 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Attentive Backtracking: Long-Range Credit Assignment in Recurrent Networks
Nov 07, 2017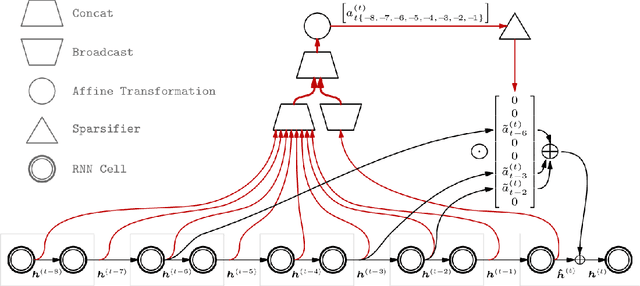
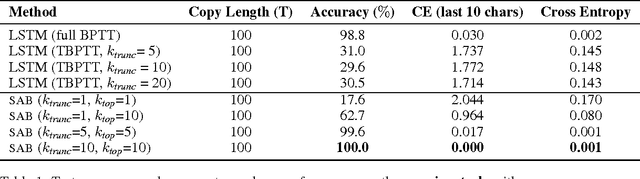
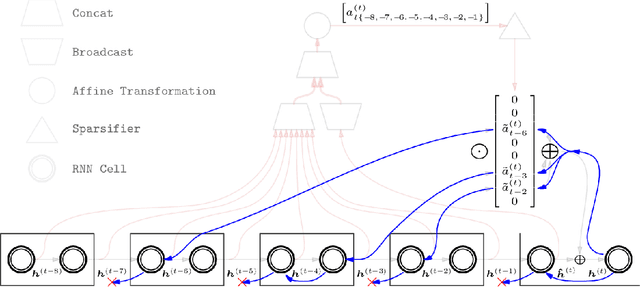
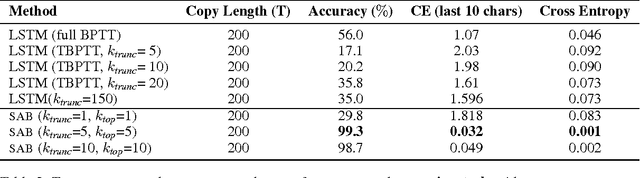
A major drawback of backpropagation through time (BPTT) is the difficulty of learning long-term dependencies, coming from having to propagate credit information backwards through every single step of the forward computation. This makes BPTT both computationally impractical and biologically implausible. For this reason, full backpropagation through time is rarely used on long sequences, and truncated backpropagation through time is used as a heuristic. However, this usually leads to biased estimates of the gradient in which longer term dependencies are ignored. Addressing this issue, we propose an alternative algorithm, Sparse Attentive Backtracking, which might also be related to principles used by brains to learn long-term dependencies. Sparse Attentive Backtracking learns an attention mechanism over the hidden states of the past and selectively backpropagates through paths with high attention weights. This allows the model to learn long term dependencies while only backtracking for a small number of time steps, not just from the recent past but also from attended relevant past states.
On orthogonality and learning recurrent networks with long term dependencies
Oct 12, 2017
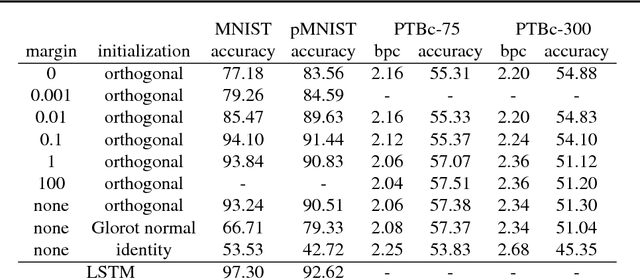
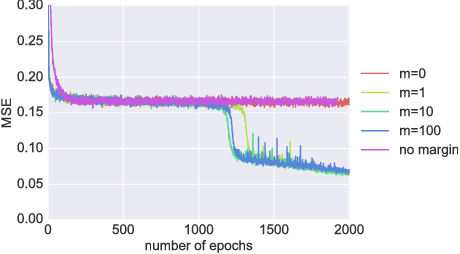
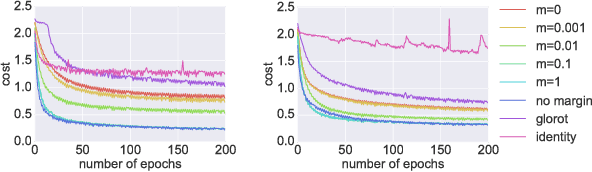
It is well known that it is challenging to train deep neural networks and recurrent neural networks for tasks that exhibit long term dependencies. The vanishing or exploding gradient problem is a well known issue associated with these challenges. One approach to addressing vanishing and exploding gradients is to use either soft or hard constraints on weight matrices so as to encourage or enforce orthogonality. Orthogonal matrices preserve gradient norm during backpropagation and may therefore be a desirable property. This paper explores issues with optimization convergence, speed and gradient stability when encouraging or enforcing orthogonality. To perform this analysis, we propose a weight matrix factorization and parameterization strategy through which we can bound matrix norms and therein control the degree of expansivity induced during backpropagation. We find that hard constraints on orthogonality can negatively affect the speed of convergence and model performance.
Zoneout: Regularizing RNNs by Randomly Preserving Hidden Activations
Sep 22, 2017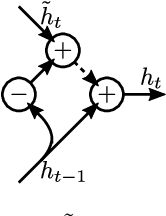
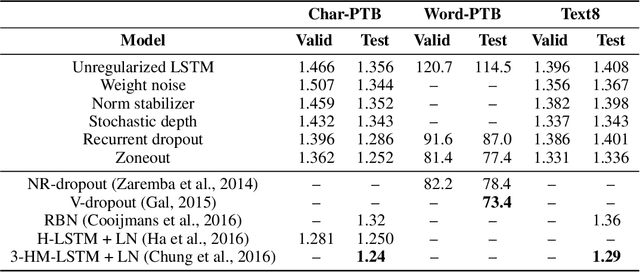
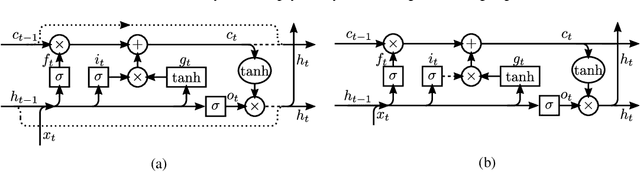

We propose zoneout, a novel method for regularizing RNNs. At each timestep, zoneout stochastically forces some hidden units to maintain their previous values. Like dropout, zoneout uses random noise to train a pseudo-ensemble, improving generalization. But by preserving instead of dropping hidden units, gradient information and state information are more readily propagated through time, as in feedforward stochastic depth networks. We perform an empirical investigation of various RNN regularizers, and find that zoneout gives significant performance improvements across tasks. We achieve competitive results with relatively simple models in character- and word-level language modelling on the Penn Treebank and Text8 datasets, and combining with recurrent batch normalization yields state-of-the-art results on permuted sequential MNIST.
Learning Normalized Inputs for Iterative Estimation in Medical Image Segmentation
Feb 16, 2017
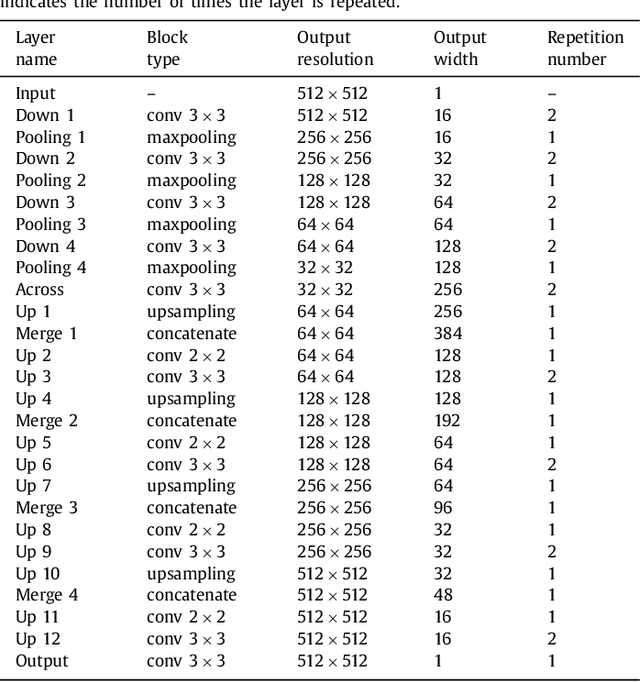
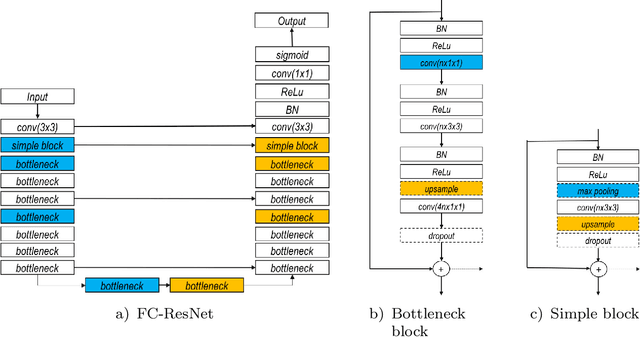
In this paper, we introduce a simple, yet powerful pipeline for medical image segmentation that combines Fully Convolutional Networks (FCNs) with Fully Convolutional Residual Networks (FC-ResNets). We propose and examine a design that takes particular advantage of recent advances in the understanding of both Convolutional Neural Networks as well as ResNets. Our approach focuses upon the importance of a trainable pre-processing when using FC-ResNets and we show that a low-capacity FCN model can serve as a pre-processor to normalize medical input data. In our image segmentation pipeline, we use FCNs to obtain normalized images, which are then iteratively refined by means of a FC-ResNet to generate a segmentation prediction. As in other fully convolutional approaches, our pipeline can be used off-the-shelf on different image modalities. We show that using this pipeline, we exhibit state-of-the-art performance on the challenging Electron Microscopy benchmark, when compared to other 2D methods. We improve segmentation results on CT images of liver lesions, when contrasting with standard FCN methods. Moreover, when applying our 2D pipeline on a challenging 3D MRI prostate segmentation challenge we reach results that are competitive even when compared to 3D methods. The obtained results illustrate the strong potential and versatility of the pipeline by achieving highly accurate results on multi-modality images from different anatomical regions and organs.
The Importance of Skip Connections in Biomedical Image Segmentation
Sep 22, 2016

In this paper, we study the influence of both long and short skip connections on Fully Convolutional Networks (FCN) for biomedical image segmentation. In standard FCNs, only long skip connections are used to skip features from the contracting path to the expanding path in order to recover spatial information lost during downsampling. We extend FCNs by adding short skip connections, that are similar to the ones introduced in residual networks, in order to build very deep FCNs (of hundreds of layers). A review of the gradient flow confirms that for a very deep FCN it is beneficial to have both long and short skip connections. Finally, we show that a very deep FCN can achieve near-to-state-of-the-art results on the EM dataset without any further post-processing.
Improving Facial Analysis and Performance Driven Animation through Disentangling Identity and Expression
May 22, 2016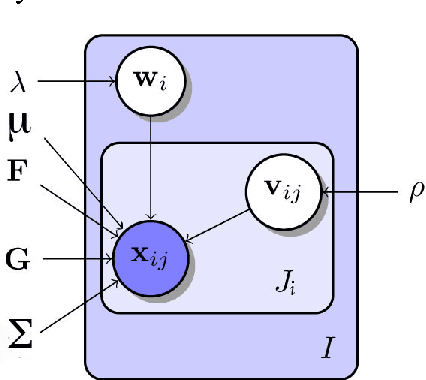
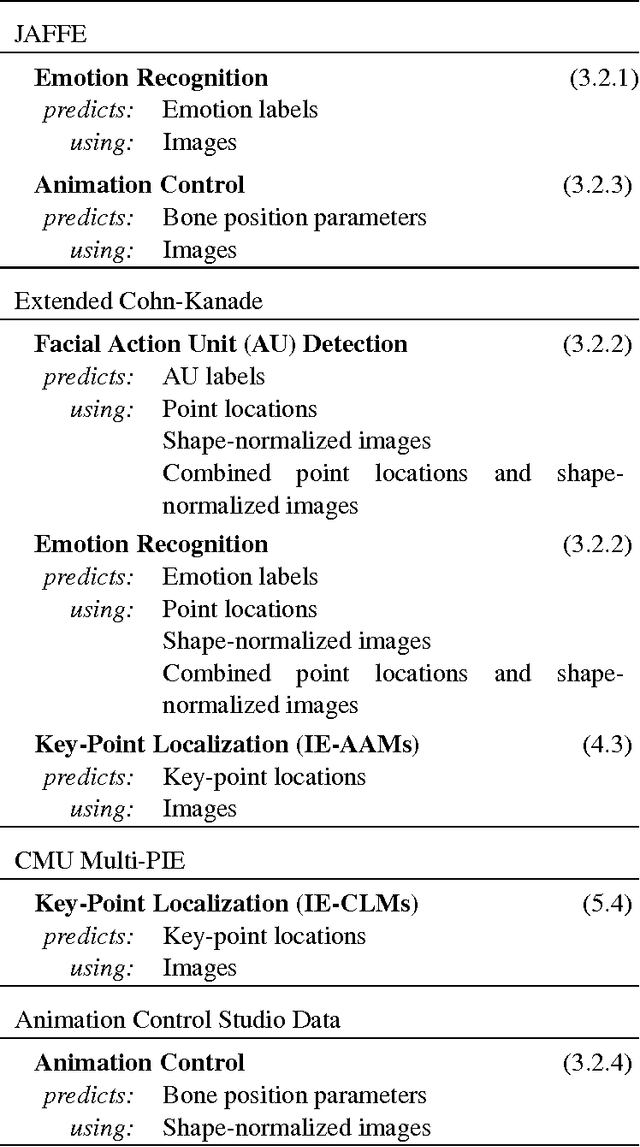

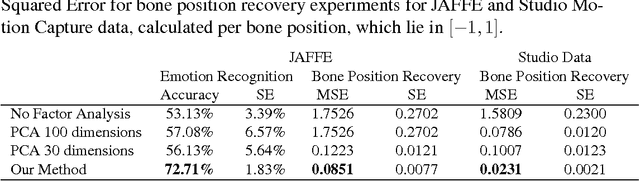
We present techniques for improving performance driven facial animation, emotion recognition, and facial key-point or landmark prediction using learned identity invariant representations. Established approaches to these problems can work well if sufficient examples and labels for a particular identity are available and factors of variation are highly controlled. However, labeled examples of facial expressions, emotions and key-points for new individuals are difficult and costly to obtain. In this paper we improve the ability of techniques to generalize to new and unseen individuals by explicitly modeling previously seen variations related to identity and expression. We use a weakly-supervised approach in which identity labels are used to learn the different factors of variation linked to identity separately from factors related to expression. We show how probabilistic modeling of these sources of variation allows one to learn identity-invariant representations for expressions which can then be used to identity-normalize various procedures for facial expression analysis and animation control. We also show how to extend the widely used techniques of active appearance models and constrained local models through replacing the underlying point distribution models which are typically constructed using principal component analysis with identity-expression factorized representations. We present a wide variety of experiments in which we consistently improve performance on emotion recognition, markerless performance-driven facial animation and facial key-point tracking.
Brain Tumor Segmentation with Deep Neural Networks
May 20, 2016
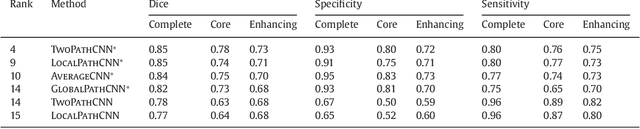
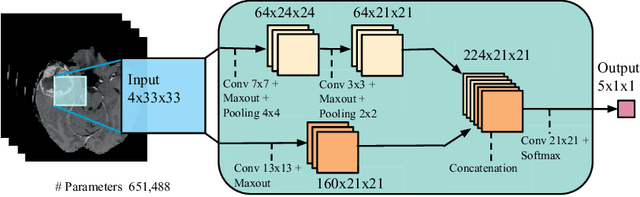

In this paper, we present a fully automatic brain tumor segmentation method based on Deep Neural Networks (DNNs). The proposed networks are tailored to glioblastomas (both low and high grade) pictured in MR images. By their very nature, these tumors can appear anywhere in the brain and have almost any kind of shape, size, and contrast. These reasons motivate our exploration of a machine learning solution that exploits a flexible, high capacity DNN while being extremely efficient. Here, we give a description of different model choices that we've found to be necessary for obtaining competitive performance. We explore in particular different architectures based on Convolutional Neural Networks (CNN), i.e. DNNs specifically adapted to image data. We present a novel CNN architecture which differs from those traditionally used in computer vision. Our CNN exploits both local features as well as more global contextual features simultaneously. Also, different from most traditional uses of CNNs, our networks use a final layer that is a convolutional implementation of a fully connected layer which allows a 40 fold speed up. We also describe a 2-phase training procedure that allows us to tackle difficulties related to the imbalance of tumor labels. Finally, we explore a cascade architecture in which the output of a basic CNN is treated as an additional source of information for a subsequent CNN. Results reported on the 2013 BRATS test dataset reveal that our architecture improves over the currently published state-of-the-art while being over 30 times faster.
Delving Deeper into Convolutional Networks for Learning Video Representations
Mar 01, 2016

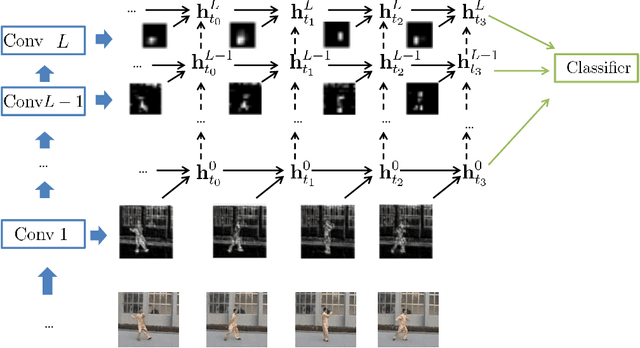
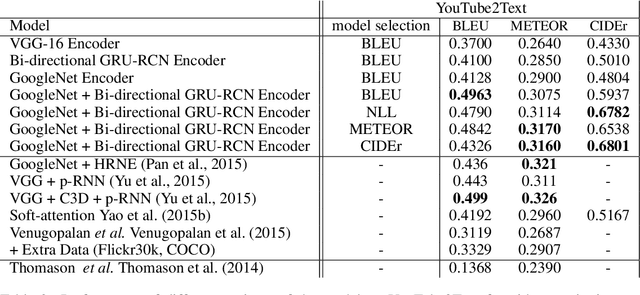
We propose an approach to learn spatio-temporal features in videos from intermediate visual representations we call "percepts" using Gated-Recurrent-Unit Recurrent Networks (GRUs).Our method relies on percepts that are extracted from all level of a deep convolutional network trained on the large ImageNet dataset. While high-level percepts contain highly discriminative information, they tend to have a low-spatial resolution. Low-level percepts, on the other hand, preserve a higher spatial resolution from which we can model finer motion patterns. Using low-level percepts can leads to high-dimensionality video representations. To mitigate this effect and control the model number of parameters, we introduce a variant of the GRU model that leverages the convolution operations to enforce sparse connectivity of the model units and share parameters across the input spatial locations. We empirically validate our approach on both Human Action Recognition and Video Captioning tasks. In particular, we achieve results equivalent to state-of-art on the YouTube2Text dataset using a simpler text-decoder model and without extra 3D CNN features.