this framework - k-nearest neighbors and graph neural networks - to accurately predict sample importance for the entire dataset using patterns learned from this minimal subset. We demonstrate the effectiveness of our approach for 2 state-of-the-art pruning methods (Dynamic Uncertainty and TDDS), 4 different datasets (CIFAR-10, CIFAR-100, Places-365, and ImageNet), and 3 training paradigms (supervised, unsupervised, and adversarial). Our results indicate that score extrapolation is a promising direction to scale expensive score calculation methods, such as pruning, data attribution, or other tasks.
IALE: Imitating Active Learner Ensembles
Jul 09, 2020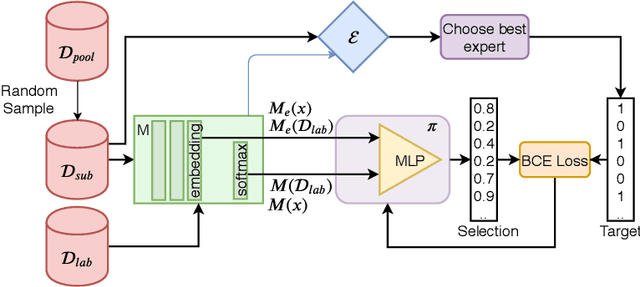

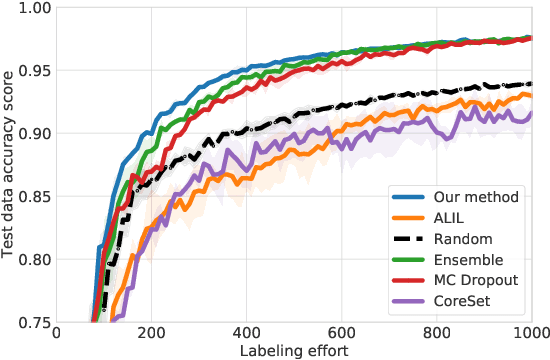
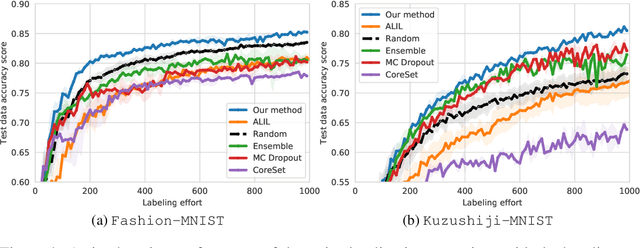
Active learning (AL) prioritizes the labeling of the most informative data samples. As the performance of well-known AL heuristics highly depends on the underlying model and data, recent heuristic-independent approaches that are based on reinforcement learning directly learn a policy that makes use of the labeling history to select the next sample. However, those methods typically need a huge number of samples to sufficiently explore the relevant state space. Imitation learning approaches aim to help out but again rely on a given heuristic. This paper proposes an improved imitation learning scheme that learns a policy for batch-mode pool-based AL. This is similar to previously presented multi-armed bandit approaches but in contrast to them we train a policy that imitates the selection of the best expert heuristic at each stage of the AL cycle directly. We use DAGGER to train the policy on a dataset and later apply it to similar datasets. With multiple AL heuristics as experts, the policy is able to reflect the choices of the best AL heuristics given the current state of the active learning process. We evaluate our method on well-known image datasets and show that we outperform state of the art imitation learners and heuristics.
ViPR: Visual-Odometry-aided Pose Regression for 6DoF Camera Localization
Dec 24, 2019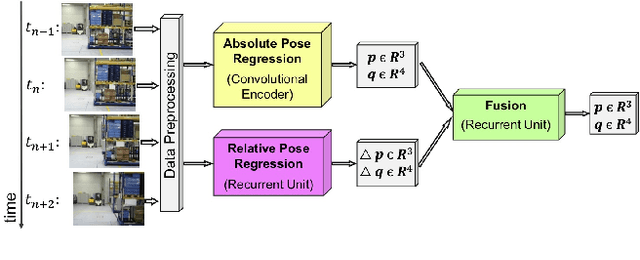
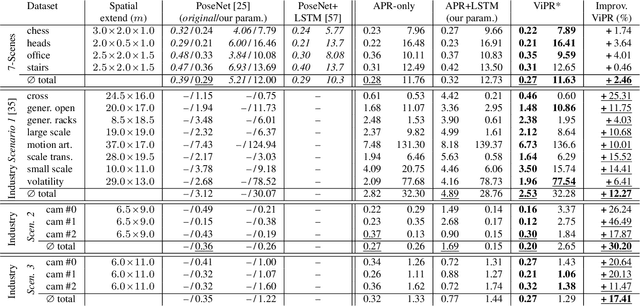

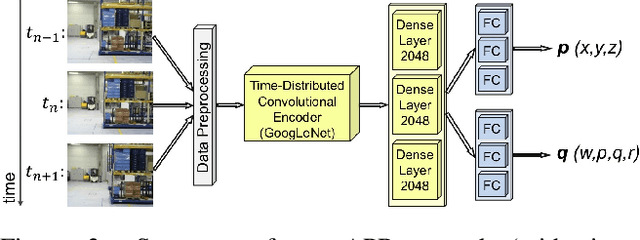
Visual Odometry (VO) accumulates a positional drift in long-term robot navigation tasks. Although Convolutional Neural Networks (CNNs) improve VO in various aspects, VO still suffers from moving obstacles, discontinuous observation of features, and poor textures or visual information. While recent approaches estimate a 6DoF pose either directly from (a series of) images or by merging depth maps with the optical flow (OF), research that combines absolute pose regression with OF is limited. We propose ViPR, a novel architecture for long-term 6DoF VO that leverages synergies between absolute pose estimates (from PoseNet-like architectures) and relative pose estimates (from FlowNet-based architectures) by combining both through recurrent layers. Experiments with known publicly available datasets and with our own Industry dataset show that our novel design outperforms existing techniques in long-term navigation tasks.