 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUSE: Machine Unlearning Six-Way Evaluation for Language Models
Jul 08, 2024Language models (LMs) are trained on vast amounts of text data, which may include private and copyrighted content. Data owners may request the removal of their data from a trained model due to privacy or copyright concerns. However, exactly unlearning only these datapoints (i.e., retraining with the data removed) is intractable in modern-day models. This has led to the development of many approximate unlearning algorithms. The evaluation of the efficacy of these algorithms has traditionally been narrow in scope, failing to precisely quantify the success and practicality of the algorithm from the perspectives of both the model deployers and the data owners. We address this issue by proposing MUSE, a comprehensive machine unlearning evaluation benchmark that enumerates six diverse desirable properties for unlearned models: (1) no verbatim memorization, (2) no knowledge memorization, (3) no privacy leakage, (4) utility preservation on data not intended for removal, (5) scalability with respect to the size of removal requests, and (6) sustainability over sequential unlearning requests. Using these criteria, we benchmark how effectively eight popular unlearning algorithms on 7B-parameter LMs can unlearn Harry Potter books and news articles. Our results demonstrate that most algorithms can prevent verbatim memorization and knowledge memorization to varying degrees, but only one algorithm does not lead to severe privacy leakage. Furthermore, existing algorithms fail to meet deployer's expectations because they often degrade general model utility and also cannot sustainably accommodate successive unlearning requests or large-scale content removal. Our findings identify key issues with the practicality of existing unlearning algorithms on language models, and we release our benchmark to facilitate further evaluations: muse-bench.github.io
On Convex Optimization with Semi-Sensitive Features
Jun 27, 2024We study the differentially private (DP) empirical risk minimization (ERM) problem under the semi-sensitive DP setting where only some features are sensitive. This generalizes the Label DP setting where only the label is sensitive. We give improved upper and lower bounds on the excess risk for DP-ERM. In particular, we show that the error only scales polylogarithmically in terms of the sensitive domain size, improving upon previous results that scale polynomially in the sensitive domain size (Ghazi et al., 2021).
Evaluating Copyright Takedown Methods for Language Models
Jun 26, 2024



Language models (LMs) derive their capabilities from extensive training on diverse data, including potentially copyrighted material. These models can memorize and generate content similar to their training data, posing potential concerns. Therefore, model creators are motivated to develop mitigation methods that prevent generating protected content. We term this procedure as copyright takedowns for LMs, noting the conceptual similarity to (but legal distinction from) the DMCA takedown This paper introduces the first evaluation of the feasibility and side effects of copyright takedowns for LMs. We propose CoTaEval, an evaluation framework to assess the effectiveness of copyright takedown methods, the impact on the model's ability to retain uncopyrightable factual knowledge from the training data whose recitation is embargoed, and how well the model maintains its general utility and efficiency. We examine several strategies, including adding system prompts, decoding-time filtering interventions, and unlearning approaches. Our findings indicate that no tested method excels across all metrics, showing significant room for research in this unique problem setting and indicating potential unresolved challenges for live policy proposals.
Crosslingual Capabilities and Knowledge Barriers in Multilingual Large Language Models
Jun 23, 2024



Large language models (LLMs) are typically multilingual due to pretraining on diverse multilingual corpora. But can these models relate corresponding concepts across languages, effectively being crosslingual? This study evaluates six state-of-the-art LLMs on inherently crosslingual tasks. We observe that while these models show promising surface-level crosslingual abilities on machine translation and embedding space analyses, they struggle with deeper crosslingual knowledge transfer, revealing a crosslingual knowledge barrier in both general (MMLU benchmark) and domain-specific (Harry Potter quiz) contexts. We observe that simple inference-time mitigation methods offer only limited improvement. On the other hand, we propose fine-tuning of LLMs on mixed-language data, which effectively reduces these gaps, even when using out-of-domain datasets like WikiText. Our findings suggest the need for explicit optimization to unlock the full crosslingual potential of LLMs. Our code is publicly available at https://github.com/google-research/crosslingual-knowledge-barriers.
Mind the Privacy Unit! User-Level Differential Privacy for Language Model Fine-Tuning
Jun 20, 2024



Large language models (LLMs) have emerged as powerful tools for tackling complex tasks across diverse domains, but they also raise privacy concerns when fine-tuned on sensitive data due to potential memorization. While differential privacy (DP) offers a promising solution by ensuring models are `almost indistinguishable' with or without any particular privacy unit, current evaluations on LLMs mostly treat each example (text record) as the privacy unit. This leads to uneven user privacy guarantees when contributions per user vary. We therefore study user-level DP motivated by applications where it necessary to ensure uniform privacy protection across users. We present a systematic evaluation of user-level DP for LLM fine-tuning on natural language generation tasks. Focusing on two mechanisms for achieving user-level DP guarantees, Group Privacy and User-wise DP-SGD, we investigate design choices like data selection strategies and parameter tuning for the best privacy-utility tradeoff.
Fantastic Copyrighted Beasts and How (Not) to Generate Them
Jun 20, 2024Recent studies show that image and video generation models can be prompted to reproduce copyrighted content from their training data, raising serious legal concerns around copyright infringement. Copyrighted characters, in particular, pose a difficult challenge for image generation services, with at least one lawsuit already awarding damages based on the generation of these characters. Yet, little research has empirically examined this issue. We conduct a systematic evaluation to fill this gap. First, we build CopyCat, an evaluation suite consisting of diverse copyrighted characters and a novel evaluation pipeline. Our evaluation considers both the detection of similarity to copyrighted characters and generated image's consistency with user input. Our evaluation systematically shows that both image and video generation models can still generate characters even if characters' names are not explicitly mentioned in the prompt, sometimes with only two generic keywords (e.g., prompting with "videogame, plumber" consistently generates Nintendo's Mario character). We then introduce techniques to semi-automatically identify such keywords or descriptions that trigger character generation. Using our evaluation suite, we study runtime mitigation strategies, including both existing methods and new strategies we propose. Our findings reveal that commonly employed strategies, such as prompt rewriting in the DALL-E system, are not sufficient as standalone guardrails. These strategies must be coupled with other approaches, like negative prompting, to effectively reduce the unintended generation of copyrighted characters. Our work provides empirical grounding to the discussion of copyright mitigation strategies and offers actionable insights for model deployers actively implementing them.
Localizing Paragraph Memorization in Language Models
Mar 28, 2024Can we localize the weights and mechanisms used by a language model to memorize and recite entire paragraphs of its training data? In this paper, we show that while memorization is spread across multiple layers and model components, gradients of memorized paragraphs have a distinguishable spatial pattern, being larger in lower model layers than gradients of non-memorized examples. Moreover, the memorized examples can be unlearned by fine-tuning only the high-gradient weights. We localize a low-layer attention head that appears to be especially involved in paragraph memorization. This head is predominantly focusing its attention on distinctive, rare tokens that are least frequent in a corpus-level unigram distribution. Next, we study how localized memorization is across the tokens in the prefix by perturbing tokens and measuring the caused change in the decoding. A few distinctive tokens early in a prefix can often corrupt the entire continuation. Overall, memorized continuations are not only harder to unlearn, but also to corrupt than non-memorized ones.
How Private is DP-SGD?
Mar 26, 2024



We demonstrate a substantial gap between the privacy guarantees of the Adaptive Batch Linear Queries (ABLQ) mechanism under different types of batch sampling: (i) Shuffling, and (ii) Poisson subsampling; the typical analysis of Differentially Private Stochastic Gradient Descent (DP-SGD) follows by interpreting it as a post-processing of ABLQ. While shuffling based DP-SGD is more commonly used in practical implementations, it is neither analytically nor numerically amenable to easy privacy analysis. On the other hand, Poisson subsampling based DP-SGD is challenging to scalably implement, but has a well-understood privacy analysis, with multiple open-source numerically tight privacy accountants available. This has led to a common practice of using shuffling based DP-SGD in practice, but using the privacy analysis for the corresponding Poisson subsampling version. Our result shows that there can be a substantial gap between the privacy analysis when using the two types of batch sampling, and thus advises caution in reporting privacy parameters for DP-SGD.
Training Differentially Private Ad Prediction Models with Semi-Sensitive Features
Jan 26, 2024
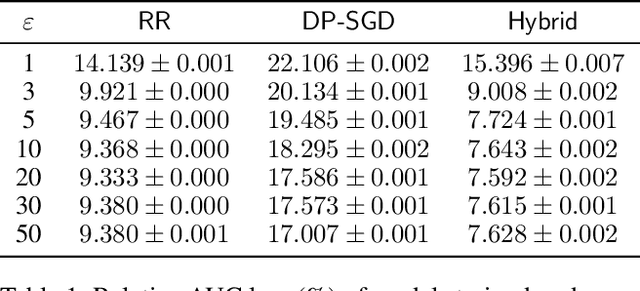
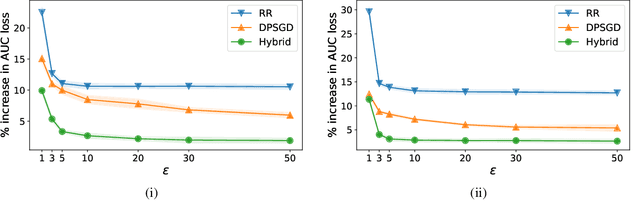
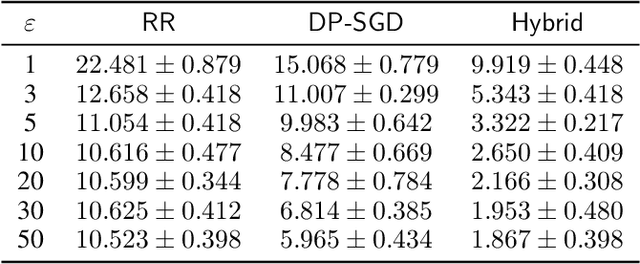
Motivated by problems arising in digital advertising, we introduce the task of training differentially private (DP) machine learning models with semi-sensitive features. In this setting, a subset of the features is known to the attacker (and thus need not be protected) while the remaining features as well as the label are unknown to the attacker and should be protected by the DP guarantee. This task interpolates between training the model with full DP (where the label and all features should be protected) or with label DP (where all the features are considered known, and only the label should be protected). We present a new algorithm for training DP models with semi-sensitive features. Through an empirical evaluation on real ads datasets, we demonstrate that our algorithm surpasses in utility the baselines of (i) DP stochastic gradient descent (DP-SGD) run on all features (known and unknown), and (ii) a label DP algorithm run only on the known features (while discarding the unknown ones).
Optimal Unbiased Randomizers for Regression with Label Differential Privacy
Dec 09, 2023



We propose a new family of label randomizers for training regression models under the constraint of label differential privacy (DP). In particular, we leverage the trade-offs between bias and variance to construct better label randomizers depending on a privately estimated prior distribution over the labels. We demonstrate that these randomizers achieve state-of-the-art privacy-utility trade-offs on several datasets, highlighting the importance of reducing bias when training neural networks with label DP. We also provide theoretical results shedding light on the structural properties of the optimal unbiased randomizers.