 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCase-Based Calibration of Adaptive Reasoning and Execution for LLM Tool Use
May 14, 2026Tool use extends large language models beyond parametric knowledge, but reliable execution requires balancing appropriate reasoning depth with strict structural validity. We approach this problem from a case-based perspective to present CAST, a case-driven framework that treats historical execution trajectories as structured cases. Instead of reusing raw exemplar outputs, CAST extracts case-derived signals to identify complexity profiles for estimating optimal reasoning strategies, alongside failure profiles to map likely structural breakdowns. The framework translates this knowledge into a fine-grained reward design and adaptive reasoning, enabling the model to autonomously internalize case-based strategies during reinforcement learning. Experiments on BFCLv2 and ToolBench demonstrate that CAST improves both schema-faithful execution and task-level tool-use success while reducing unnecessary deliberation. The approach achieves up to 5.85 percentage points gain in overall execution accuracy and reduces average reasoning length by 26%, significantly mitigating high-impact structural errors. Ultimately, this demonstrates how historical execution cases can provide reusable adaptation knowledge for calibrated tool use.
The Auton Agentic AI Framework
Feb 27, 2026The field of Artificial Intelligence is undergoing a transition from Generative AI -- probabilistic generation of text and images -- to Agentic AI, in which autonomous systems execute actions within external environments on behalf of users. This transition exposes a fundamental architectural mismatch: Large Language Models (LLMs) produce stochastic, unstructured outputs, whereas the backend infrastructure they must control -- databases, APIs, cloud services -- requires deterministic, schema-conformant inputs. The present paper describes the Auton Agentic AI Framework, a principled architecture for standardizing the creation, execution, and governance of autonomous agent systems. The framework is organized around a strict separation between the Cognitive Blueprint, a declarative, language-agnostic specification of agent identity and capabilities, and the Runtime Engine, the platform-specific execution substrate that instantiates and runs the agent. This separation enables cross-language portability, formal auditability, and modular tool integration via the Model Context Protocol (MCP). The paper formalizes the agent execution model as an augmented Partially Observable Markov Decision Process (POMDP) with a latent reasoning space, introduces a hierarchical memory consolidation architecture inspired by biological episodic memory systems, defines a constraint manifold formalism for safety enforcement via policy projection rather than post-hoc filtering, presents a three-level self-evolution framework spanning in-context adaptation through reinforcement learning, and describes runtime optimizations -- including parallel graph execution, speculative inference, and dynamic context pruning -- that reduce end-to-end latency for multi-step agent workflows.
STEM: Scaling Transformers with Embedding Modules
Jan 15, 2026Fine-grained sparsity promises higher parametric capacity without proportional per-token compute, but often suffers from training instability, load balancing, and communication overhead. We introduce STEM (Scaling Transformers with Embedding Modules), a static, token-indexed approach that replaces the FFN up-projection with a layer-local embedding lookup while keeping the gate and down-projection dense. This removes runtime routing, enables CPU offload with asynchronous prefetch, and decouples capacity from both per-token FLOPs and cross-device communication. Empirically, STEM trains stably despite extreme sparsity. It improves downstream performance over dense baselines while reducing per-token FLOPs and parameter accesses (eliminating roughly one-third of FFN parameters). STEM learns embedding spaces with large angular spread which enhances its knowledge storage capacity. More interestingly, this enhanced knowledge capacity comes with better interpretability. The token-indexed nature of STEM embeddings allows simple ways to perform knowledge editing and knowledge injection in an interpretable manner without any intervention in the input text or additional computation. In addition, STEM strengthens long-context performance: as sequence length grows, more distinct parameters are activated, yielding practical test-time capacity scaling. Across 350M and 1B model scales, STEM delivers up to ~3--4% accuracy improvements overall, with notable gains on knowledge and reasoning-heavy benchmarks (ARC-Challenge, OpenBookQA, GSM8K, MMLU). Overall, STEM is an effective way of scaling parametric memory while providing better interpretability, better training stability and improved efficiency.
Param$Δ$ for Direct Weight Mixing: Post-Train Large Language Model at Zero Cost
Apr 23, 2025The post-training phase of large language models is essential for enhancing capabilities such as instruction-following, reasoning, and alignment with human preferences. However, it demands extensive high-quality data and poses risks like overfitting, alongside significant computational costs due to repeated post-training and evaluation after each base model update. This paper introduces $Param\Delta$, a novel method that streamlines post-training by transferring knowledge from an existing post-trained model to a newly updated base model with ZERO additional training. By computing the difference between post-trained model weights ($\Theta_\text{post}$) and base model weights ($\Theta_\text{base}$), and adding this to the updated base model ($\Theta'_\text{base}$), we define $Param\Delta$ Model as: $\Theta_{\text{Param}\Delta} = \Theta_\text{post} - \Theta_\text{base} + \Theta'_\text{base}$. This approach surprisingly equips the new base model with post-trained capabilities, achieving performance comparable to direct post-training. We did analysis on LLama3, Llama3.1, Qwen, and DeepSeek-distilled models. Results indicate $Param\Delta$ Model effectively replicates traditional post-training. For example, the $Param\Delta$ Model obtained from 70B Llama3-inst, Llama3-base, Llama3.1-base models attains approximately 95\% of Llama3.1-inst model's performance on average. $Param\Delta$ brings a new perspective on how to fully leverage models in the open-weight community, where checkpoints for base and instruct models are readily available and frequently updated, by providing a cost-free framework to accelerate the iterative cycle of model development.
* Published as a conference paper at ICLR 2025
LLM-Augmented Retrieval: Enhancing Retrieval Models Through Language Models and Doc-Level Embedding
Apr 08, 2024Recently embedding-based retrieval or dense retrieval have shown state of the art results, compared with traditional sparse or bag-of-words based approaches. This paper introduces a model-agnostic doc-level embedding framework through large language model (LLM) augmentation. In addition, it also improves some important components in the retrieval model training process, such as negative sampling, loss function, etc. By implementing this LLM-augmented retrieval framework, we have been able to significantly improve the effectiveness of widely-used retriever models such as Bi-encoders (Contriever, DRAGON) and late-interaction models (ColBERTv2), thereby achieving state-of-the-art results on LoTTE datasets and BEIR datasets.
Federated Learning Incentive Mechanism under Buyers' Auction Market
Sep 10, 2023



Auction-based Federated Learning (AFL) enables open collaboration among self-interested data consumers and data owners. Existing AFL approaches are commonly under the assumption of sellers' market in that the service clients as sellers are treated as scarce resources so that the aggregation servers as buyers need to compete the bids. Yet, as the technology progresses, an increasing number of qualified clients are now capable of performing federated learning tasks, leading to shift from sellers' market to a buyers' market. In this paper, we shift the angle by adapting the procurement auction framework, aiming to explain the pricing behavior under buyers' market. Our modeling starts with basic setting under complete information, then move further to the scenario where sellers' information are not fully observable. In order to select clients with high reliability and data quality, and to prevent from external attacks, we utilize a blockchain-based reputation mechanism. The experimental results validate the effectiveness of our approach.
Lossless Image Compression through Super-Resolution
Apr 06, 2020

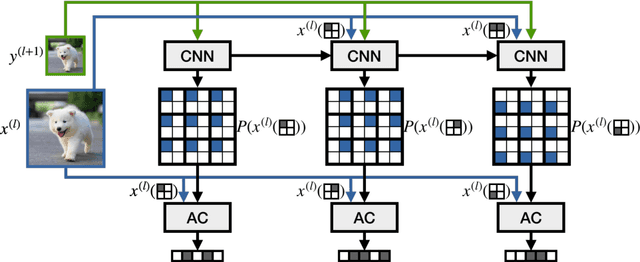
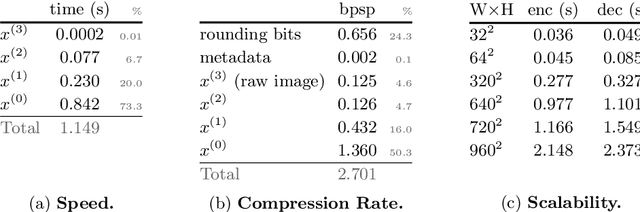
We introduce a simple and efficient lossless image compression algorithm. We store a low resolution version of an image as raw pixels, followed by several iterations of lossless super-resolution. For lossless super-resolution, we predict the probability of a high-resolution image, conditioned on the low-resolution input, and use entropy coding to compress this super-resolution operator. Super-Resolution based Compression (SReC) is able to achieve state-of-the-art compression rates with practical runtimes on large datasets. Code is available online at https://github.com/caoscott/SReC.