 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Segment Actions from Observation and Narration
May 07, 2020

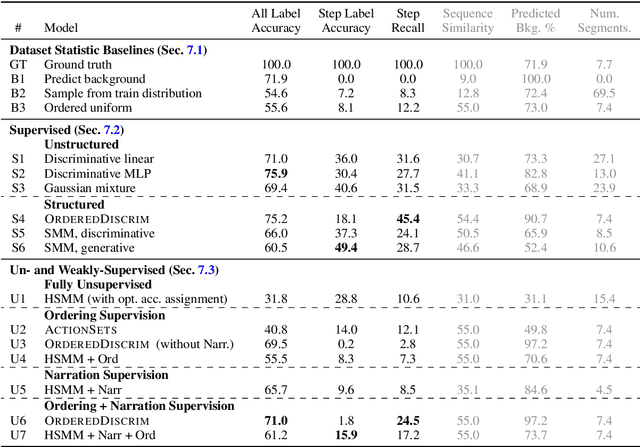
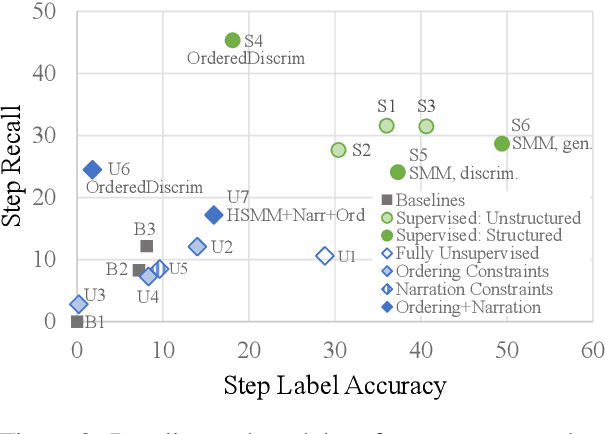
We apply a generative segmental model of task structure, guided by narration, to action segmentation in video. We focus on unsupervised and weakly-supervised settings where no action labels are known during training. Despite its simplicity, our model performs competitively with previous work on a dataset of naturalistic instructional videos. Our model allows us to vary the sources of supervision used in training, and we find that both task structure and narrative language provide large benefits in segmentation quality.
A Probabilistic Generative Model for Typographical Analysis of Early Modern Printing
May 04, 2020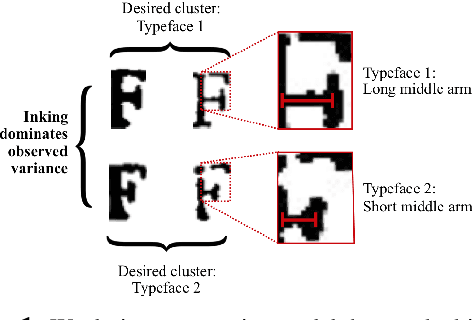
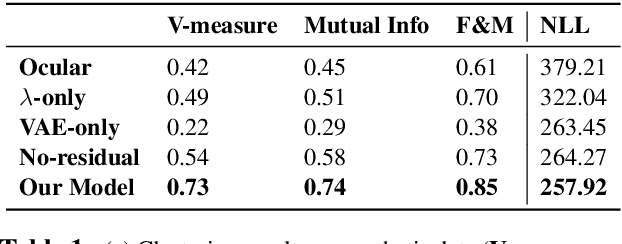
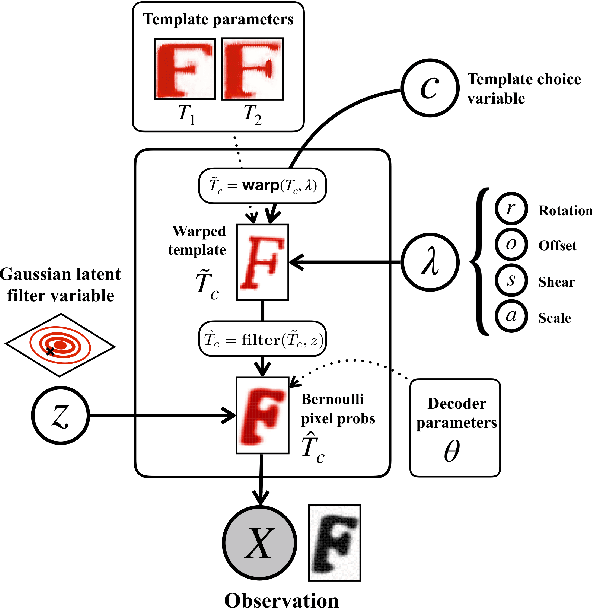
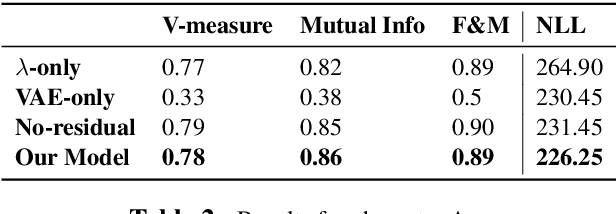
We propose a deep and interpretable probabilistic generative model to analyze glyph shapes in printed Early Modern documents. We focus on clustering extracted glyph images into underlying templates in the presence of multiple confounding sources of variance. Our approach introduces a neural editor model that first generates well-understood printing phenomena like spatial perturbations from template parameters via interpertable latent variables, and then modifies the result by generating a non-interpretable latent vector responsible for inking variations, jitter, noise from the archiving process, and other unforeseen phenomena associated with Early Modern printing. Critically, by introducing an inference network whose input is restricted to the visual residual between the observation and the interpretably-modified template, we are able to control and isolate what the vector-valued latent variable captures. We show that our approach outperforms rigid interpretable clustering baselines (Ocular) and overly-flexible deep generative models (VAE) alike on the task of completely unsupervised discovery of typefaces in mixed-font documents.
Learning Robust and Multilingual Speech Representations
Jan 29, 2020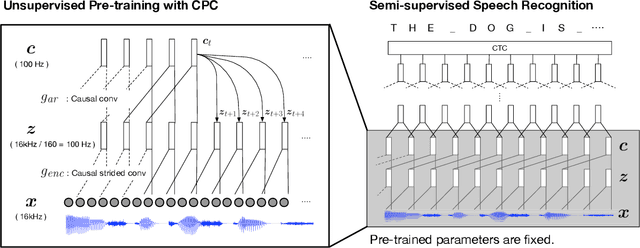
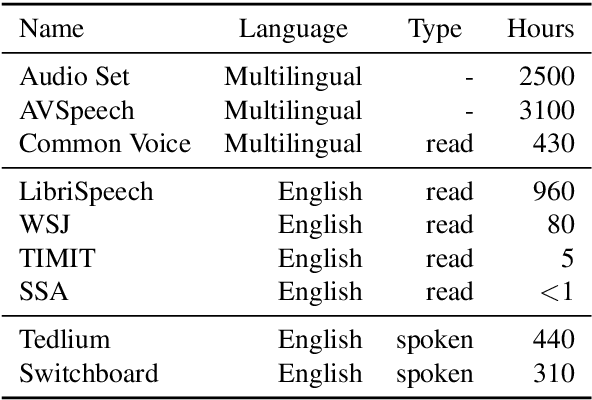
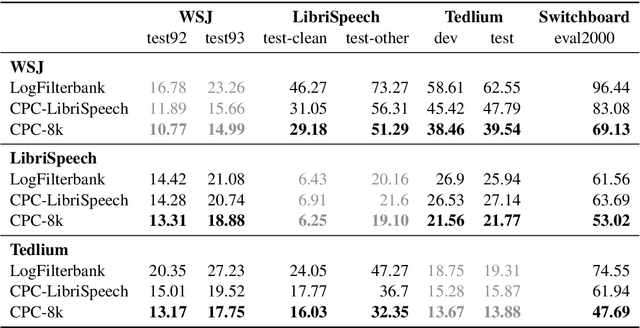
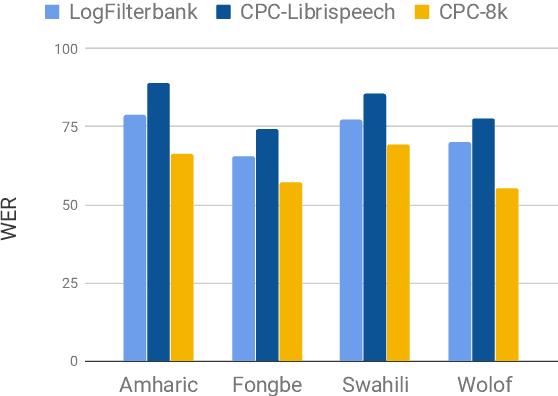
Unsupervised speech representation learning has shown remarkable success at finding representations that correlate with phonetic structures and improve downstream speech recognition performance. However, most research has been focused on evaluating the representations in terms of their ability to improve the performance of speech recognition systems on read English (e.g. Wall Street Journal and LibriSpeech). This evaluation methodology overlooks two important desiderata that speech representations should have: robustness to domain shifts and transferability to other languages. In this paper we learn representations from up to 8000 hours of diverse and noisy speech data and evaluate the representations by looking at their robustness to domain shifts and their ability to improve recognition performance in many languages. We find that our representations confer significant robustness advantages to the resulting recognition systems: we see significant improvements in out-of-domain transfer relative to baseline feature sets and the features likewise provide improvements in 25 phonetically diverse languages including tonal languages and low-resource languages.
Transition-Based Dependency Parsing using Perceptron Learner
Jan 28, 2020
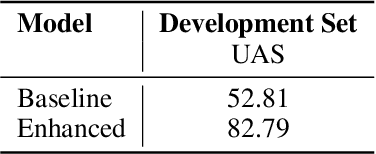
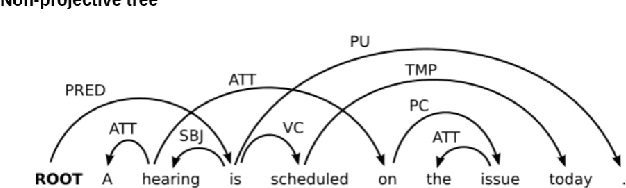
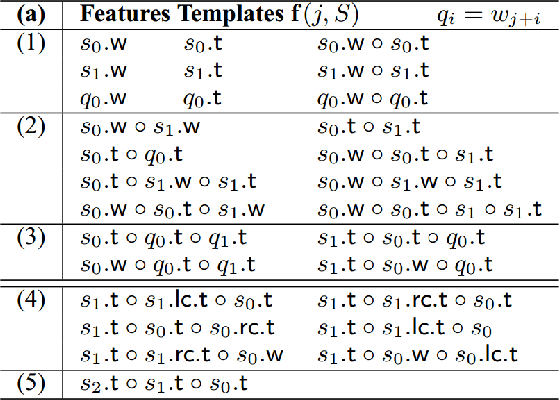
Syntactic parsing using dependency structures has become a standard technique in natural language processing with many different parsing models, in particular data-driven models that can be trained on syntactically annotated corpora. In this paper, we tackle transition-based dependency parsing using a Perceptron Learner. Our proposed model, which adds more relevant features to the Perceptron Learner, outperforms a baseline arc-standard parser. We beat the UAS of the MALT and LSTM parsers. We also give possible ways to address parsing of non-projective trees.
Putting Machine Translation in Context with the Noisy Channel Model
Oct 01, 2019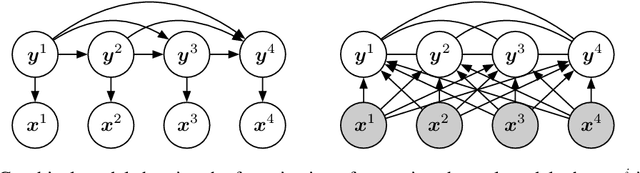
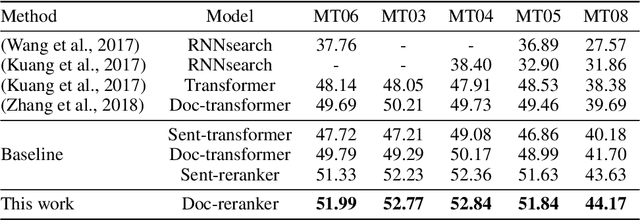
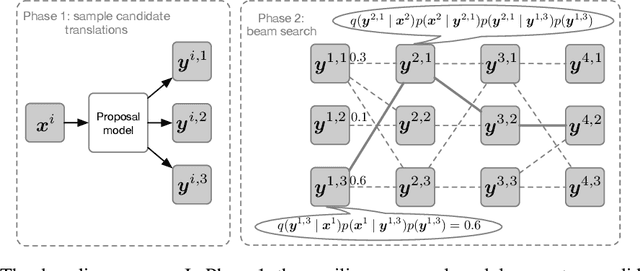

We show that Bayes' rule provides a compelling mechanism for controlling unconditional document language models, using the long-standing challenge of effectively leveraging document context in machine translation. In our formulation, we estimate the probability of a candidate translation as the product of the unconditional probability of the candidate output document and the ``reverse translation probability'' of translating the candidate output back into the input source language document---the so-called ``noisy channel'' decomposition. A particular advantage of our model is that it requires only parallel sentences to train, rather than parallel documents, which are not always available. Using a new beam search reranking approximation to solve the decoding problem, we find that document language models outperform language models that assume independence between sentences, and that using either a document or sentence language model outperforms comparable models that directly estimate the translation probability. We obtain the best-published results on the NIST Chinese--English translation task, a standard task for evaluating document translation. Our model also outperforms the benchmark Transformer model by approximately 2.5 BLEU on the WMT19 Chinese--English translation task.
A Critical Analysis of Biased Parsers in Unsupervised Parsing
Sep 20, 2019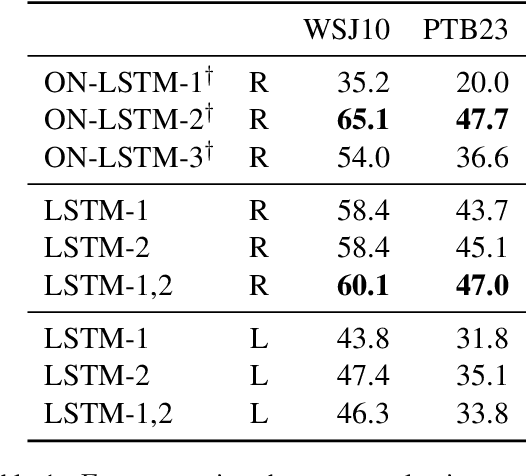
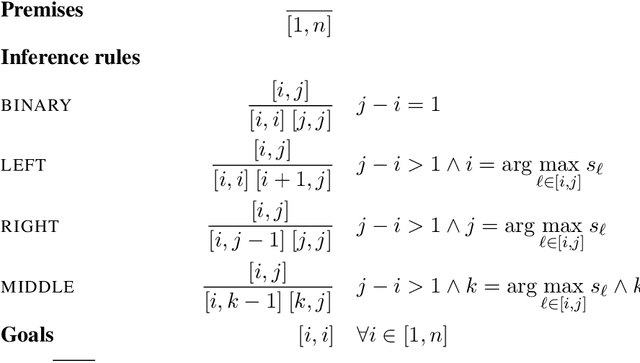
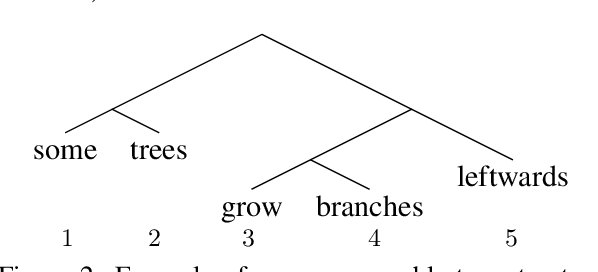

A series of recent papers has used a parsing algorithm due to Shen et al. (2018) to recover phrase-structure trees based on proxies for "syntactic depth." These proxy depths are obtained from the representations learned by recurrent language models augmented with mechanisms that encourage the (unsupervised) discovery of hierarchical structure latent in natural language sentences. Using the same parser, we show that proxies derived from a conventional LSTM language model produce trees comparably well to the specialized architectures used in previous work. However, we also provide a detailed analysis of the parsing algorithm, showing (1) that it is incomplete---that is, it can recover only a fraction of possible trees---and (2) that it has a marked bias for right-branching structures which results in inflated performance in right-branching languages like English. Our analysis shows that evaluating with biased parsing algorithms can inflate the apparent structural competence of language models.
Achieving Verified Robustness to Symbol Substitutions via Interval Bound Propagation
Sep 03, 2019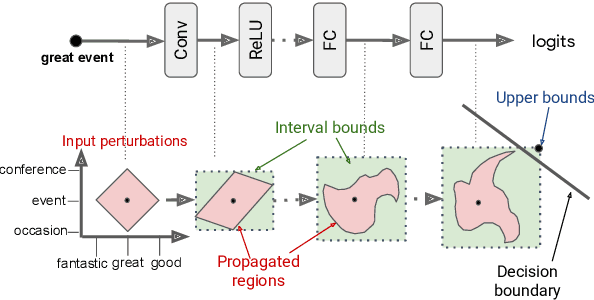


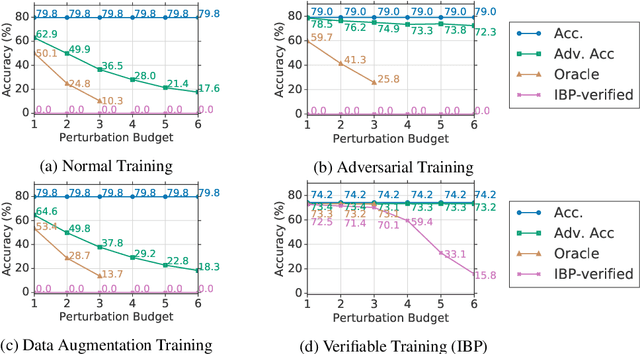
Neural networks are part of many contemporary NLP systems, yet their empirical successes come at the price of vulnerability to adversarial attacks. Previous work has used adversarial training and data augmentation to partially mitigate such brittleness, but these are unlikely to find worst-case adversaries due to the complexity of the search space arising from discrete text perturbations. In this work, we approach the problem from the opposite direction: to formally verify a system's robustness against a predefined class of adversarial attacks. We study text classification under synonym replacements or character flip perturbations. We propose modeling these input perturbations as a simplex and then using Interval Bound Propagation -- a formal model verification method. We modify the conventional log-likelihood training objective to train models that can be efficiently verified, which would otherwise come with exponential search complexity. The resulting models show only little difference in terms of nominal accuracy, but have much improved verified accuracy under perturbations and come with an efficiently computable formal guarantee on worst case adversaries.
Shallow Syntax in Deep Water
Aug 29, 2019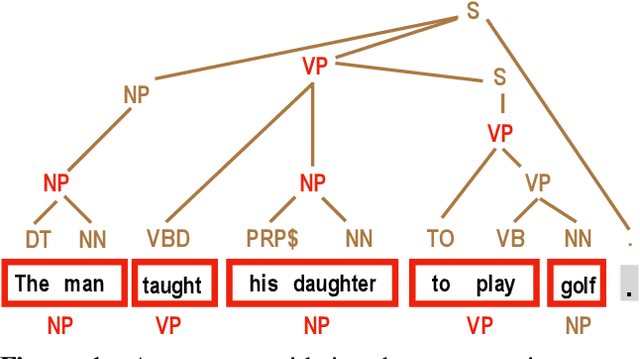
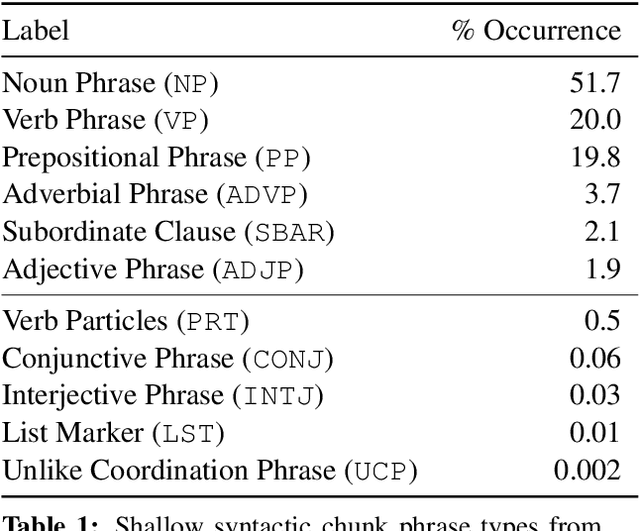
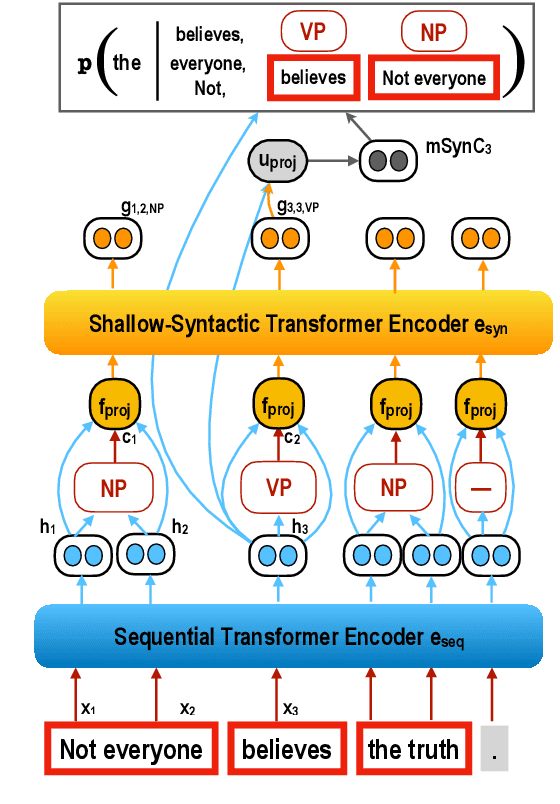
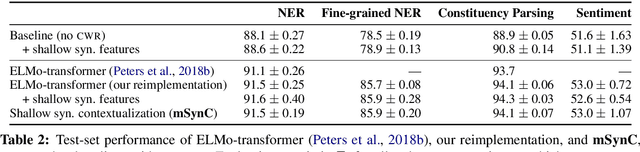
Shallow syntax provides an approximation of phrase-syntactic structure of sentences; it can be produced with high accuracy, and is computationally cheap to obtain. We investigate the role of shallow syntax-aware representations for NLP tasks using two techniques. First, we enhance the ELMo architecture to allow pretraining on predicted shallow syntactic parses, instead of just raw text, so that contextual embeddings make use of shallow syntactic context. Our second method involves shallow syntactic features obtained automatically on downstream task data. Neither approach leads to a significant gain on any of the four downstream tasks we considered relative to ELMo-only baselines. Further analysis using black-box probes confirms that our shallow-syntax-aware contextual embeddings do not transfer to linguistic tasks any more easily than ELMo's embeddings. We take these findings as evidence that ELMo-style pretraining discovers representations which make additional awareness of shallow syntax redundant.
Compound Probabilistic Context-Free Grammars for Grammar Induction
Aug 18, 2019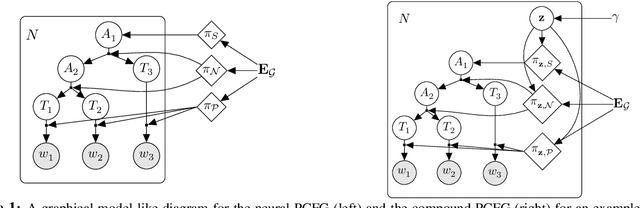
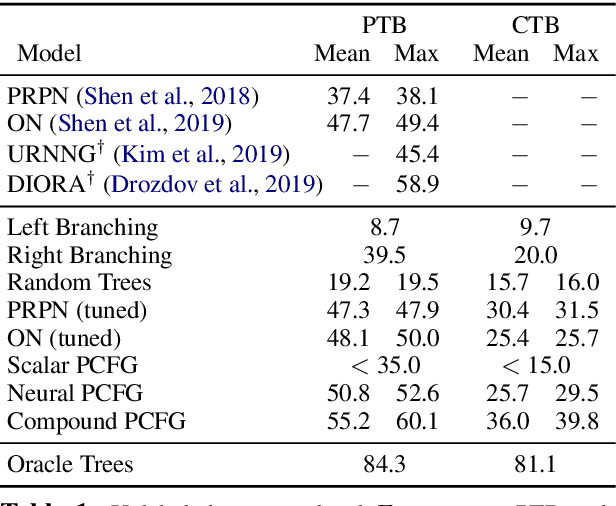
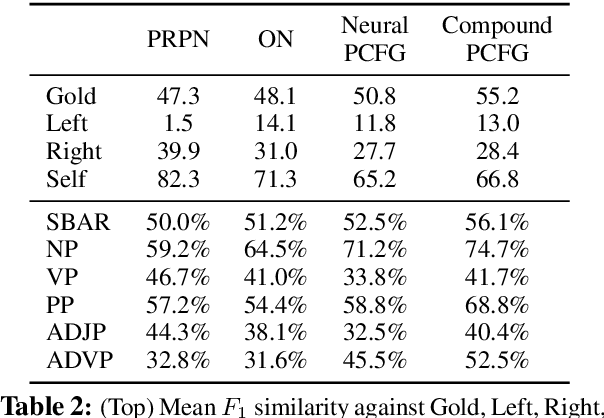

We study a formalization of the grammar induction problem that models sentences as being generated by a compound probabilistic context-free grammar. In contrast to traditional formulations which learn a single stochastic grammar, our context-free rule probabilities are modulated by a per-sentence continuous latent variable, which induces marginal dependencies beyond the traditional context-free assumptions. Inference in this grammar is performed by collapsed variational inference, in which an amortized variational posterior is placed on the continuous variable, and the latent trees are marginalized with dynamic programming. Experiments on English and Chinese show the effectiveness of our approach compared to recent state-of-the-art methods for grammar induction.
Scalable Syntax-Aware Language Models Using Knowledge Distillation
Jun 14, 2019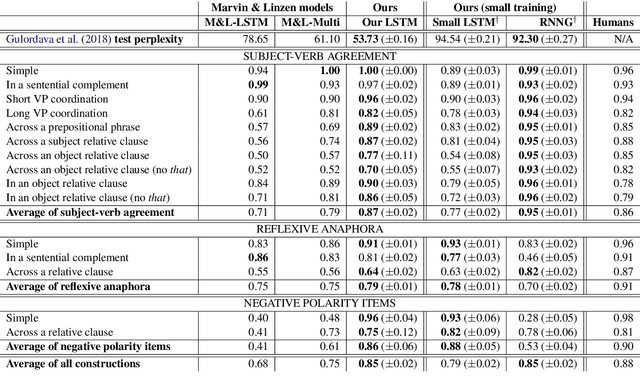
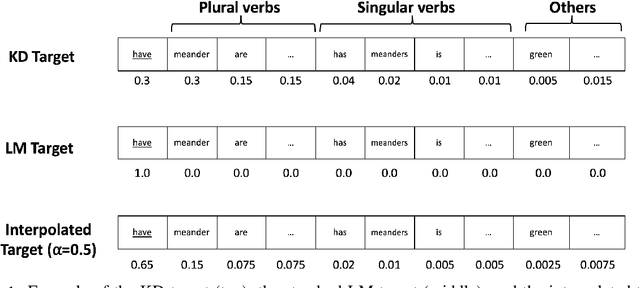
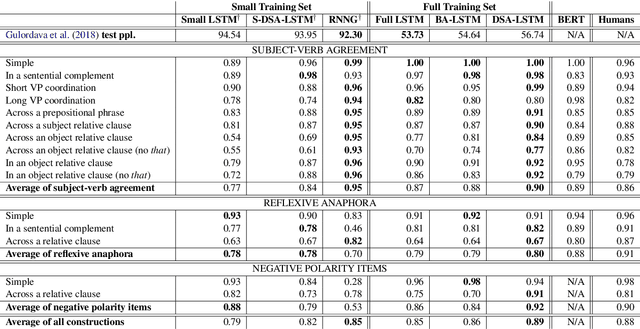
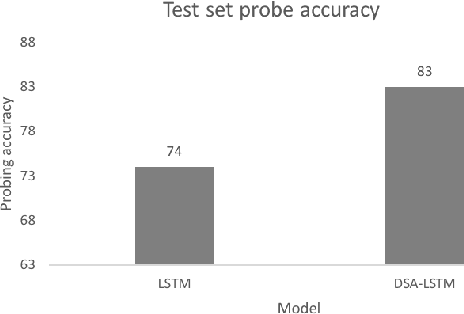
Prior work has shown that, on small amounts of training data, syntactic neural language models learn structurally sensitive generalisations more successfully than sequential language models. However, their computational complexity renders scaling difficult, and it remains an open question whether structural biases are still necessary when sequential models have access to ever larger amounts of training data. To answer this question, we introduce an efficient knowledge distillation (KD) technique that transfers knowledge from a syntactic language model trained on a small corpus to an LSTM language model, hence enabling the LSTM to develop a more structurally sensitive representation of the larger training data it learns from. On targeted syntactic evaluations, we find that, while sequential LSTMs perform much better than previously reported, our proposed technique substantially improves on this baseline, yielding a new state of the art. Our findings and analysis affirm the importance of structural biases, even in models that learn from large amounts of data.