 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillHarm: Lifecycle-Aware Skill-Based Attacks via Automated Construction
Jun 01, 2026Agent skills occupy a privileged position in the agent workflow, as agents are expected to implicitly follow and execute them, rendering third-party skills a vulnerable attack surface. Existing studies have revealed unsafe agent behaviors induced by skill-based attacks, but they primarily evaluate poisoned skills within a single task execution and enumerate harms through ad-hoc risk lists. To bridge these gaps, we introduce SkillHarm, a benchmark of skill-based attacks across the skill-use lifecycle, paired with a systematic taxonomy of skill-relevant risks. SkillHarm evaluates two attack scenarios: Fixed-Payload Poisoning (FPP), where a fixed poisoned skill package directly compromises any task session that invokes it, and Self-Mutating Poisoning (SMP), where an initially benign execution silently mutates persistent skill content, deferring harm until a subsequent reuse. It further defines 12 risk types based on the agent workflow component targeted by the harm: data pipelines, system environments, and agent autonomy. To instantiate these attacks at scale, we build AutoSkillHarm, an automated construction pipeline with coding agents driven by natural-language harnesses. The resulting benchmark contains 879 attack samples across 71 skills. Experiments show that current agents remain vulnerable with attack success rates up to 86.3% in FPP and 69.3% in SMP. Our analysis further reveals a latent risk: many apparent attack failures stem from the agent failing to engage with the poisoned file rather than genuine resistance, and current defenses still fail to reliably mitigate the threat.
When Actions Go Off-Task: Detecting and Correcting Misaligned Actions in Computer-Use Agents
Feb 09, 2026Computer-use agents (CUAs) have made tremendous progress in the past year, yet they still frequently produce misaligned actions that deviate from the user's original intent. Such misaligned actions may arise from external attacks (e.g., indirect prompt injection) or from internal limitations (e.g., erroneous reasoning). They not only expose CUAs to safety risks, but also degrade task efficiency and reliability. This work makes the first effort to define and study misaligned action detection in CUAs, with comprehensive coverage of both externally induced and internally arising misaligned actions. We further identify three common categories in real-world CUA deployment and construct MisActBench, a benchmark of realistic trajectories with human-annotated, action-level alignment labels. Moreover, we propose DeAction, a practical and universal guardrail that detects misaligned actions before execution and iteratively corrects them through structured feedback. DeAction outperforms all existing baselines across offline and online evaluations with moderate latency overhead: (1) On MisActBench, it outperforms baselines by over 15% absolute in F1 score; (2) In online evaluation, it reduces attack success rate by over 90% under adversarial settings while preserving or even improving task success rate in benign environments.
A Dataset and Baselines for Visual Question Answering on Art
Aug 28, 2020
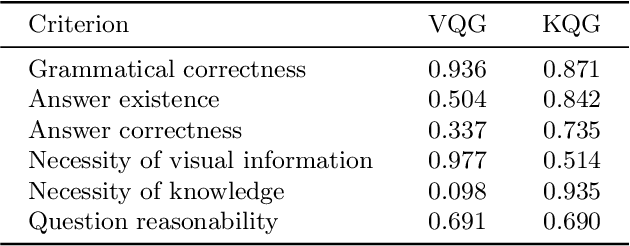
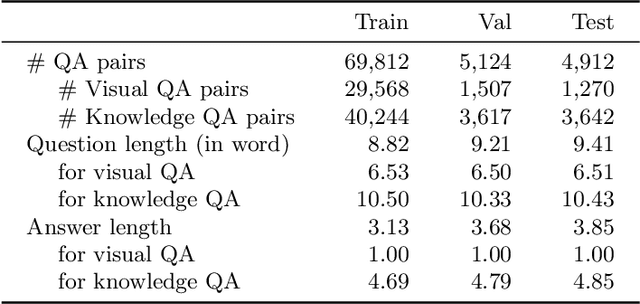
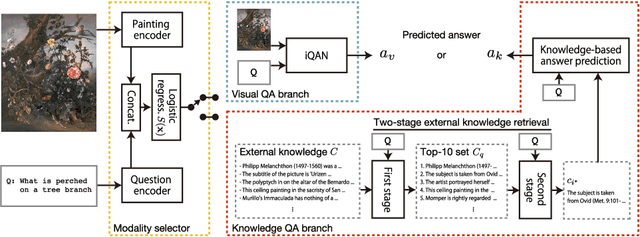
Answering questions related to art pieces (paintings) is a difficult task, as it implies the understanding of not only the visual information that is shown in the picture, but also the contextual knowledge that is acquired through the study of the history of art. In this work, we introduce our first attempt towards building a new dataset, coined AQUA (Art QUestion Answering). The question-answer (QA) pairs are automatically generated using state-of-the-art question generation methods based on paintings and comments provided in an existing art understanding dataset. The QA pairs are cleansed by crowdsourcing workers with respect to their grammatical correctness, answerability, and answers' correctness. Our dataset inherently consists of visual (painting-based) and knowledge (comment-based) questions. We also present a two-branch model as baseline, where the visual and knowledge questions are handled independently. We extensively compare our baseline model against the state-of-the-art models for question answering, and we provide a comprehensive study about the challenges and potential future directions for visual question answering on art.