 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLossless Image Compression through Super-Resolution
Apr 06, 2020

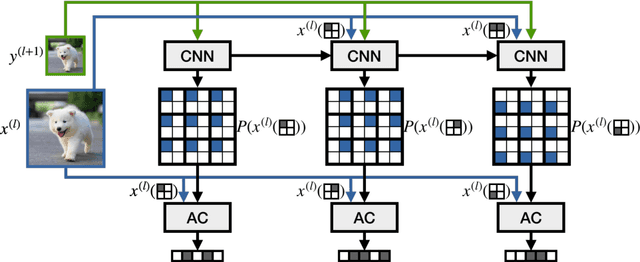
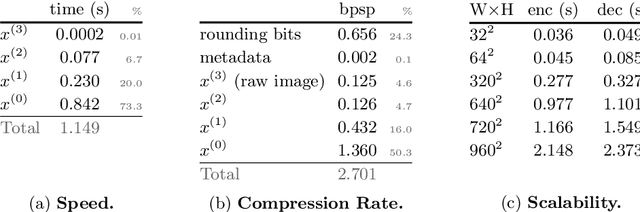
We introduce a simple and efficient lossless image compression algorithm. We store a low resolution version of an image as raw pixels, followed by several iterations of lossless super-resolution. For lossless super-resolution, we predict the probability of a high-resolution image, conditioned on the low-resolution input, and use entropy coding to compress this super-resolution operator. Super-Resolution based Compression (SReC) is able to achieve state-of-the-art compression rates with practical runtimes on large datasets. Code is available online at https://github.com/caoscott/SReC.
A Multigrid Method for Efficiently Training Video Models
Dec 02, 2019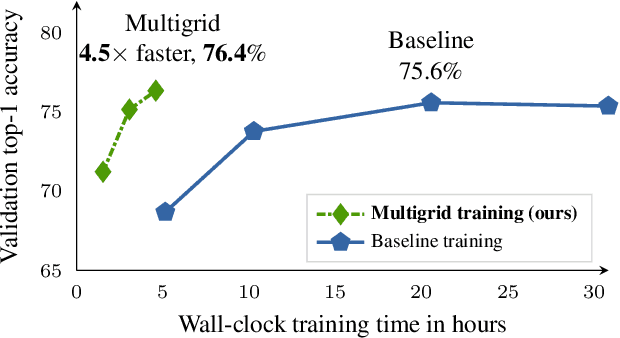

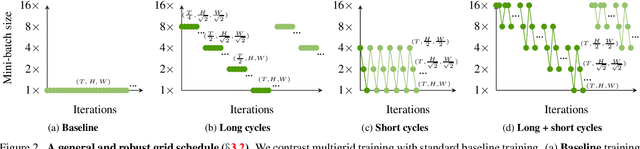

Training competitive deep video models is an order of magnitude slower than training their counterpart image models. Slow training causes long research cycles, which hinders progress in video understanding research. Following standard practice for training image models, video model training assumes a fixed mini-batch shape: a specific number of clips, frames, and spatial size. However, what is the optimal shape? High resolution models perform well, but train slowly. Low resolution models train faster, but they are inaccurate. Inspired by multigrid methods in numerical optimization, we propose to use variable mini-batch shapes with different spatial-temporal resolutions that are varied according to a schedule. The different shapes arise from resampling the training data on multiple sampling grids. Training is accelerated by scaling up the mini-batch size and learning rate when shrinking the other dimensions. We empirically demonstrate a general and robust grid schedule that yields a significant out-of-the-box training speedup without a loss in accuracy for different models (I3D, non-local, SlowFast), datasets (Kinetics, Something-Something, Charades), and training settings (with and without pre-training, 128 GPUs or 1 GPU). As an illustrative example, the proposed multigrid method trains a ResNet-50 SlowFast network 4.5x faster (wall-clock time, same hardware) while also improving accuracy (+0.8% absolute) on Kinetics-400 compared to the baseline training method.
Fashion++: Minimal Edits for Outfit Improvement
Apr 19, 2019

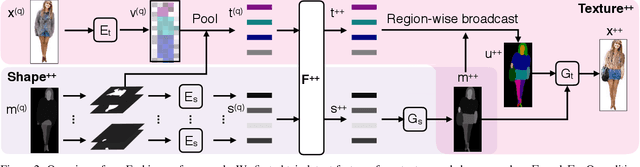
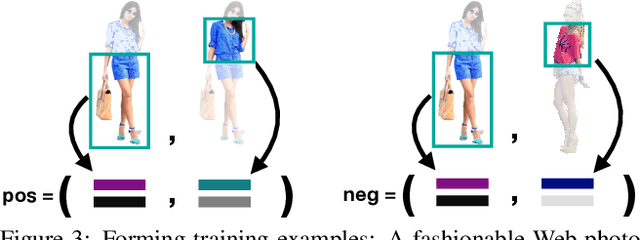
Given an outfit, what small changes would most improve its fashionability? This question presents an intriguing new vision challenge. We introduce Fashion++, an approach that proposes minimal adjustments to a full-body clothing outfit that will have maximal impact on its fashionability. Our model consists of a deep image generation neural network that learns to synthesize clothing conditioned on learned per-garment encodings. The latent encodings are explicitly factorized according to shape and texture, thereby allowing direct edits for both fit/presentation and color/patterns/material, respectively. We show how to bootstrap Web photos to automatically train a fashionability model, and develop an activation maximization-style approach to transform the input image into its more fashionable self. The edits suggested range from swapping in a new garment to tweaking its color, how it is worn (e.g., rolling up sleeves), or its fit (e.g., making pants baggier). Experiments demonstrate that Fashion++ provides successful edits, both according to automated metrics and human opinion. Project page is at http://vision.cs.utexas.edu/projects/FashionPlus.
Long-Term Feature Banks for Detailed Video Understanding
Dec 12, 2018
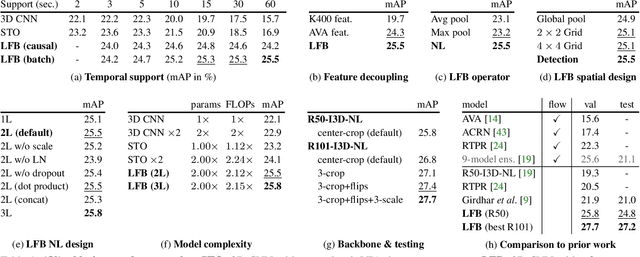

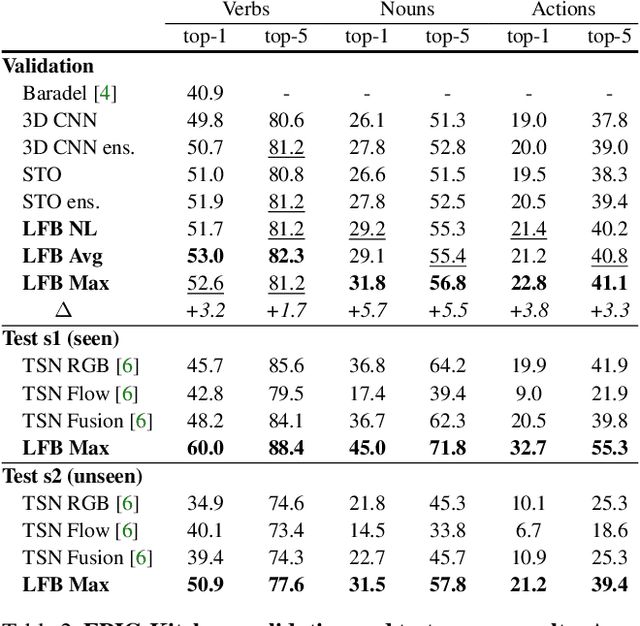
To understand the world, we humans constantly need to relate the present to the past, and put events in context. In this paper, we enable existing video models to do the same. We propose a long-term feature bank---supportive information extracted over the entire span of a video---to augment state-of-the-art video models that otherwise would only view short clips of 2-5 seconds. Our experiments demonstrate that augmenting 3D convolutional networks with a long-term feature bank yields state-of-the-art results on three challenging video datasets: AVA, EPIC-Kitchens, and Charades.
Video Compression through Image Interpolation
Apr 18, 2018
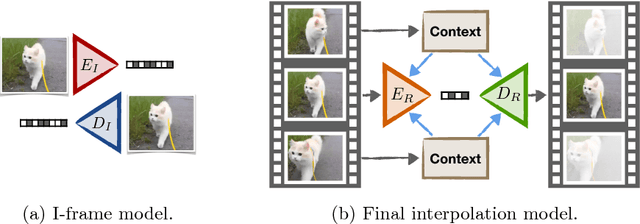
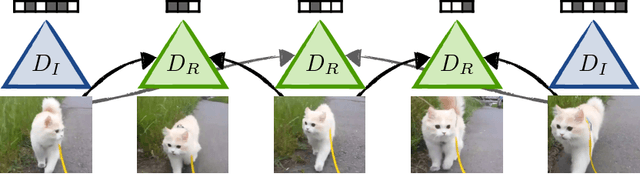
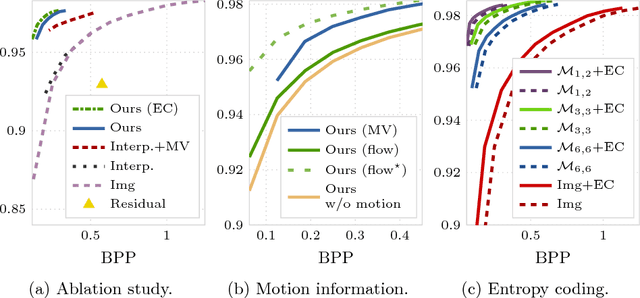
An ever increasing amount of our digital communication, media consumption, and content creation revolves around videos. We share, watch, and archive many aspects of our lives through them, all of which are powered by strong video compression. Traditional video compression is laboriously hand designed and hand optimized. This paper presents an alternative in an end-to-end deep learning codec. Our codec builds on one simple idea: Video compression is repeated image interpolation. It thus benefits from recent advances in deep image interpolation and generation. Our deep video codec outperforms today's prevailing codecs, such as H.261, MPEG-4 Part 2, and performs on par with H.264.
Compressed Video Action Recognition
Mar 29, 2018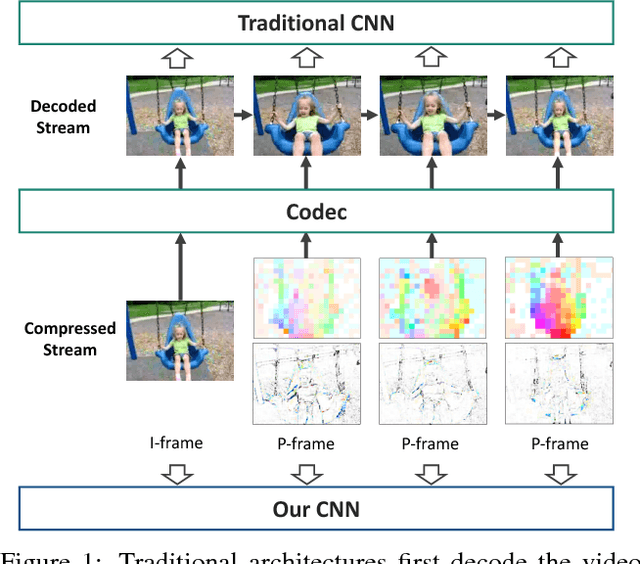
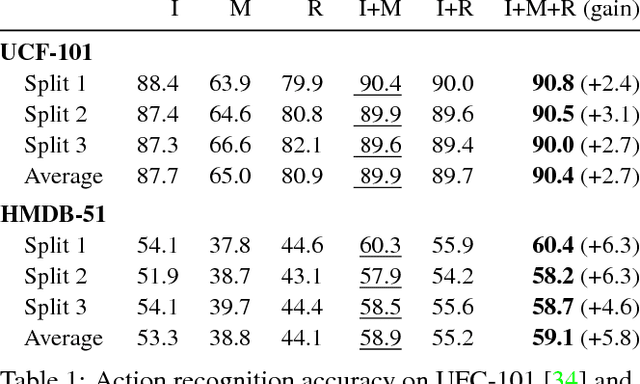
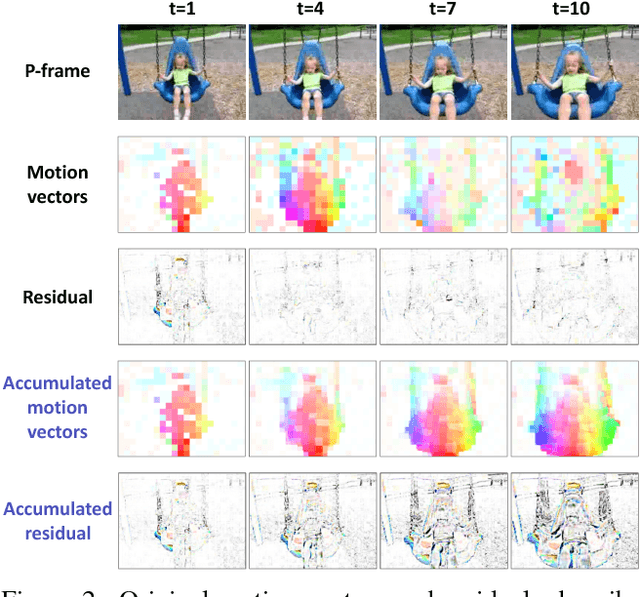

Training robust deep video representations has proven to be much more challenging than learning deep image representations. This is in part due to the enormous size of raw video streams and the high temporal redundancy; the true and interesting signal is often drowned in too much irrelevant data. Motivated by that the superfluous information can be reduced by up to two orders of magnitude by video compression (using H.264, HEVC, etc.), we propose to train a deep network directly on the compressed video. This representation has a higher information density, and we found the training to be easier. In addition, the signals in a compressed video provide free, albeit noisy, motion information. We propose novel techniques to use them effectively. Our approach is about 4.6 times faster than Res3D and 2.7 times faster than ResNet-152. On the task of action recognition, our approach outperforms all the other methods on the UCF-101, HMDB-51, and Charades dataset.
Sampling Matters in Deep Embedding Learning
Jan 16, 2018
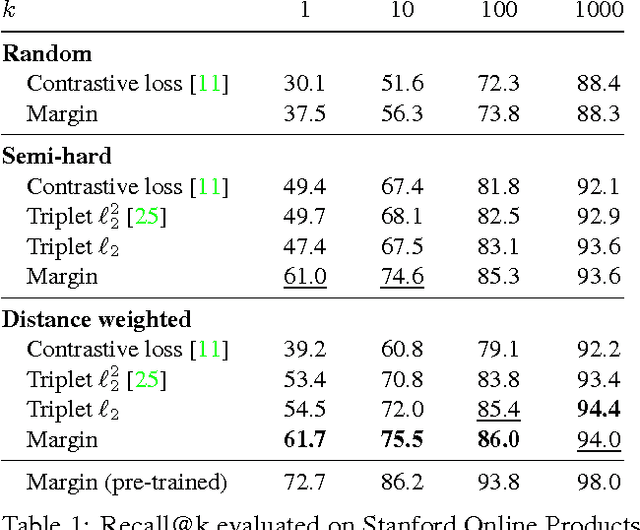
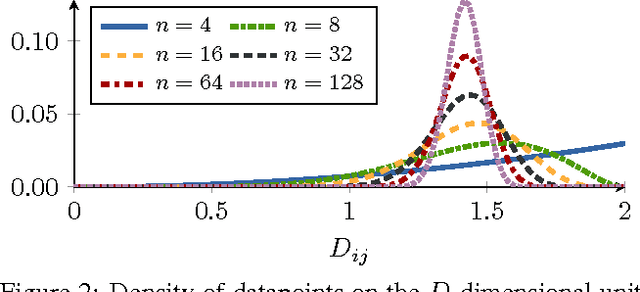
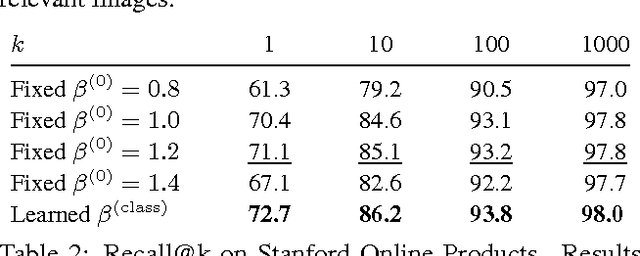
Deep embeddings answer one simple question: How similar are two images? Learning these embeddings is the bedrock of verification, zero-shot learning, and visual search. The most prominent approaches optimize a deep convolutional network with a suitable loss function, such as contrastive loss or triplet loss. While a rich line of work focuses solely on the loss functions, we show in this paper that selecting training examples plays an equally important role. We propose distance weighted sampling, which selects more informative and stable examples than traditional approaches. In addition, we show that a simple margin based loss is sufficient to outperform all other loss functions. We evaluate our approach on the Stanford Online Products, CAR196, and the CUB200-2011 datasets for image retrieval and clustering, and on the LFW dataset for face verification. Our method achieves state-of-the-art performance on all of them.
Spectral Methods for Nonparametric Models
Mar 31, 2017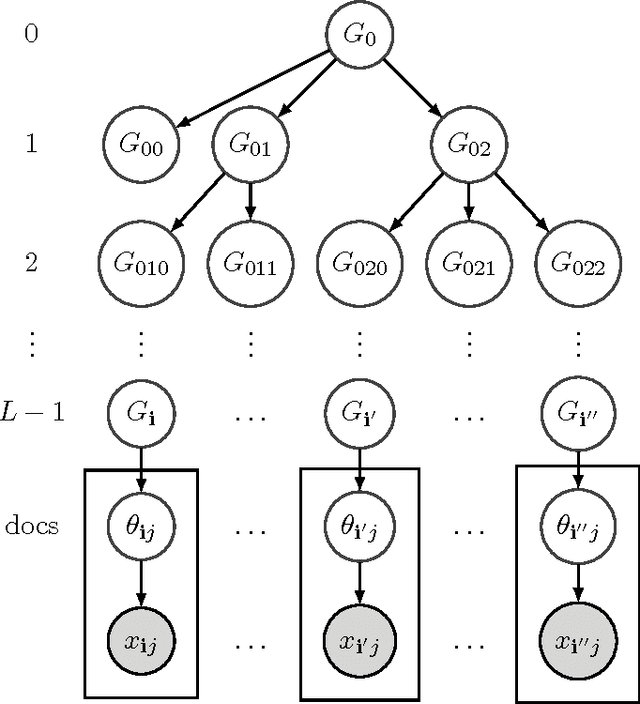

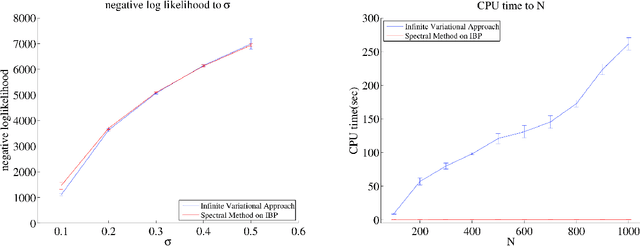

Nonparametric models are versatile, albeit computationally expensive, tool for modeling mixture models. In this paper, we introduce spectral methods for the two most popular nonparametric models: the Indian Buffet Process (IBP) and the Hierarchical Dirichlet Process (HDP). We show that using spectral methods for the inference of nonparametric models are computationally and statistically efficient. In particular, we derive the lower-order moments of the IBP and the HDP, propose spectral algorithms for both models, and provide reconstruction guarantees for the algorithms. For the HDP, we further show that applying hierarchical models on dataset with hierarchical structure, which can be solved with the generalized spectral HDP, produces better solutions to that of flat models regarding likelihood performance.
Explaining reviews and ratings with PACO: Poisson Additive Co-Clustering
Dec 06, 2015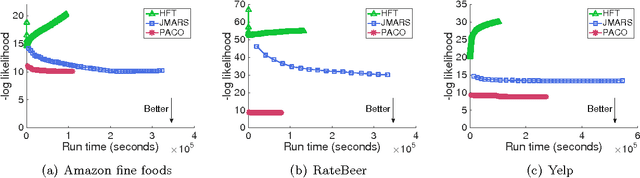
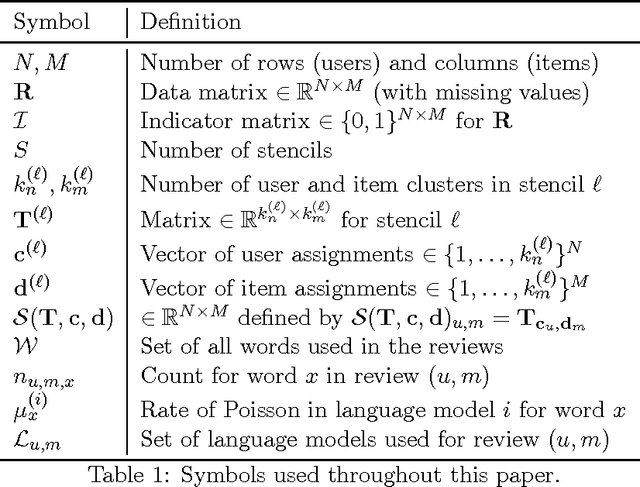
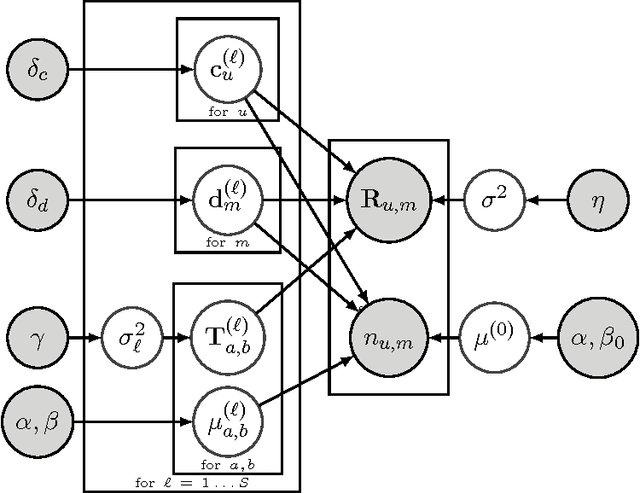
Understanding a user's motivations provides valuable information beyond the ability to recommend items. Quite often this can be accomplished by perusing both ratings and review texts, since it is the latter where the reasoning for specific preferences is explicitly expressed. Unfortunately matrix factorization approaches to recommendation result in large, complex models that are difficult to interpret and give recommendations that are hard to clearly explain to users. In contrast, in this paper, we attack this problem through succinct additive co-clustering. We devise a novel Bayesian technique for summing co-clusterings of Poisson distributions. With this novel technique we propose a new Bayesian model for joint collaborative filtering of ratings and text reviews through a sum of simple co-clusterings. The simple structure of our model yields easily interpretable recommendations. Even with a simple, succinct structure, our model outperforms competitors in terms of predicting ratings with reviews.