 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoMark: Perceptual Acoustic Environment Transfer with Watermark-Embedded Room Impulse Response
Nov 09, 2025Acoustic Environment Matching (AEM) is the task of transferring clean audio into a target acoustic environment, enabling engaging applications such as audio dubbing and auditory immersive virtual reality (VR). Recovering similar room impulse response (RIR) directly from reverberant speech offers more accessible and flexible AEM solution. However, this capability also introduces vulnerabilities of arbitrary ``relocation" if misused by malicious user, such as facilitating advanced voice spoofing attacks or undermining the authenticity of recorded evidence. To address this issue, we propose EchoMark, the first deep learning-based AEM framework that generates perceptually similar RIRs with embedded watermark. Our design tackle the challenges posed by variable RIR characteristics, such as different durations and energy decays, by operating in the latent domain. By jointly optimizing the model with a perceptual loss for RIR reconstruction and a loss for watermark detection, EchoMark achieves both high-quality environment transfer and reliable watermark recovery. Experiments on diverse datasets validate that EchoMark achieves room acoustic parameter matching performance comparable to FiNS, the state-of-the-art RIR estimator. Furthermore, a high Mean Opinion Score (MOS) of 4.22 out of 5, watermark detection accuracy exceeding 99\%, and bit error rates (BER) below 0.3\% collectively demonstrate the effectiveness of EchoMark in preserving perceptual quality while ensuring reliable watermark embedding.
SpeechVerifier: Robust Acoustic Fingerprint against Tampering Attacks via Watermarking
May 28, 2025With the surge of social media, maliciously tampered public speeches, especially those from influential figures, have seriously affected social stability and public trust. Existing speech tampering detection methods remain insufficient: they either rely on external reference data or fail to be both sensitive to attacks and robust to benign operations, such as compression and resampling. To tackle these challenges, we introduce SpeechVerifer to proactively verify speech integrity using only the published speech itself, i.e., without requiring any external references. Inspired by audio fingerprinting and watermarking, SpeechVerifier can (i) effectively detect tampering attacks, (ii) be robust to benign operations and (iii) verify the integrity only based on published speeches. Briefly, SpeechVerifier utilizes multiscale feature extraction to capture speech features across different temporal resolutions. Then, it employs contrastive learning to generate fingerprints that can detect modifications at varying granularities. These fingerprints are designed to be robust to benign operations, but exhibit significant changes when malicious tampering occurs. To enable speech verification in a self-contained manner, the generated fingerprints are then embedded into the speech signal by segment-wise watermarking. Without external references, SpeechVerifier can retrieve the fingerprint from the published audio and check it with the embedded watermark to verify the integrity of the speech. Extensive experimental results demonstrate that the proposed SpeechVerifier is effective in detecting tampering attacks and robust to benign operations.
Eve Said Yes: AirBone Authentication for Head-Wearable Smart Voice Assistant
Sep 26, 2023



Recent advances in machine learning and natural language processing have fostered the enormous prosperity of smart voice assistants and their services, e.g., Alexa, Google Home, Siri, etc. However, voice spoofing attacks are deemed to be one of the major challenges of voice control security, and never stop evolving such as deep-learning-based voice conversion and speech synthesis techniques. To solve this problem outside the acoustic domain, we focus on head-wearable devices, such as earbuds and virtual reality (VR) headsets, which are feasible to continuously monitor the bone-conducted voice in the vibration domain. Specifically, we identify that air and bone conduction (AC/BC) from the same vocalization are coupled (or concurrent) and user-level unique, which makes them suitable behavior and biometric factors for multi-factor authentication (MFA). The legitimate user can defeat acoustic domain and even cross-domain spoofing samples with the proposed two-stage AirBone authentication. The first stage answers \textit{whether air and bone conduction utterances are time domain consistent (TC)} and the second stage runs \textit{bone conduction speaker recognition (BC-SR)}. The security level is hence increased for two reasons: (1) current acoustic attacks on smart voice assistants cannot affect bone conduction, which is in the vibration domain; (2) even for advanced cross-domain attacks, the unique bone conduction features can detect adversary's impersonation and machine-induced vibration. Finally, AirBone authentication has good usability (the same level as voice authentication) compared with traditional MFA and those specially designed to enhance smart voice security. Our experimental results show that the proposed AirBone authentication is usable and secure, and can be easily equipped by commercial off-the-shelf head wearables with good user experience.
Energy and Spectrum Efficient Federated Learning via High-Precision Over-the-Air Computation
Aug 15, 2022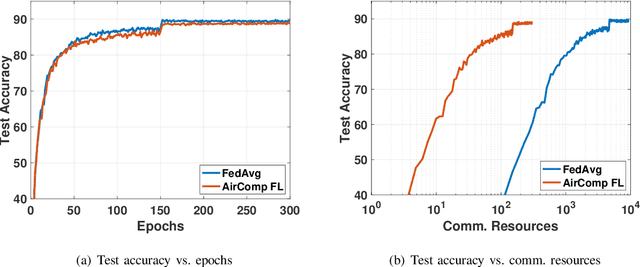
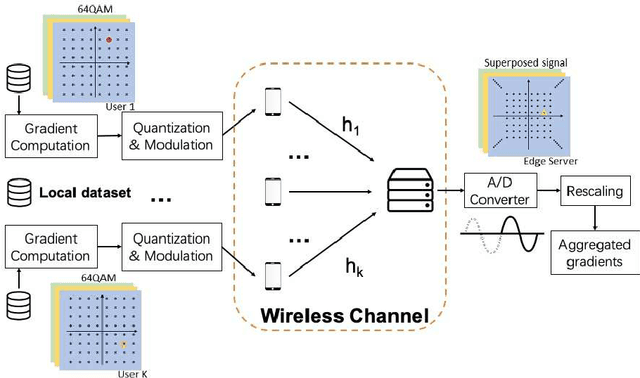
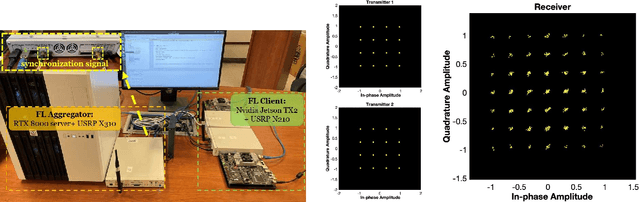
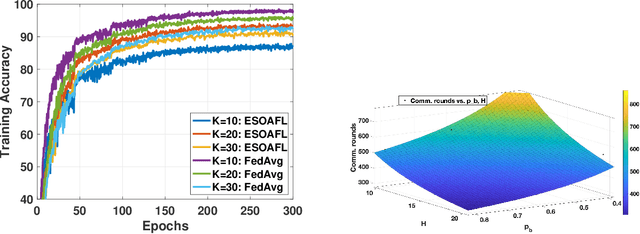
Federated learning (FL) enables mobile devices to collaboratively learn a shared prediction model while keeping data locally. However, there are two major research challenges to practically deploy FL over mobile devices: (i) frequent wireless updates of huge size gradients v.s. limited spectrum resources, and (ii) energy-hungry FL communication and local computing during training v.s. battery-constrained mobile devices. To address those challenges, in this paper, we propose a novel multi-bit over-the-air computation (M-AirComp) approach for spectrum-efficient aggregation of local model updates in FL and further present an energy-efficient FL design for mobile devices. Specifically, a high-precision digital modulation scheme is designed and incorporated in the M-AirComp, allowing mobile devices to upload model updates at the selected positions simultaneously in the multi-access channel. Moreover, we theoretically analyze the convergence property of our FL algorithm. Guided by FL convergence analysis, we formulate a joint transmission probability and local computing control optimization, aiming to minimize the overall energy consumption (i.e., iterative local computing + multi-round communications) of mobile devices in FL. Extensive simulation results show that our proposed scheme outperforms existing ones in terms of spectrum utilization, energy efficiency, and learning accuracy.