 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGETReason: Enhancing Image Context Extraction through Hierarchical Multi-Agent Reasoning
May 29, 2025
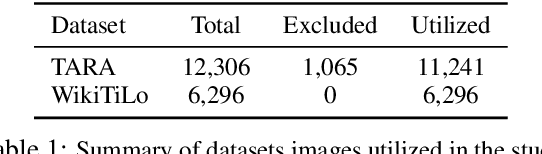
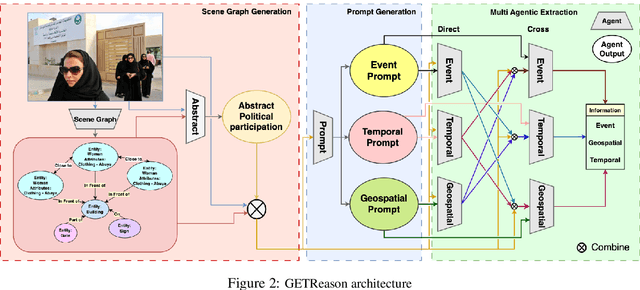
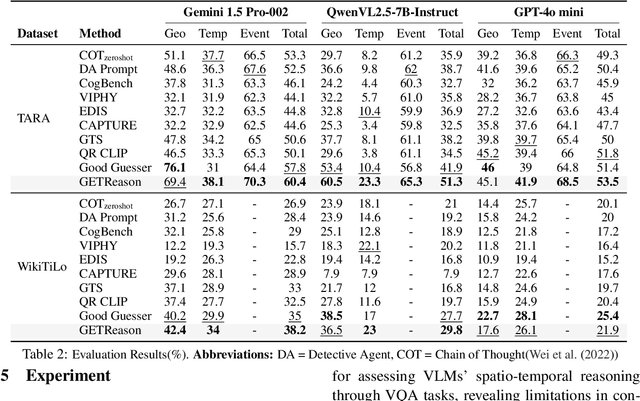
Publicly significant images from events hold valuable contextual information, crucial for journalism and education. However, existing methods often struggle to extract this relevance accurately. To address this, we introduce GETReason (Geospatial Event Temporal Reasoning), a framework that moves beyond surface-level image descriptions to infer deeper contextual meaning. We propose that extracting global event, temporal, and geospatial information enhances understanding of an image's significance. Additionally, we introduce GREAT (Geospatial Reasoning and Event Accuracy with Temporal Alignment), a new metric for evaluating reasoning-based image understanding. Our layered multi-agent approach, assessed using a reasoning-weighted metric, demonstrates that meaningful insights can be inferred, effectively linking images to their broader event context.
Rethinking Information Synthesis in Multimodal Question Answering A Multi-Agent Perspective
May 27, 2025Recent advances in multimodal question answering have primarily focused on combining heterogeneous modalities or fine-tuning multimodal large language models. While these approaches have shown strong performance, they often rely on a single, generalized reasoning strategy, overlooking the unique characteristics of each modality ultimately limiting both accuracy and interpretability. To address these limitations, we propose MAMMQA, a multi-agent QA framework for multimodal inputs spanning text, tables, and images. Our system includes two Visual Language Model (VLM) agents and one text-based Large Language Model (LLM) agent. The first VLM decomposes the user query into sub-questions and sequentially retrieves partial answers from each modality. The second VLM synthesizes and refines these results through cross-modal reasoning. Finally, the LLM integrates the insights into a cohesive answer. This modular design enhances interpretability by making the reasoning process transparent and allows each agent to operate within its domain of expertise. Experiments on diverse multimodal QA benchmarks demonstrate that our cooperative, multi-agent framework consistently outperforms existing baselines in both accuracy and robustness.
MMTBENCH: A Unified Benchmark for Complex Multimodal Table Reasoning
May 27, 2025Multimodal tables those that integrate semi structured data with visual elements such as charts and maps are ubiquitous across real world domains, yet they pose a formidable challenge to current vision language models (VLMs). While Large Language models (LLMs) and VLMs have demonstrated strong capabilities in text and image understanding, their performance on complex, real world multimodal table reasoning remains unexplored. To bridge this gap, we introduce MMTBENCH (Multimodal Table Benchmark), a benchmark consisting of 500 real world multimodal tables drawn from diverse real world sources, with a total of 4021 question answer pairs. MMTBENCH questions cover four question types (Explicit, Implicit, Answer Mention, and Visual Based), five reasoning types (Mathematical, Extrema Identification, Fact Verification, Vision Based, and Others), and eight table types (Single/Multiple Entity, Maps and Charts with Entities, Single/Multiple Charts, Maps, and Visualizations). Extensive evaluation of state of the art models on all types reveals substantial performance gaps, particularly on questions requiring visual-based reasoning and multi-step inference. These findings show the urgent need for improved architectures that more tightly integrate vision and language processing. By providing a challenging, high-quality resource that mirrors the complexity of real-world tasks, MMTBENCH underscores its value as a resource for future research on multimodal tables.
TextInVision: Text and Prompt Complexity Driven Visual Text Generation Benchmark
Mar 17, 2025Generating images with embedded text is crucial for the automatic production of visual and multimodal documents, such as educational materials and advertisements. However, existing diffusion-based text-to-image models often struggle to accurately embed text within images, facing challenges in spelling accuracy, contextual relevance, and visual coherence. Evaluating the ability of such models to embed text within a generated image is complicated due to the lack of comprehensive benchmarks. In this work, we introduce TextInVision, a large-scale, text and prompt complexity driven benchmark designed to evaluate the ability of diffusion models to effectively integrate visual text into images. We crafted a diverse set of prompts and texts that consider various attributes and text characteristics. Additionally, we prepared an image dataset to test Variational Autoencoder (VAE) models across different character representations, highlighting that VAE architectures can also pose challenges in text generation within diffusion frameworks. Through extensive analysis of multiple models, we identify common errors and highlight issues such as spelling inaccuracies and contextual mismatches. By pinpointing the failure points across different prompts and texts, our research lays the foundation for future advancements in AI-generated multimodal content.
PlanGEN: A Multi-Agent Framework for Generating Planning and Reasoning Trajectories for Complex Problem Solving
Feb 22, 2025Recent agent frameworks and inference-time algorithms often struggle with complex planning problems due to limitations in verifying generated plans or reasoning and varying complexity of instances within a single task. Many existing methods for these tasks either perform task-level verification without considering constraints or apply inference-time algorithms without adapting to instance-level complexity. To address these limitations, we propose PlanGEN, a model-agnostic and easily scalable agent framework with three key components: constraint, verification, and selection agents. Specifically, our approach proposes constraint-guided iterative verification to enhance performance of inference-time algorithms--Best of N, Tree-of-Thought, and REBASE. In PlanGEN framework, the selection agent optimizes algorithm choice based on instance complexity, ensuring better adaptability to complex planning problems. Experimental results demonstrate significant improvements over the strongest baseline across multiple benchmarks, achieving state-of-the-art results on NATURAL PLAN ($\sim$8%$\uparrow$), OlympiadBench ($\sim$4%$\uparrow$), DocFinQA ($\sim$7%$\uparrow$), and GPQA ($\sim$1%$\uparrow$). Our key finding highlights that constraint-guided iterative verification improves inference-time algorithms, and adaptive selection further boosts performance on complex planning and reasoning problems.
Dual Caption Preference Optimization for Diffusion Models
Feb 09, 2025Recent advancements in human preference optimization, originally developed for Large Language Models (LLMs), have shown significant potential in improving text-to-image diffusion models. These methods aim to learn the distribution of preferred samples while distinguishing them from less preferred ones. However, existing preference datasets often exhibit overlap between these distributions, leading to a conflict distribution. Additionally, we identified that input prompts contain irrelevant information for less preferred images, limiting the denoising network's ability to accurately predict noise in preference optimization methods, known as the irrelevant prompt issue. To address these challenges, we propose Dual Caption Preference Optimization (DCPO), a novel approach that utilizes two distinct captions to mitigate irrelevant prompts. To tackle conflict distribution, we introduce the Pick-Double Caption dataset, a modified version of Pick-a-Pic v2 with separate captions for preferred and less preferred images. We further propose three different strategies for generating distinct captions: captioning, perturbation, and hybrid methods. Our experiments show that DCPO significantly improves image quality and relevance to prompts, outperforming Stable Diffusion (SD) 2.1, SFT_Chosen, Diffusion-DPO, and MaPO across multiple metrics, including Pickscore, HPSv2.1, GenEval, CLIPscore, and ImageReward, fine-tuned on SD 2.1 as the backbone.
Investigating the Shortcomings of LLMs in Step-by-Step Legal Reasoning
Feb 08, 2025



Reasoning abilities of LLMs have been a key focus in recent years. One challenging reasoning domain with interesting nuances is legal reasoning, which requires careful application of rules, and precedents while balancing deductive and analogical reasoning, and conflicts between rules. Although there have been a few works on using LLMs for legal reasoning, their focus has been on overall accuracy. In this paper, we dig deeper to do a step-by-step analysis and figure out where they commit errors. We use the college-level Multiple Choice Question-Answering (MCQA) task from the \textit{Civil Procedure} dataset and propose a new error taxonomy derived from initial manual analysis of reasoning chains with respect to several LLMs, including two objective measures: soundness and correctness scores. We then develop an LLM-based automated evaluation framework to identify reasoning errors and evaluate the performance of LLMs. The computation of soundness and correctness on the dataset using the auto-evaluator framework reveals several interesting insights. Furthermore, we show that incorporating the error taxonomy as feedback in popular prompting techniques marginally increases LLM performance. Our work will also serve as an evaluation framework that can be used in detailed error analysis of reasoning chains for logic-intensive complex tasks.
TripletCLIP: Improving Compositional Reasoning of CLIP via Synthetic Vision-Language Negatives
Nov 04, 2024



Contrastive Language-Image Pretraining (CLIP) models maximize the mutual information between text and visual modalities to learn representations. This makes the nature of the training data a significant factor in the efficacy of CLIP for downstream tasks. However, the lack of compositional diversity in contemporary image-text datasets limits the compositional reasoning ability of CLIP. We show that generating ``hard'' negative captions via in-context learning and synthesizing corresponding negative images with text-to-image generators offers a solution. We introduce a novel contrastive pre-training strategy that leverages these hard negative captions and images in an alternating fashion to train CLIP. We demonstrate that our method, named TripletCLIP, when applied to existing datasets such as CC3M and CC12M, enhances the compositional capabilities of CLIP, resulting in an absolute improvement of over 9% on the SugarCrepe benchmark on an equal computational budget, as well as improvements in zero-shot image classification and image retrieval. Our code, models, and data are available at: https://tripletclip.github.io
ToW: Thoughts of Words Improve Reasoning in Large Language Models
Oct 21, 2024



We introduce thoughts of words (ToW), a novel training-time data-augmentation method for next-word prediction. ToW views next-word prediction as a core reasoning task and injects fine-grained thoughts explaining what the next word should be and how it is related to the previous contexts in pre-training texts. Our formulation addresses two fundamental drawbacks of existing next-word prediction learning schemes: they induce factual hallucination and are inefficient for models to learn the implicit reasoning processes in raw texts. While there are many ways to acquire such thoughts of words, we explore the first step of acquiring ToW annotations through distilling from larger models. After continual pre-training with only 70K ToW annotations, we effectively improve models' reasoning performances by 7% to 9% on average and reduce model hallucination by up to 10%. At the same time, ToW is entirely agnostic to tasks and applications, introducing no additional biases on labels or semantics.
ActionCOMET: A Zero-shot Approach to Learn Image-specific Commonsense Concepts about Actions
Oct 17, 2024



Humans observe various actions being performed by other humans (physically or in videos/images) and can draw a wide range of inferences about it beyond what they can visually perceive. Such inferences include determining the aspects of the world that make action execution possible (e.g. liquid objects can undergo pouring), predicting how the world will change as a result of the action (e.g. potatoes being golden and crispy after frying), high-level goals associated with the action (e.g. beat the eggs to make an omelet) and reasoning about actions that possibly precede or follow the current action (e.g. crack eggs before whisking or draining pasta after boiling). Similar reasoning ability is highly desirable in autonomous systems that would assist us in performing everyday tasks. To that end, we propose a multi-modal task to learn aforementioned concepts about actions being performed in images. We develop a dataset consisting of 8.5k images and 59.3k inferences about actions grounded in those images, collected from an annotated cooking-video dataset. We propose ActionCOMET, a zero-shot framework to discern knowledge present in language models specific to the provided visual input. We present baseline results of ActionCOMET over the collected dataset and compare them with the performance of the best existing VQA approaches.