 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProblems With Evaluation of Word Embeddings Using Word Similarity Tasks
Jun 22, 2016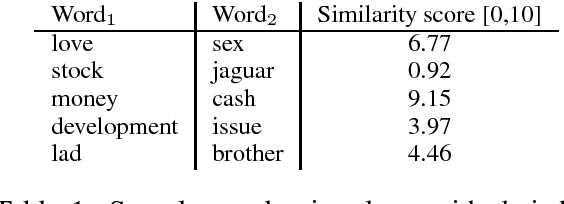
Lacking standardized extrinsic evaluation methods for vector representations of words, the NLP community has relied heavily on word similarity tasks as a proxy for intrinsic evaluation of word vectors. Word similarity evaluation, which correlates the distance between vectors and human judgments of semantic similarity is attractive, because it is computationally inexpensive and fast. In this paper we present several problems associated with the evaluation of word vectors on word similarity datasets, and summarize existing solutions. Our study suggests that the use of word similarity tasks for evaluation of word vectors is not sustainable and calls for further research on evaluation methods.
Correlation-based Intrinsic Evaluation of Word Vector Representations
Jun 21, 2016

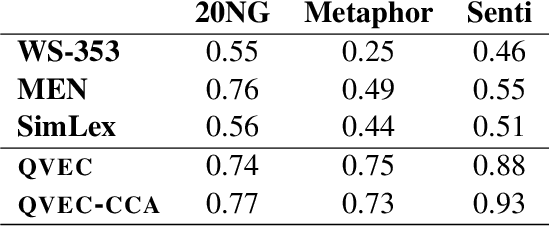
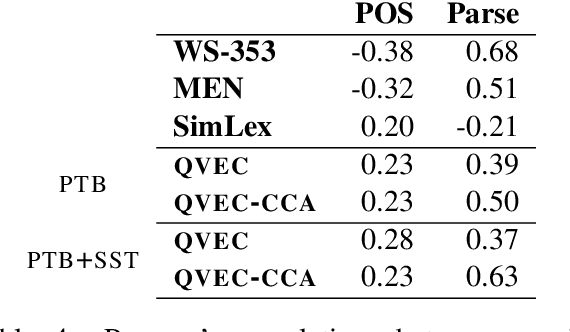
We introduce QVEC-CCA--an intrinsic evaluation metric for word vector representations based on correlations of learned vectors with features extracted from linguistic resources. We show that QVEC-CCA scores are an effective proxy for a range of extrinsic semantic and syntactic tasks. We also show that the proposed evaluation obtains higher and more consistent correlations with downstream tasks, compared to existing approaches to intrinsic evaluation of word vectors that are based on word similarity.
Learning the Curriculum with Bayesian Optimization for Task-Specific Word Representation Learning
Jun 21, 2016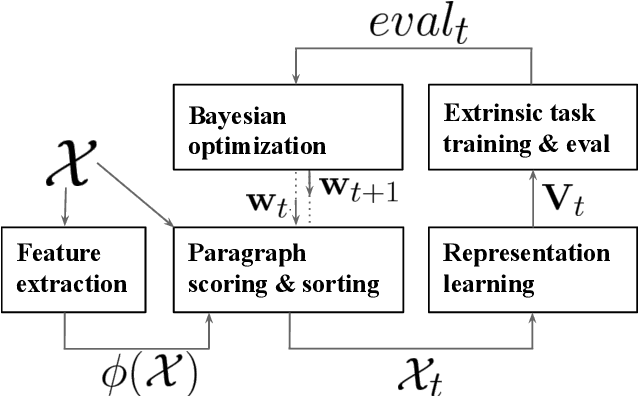
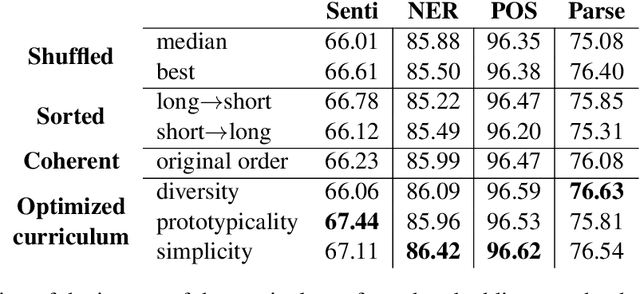
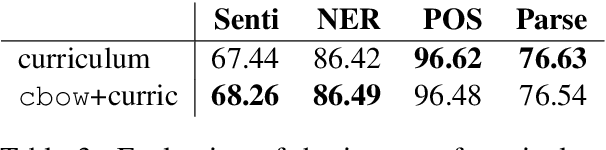
We use Bayesian optimization to learn curricula for word representation learning, optimizing performance on downstream tasks that depend on the learned representations as features. The curricula are modeled by a linear ranking function which is the scalar product of a learned weight vector and an engineered feature vector that characterizes the different aspects of the complexity of each instance in the training corpus. We show that learning the curriculum improves performance on a variety of downstream tasks over random orders and in comparison to the natural corpus order.
Segmental Recurrent Neural Networks for End-to-end Speech Recognition
Jun 20, 2016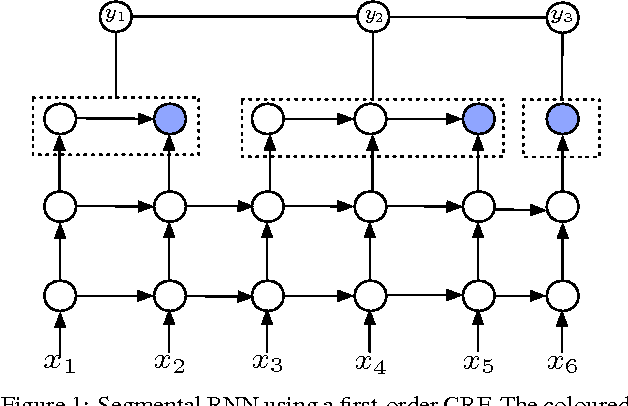

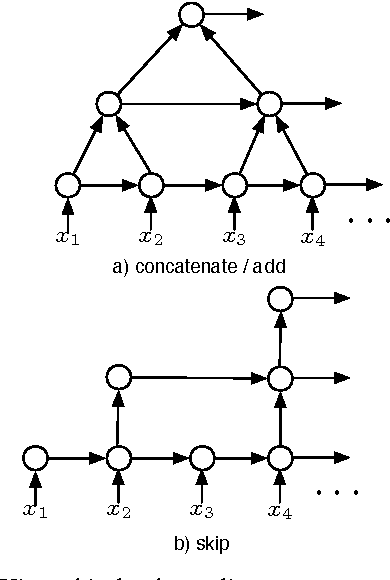
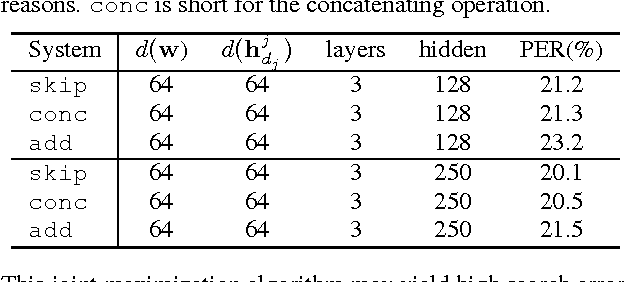
We study the segmental recurrent neural network for end-to-end acoustic modelling. This model connects the segmental conditional random field (CRF) with a recurrent neural network (RNN) used for feature extraction. Compared to most previous CRF-based acoustic models, it does not rely on an external system to provide features or segmentation boundaries. Instead, this model marginalises out all the possible segmentations, and features are extracted from the RNN trained together with the segmental CRF. In essence, this model is self-contained and can be trained end-to-end. In this paper, we discuss practical training and decoding issues as well as the method to speed up the training in the context of speech recognition. We performed experiments on the TIMIT dataset. We achieved 17.3 phone error rate (PER) from the first-pass decoding --- the best reported result using CRFs, despite the fact that we only used a zeroth-order CRF and without using any language model.
Cross-lingual Models of Word Embeddings: An Empirical Comparison
Jun 08, 2016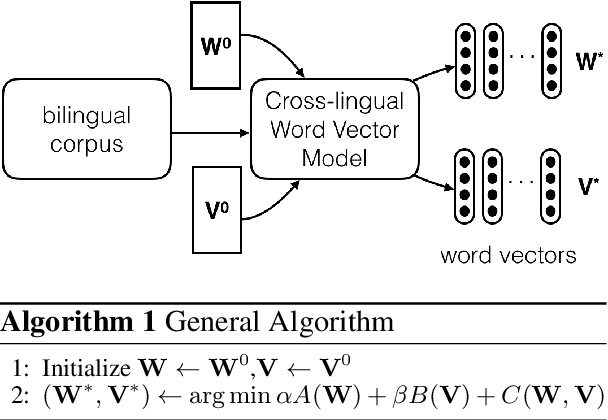
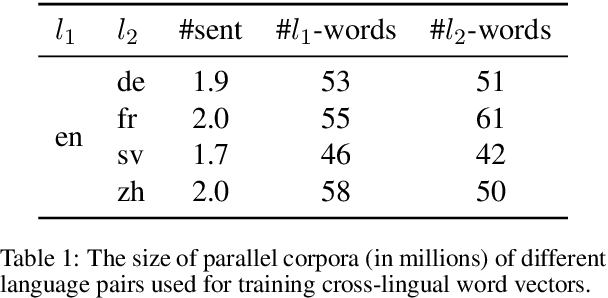

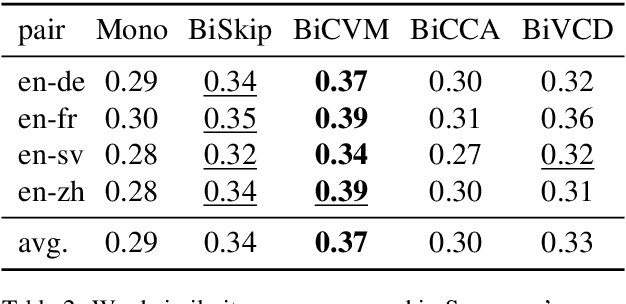
Despite interest in using cross-lingual knowledge to learn word embeddings for various tasks, a systematic comparison of the possible approaches is lacking in the literature. We perform an extensive evaluation of four popular approaches of inducing cross-lingual embeddings, each requiring a different form of supervision, on four typographically different language pairs. Our evaluation setup spans four different tasks, including intrinsic evaluation on mono-lingual and cross-lingual similarity, and extrinsic evaluation on downstream semantic and syntactic applications. We show that models which require expensive cross-lingual knowledge almost always perform better, but cheaply supervised models often prove competitive on certain tasks.
Finding Function in Form: Compositional Character Models for Open Vocabulary Word Representation
May 23, 2016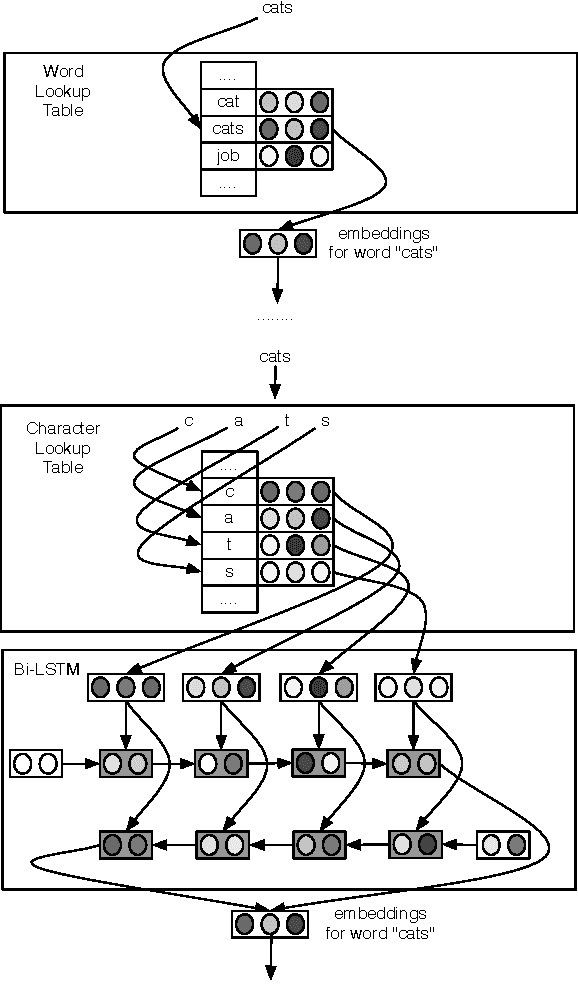
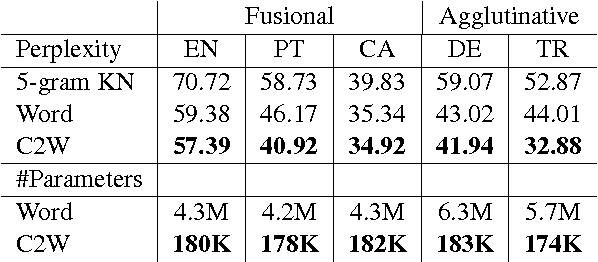
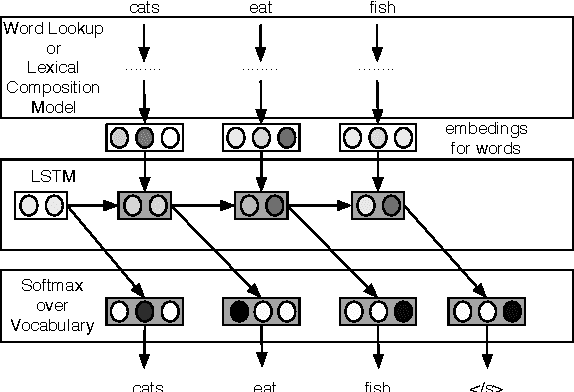

We introduce a model for constructing vector representations of words by composing characters using bidirectional LSTMs. Relative to traditional word representation models that have independent vectors for each word type, our model requires only a single vector per character type and a fixed set of parameters for the compositional model. Despite the compactness of this model and, more importantly, the arbitrary nature of the form-function relationship in language, our "composed" word representations yield state-of-the-art results in language modeling and part-of-speech tagging. Benefits over traditional baselines are particularly pronounced in morphologically rich languages (e.g., Turkish).
Massively Multilingual Word Embeddings
May 21, 2016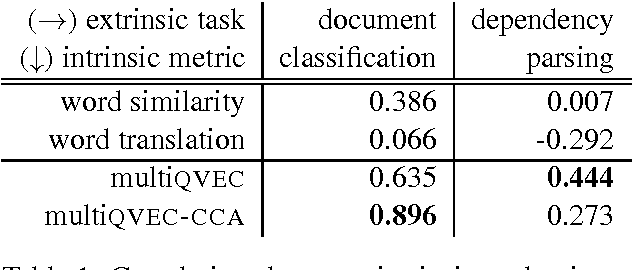
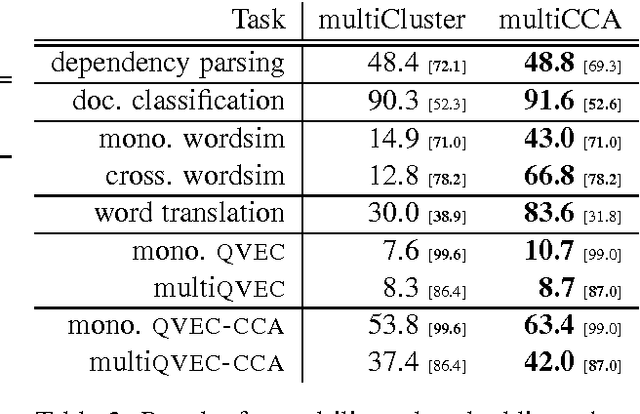
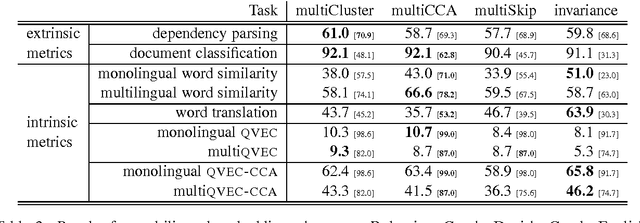
We introduce new methods for estimating and evaluating embeddings of words in more than fifty languages in a single shared embedding space. Our estimation methods, multiCluster and multiCCA, use dictionaries and monolingual data; they do not require parallel data. Our new evaluation method, multiQVEC-CCA, is shown to correlate better than previous ones with two downstream tasks (text categorization and parsing). We also describe a web portal for evaluation that will facilitate further research in this area, along with open-source releases of all our methods.
Polyglot Neural Language Models: A Case Study in Cross-Lingual Phonetic Representation Learning
May 12, 2016



We introduce polyglot language models, recurrent neural network models trained to predict symbol sequences in many different languages using shared representations of symbols and conditioning on typological information about the language to be predicted. We apply these to the problem of modeling phone sequences---a domain in which universal symbol inventories and cross-linguistically shared feature representations are a natural fit. Intrinsic evaluation on held-out perplexity, qualitative analysis of the learned representations, and extrinsic evaluation in two downstream applications that make use of phonetic features show (i) that polyglot models better generalize to held-out data than comparable monolingual models and (ii) that polyglot phonetic feature representations are of higher quality than those learned monolingually.
Neural Architectures for Named Entity Recognition
Apr 07, 2016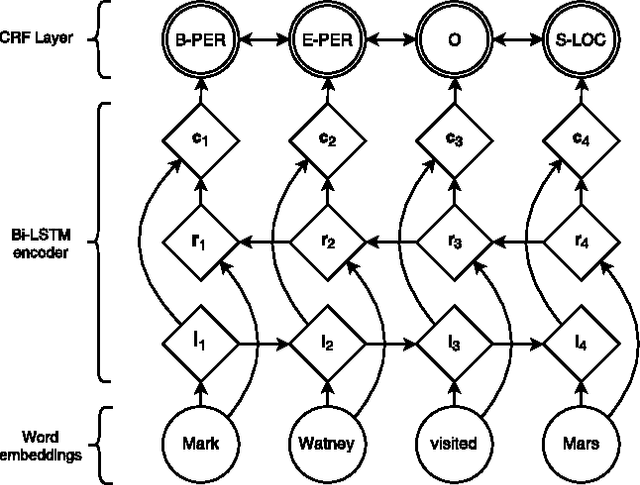
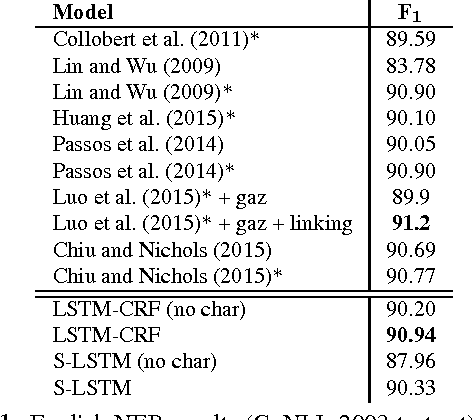

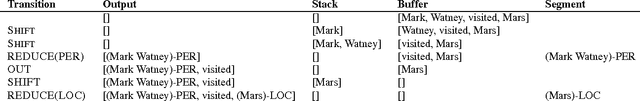
State-of-the-art named entity recognition systems rely heavily on hand-crafted features and domain-specific knowledge in order to learn effectively from the small, supervised training corpora that are available. In this paper, we introduce two new neural architectures---one based on bidirectional LSTMs and conditional random fields, and the other that constructs and labels segments using a transition-based approach inspired by shift-reduce parsers. Our models rely on two sources of information about words: character-based word representations learned from the supervised corpus and unsupervised word representations learned from unannotated corpora. Our models obtain state-of-the-art performance in NER in four languages without resorting to any language-specific knowledge or resources such as gazetteers.
Morphological Inflection Generation Using Character Sequence to Sequence Learning
Mar 22, 2016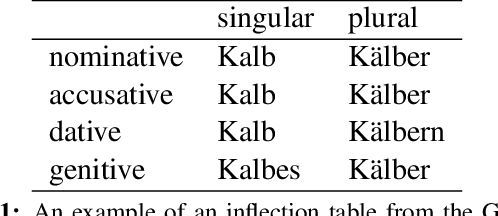
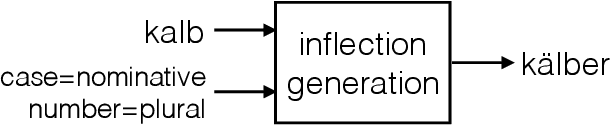
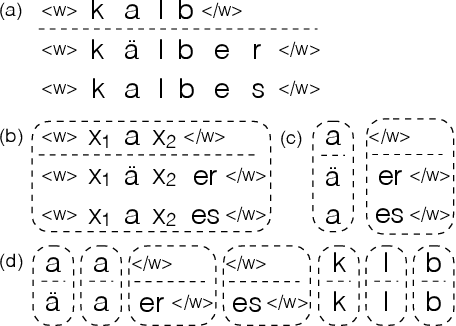

Morphological inflection generation is the task of generating the inflected form of a given lemma corresponding to a particular linguistic transformation. We model the problem of inflection generation as a character sequence to sequence learning problem and present a variant of the neural encoder-decoder model for solving it. Our model is language independent and can be trained in both supervised and semi-supervised settings. We evaluate our system on seven datasets of morphologically rich languages and achieve either better or comparable results to existing state-of-the-art models of inflection generation.