 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHL-Net: Heterophily Learning Network for Scene Graph Generation
May 04, 2022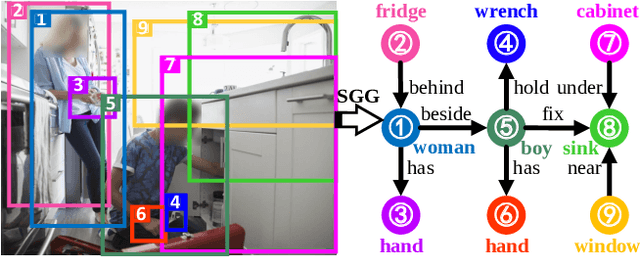
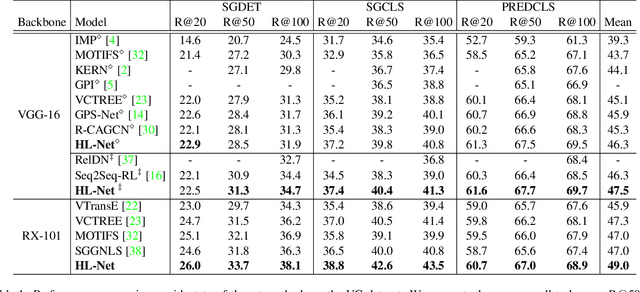
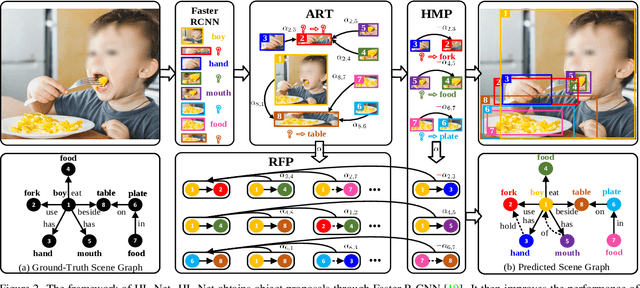
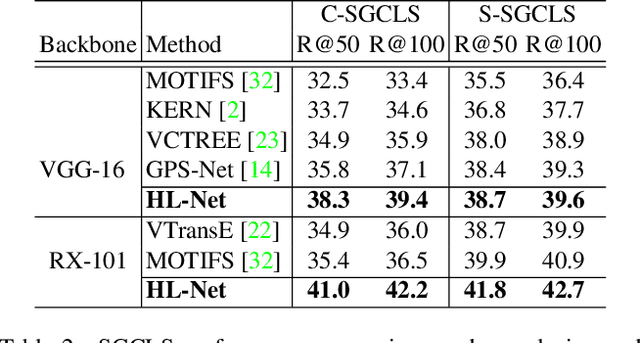
Scene graph generation (SGG) aims to detect objects and predict their pairwise relationships within an image. Current SGG methods typically utilize graph neural networks (GNNs) to acquire context information between objects/relationships. Despite their effectiveness, however, current SGG methods only assume scene graph homophily while ignoring heterophily. Accordingly, in this paper, we propose a novel Heterophily Learning Network (HL-Net) to comprehensively explore the homophily and heterophily between objects/relationships in scene graphs. More specifically, HL-Net comprises the following 1) an adaptive reweighting transformer module, which adaptively integrates the information from different layers to exploit both the heterophily and homophily in objects; 2) a relationship feature propagation module that efficiently explores the connections between relationships by considering heterophily in order to refine the relationship representation; 3) a heterophily-aware message-passing scheme to further distinguish the heterophily and homophily between objects/relationships, thereby facilitating improved message passing in graphs. We conducted extensive experiments on two public datasets: Visual Genome (VG) and Open Images (OI). The experimental results demonstrate the superiority of our proposed HL-Net over existing state-of-the-art approaches. In more detail, HL-Net outperforms the second-best competitors by 2.1$\%$ on the VG dataset for scene graph classification and 1.2$\%$ on the IO dataset for the final score. Code is available at https://github.com/siml3/HL-Net.
RU-Net: Regularized Unrolling Network for Scene Graph Generation
May 03, 2022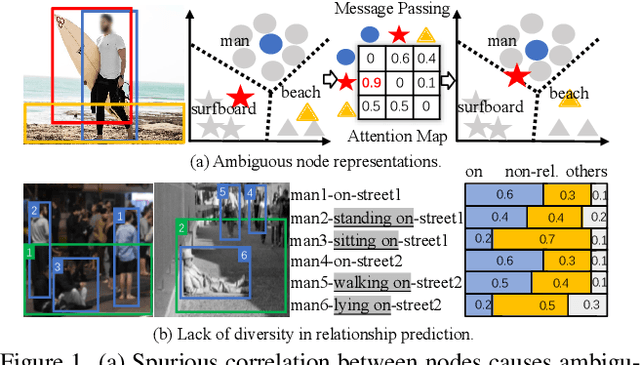
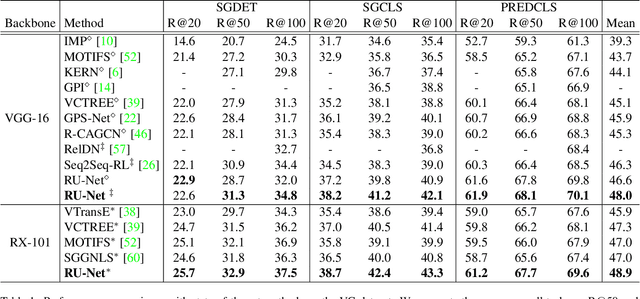
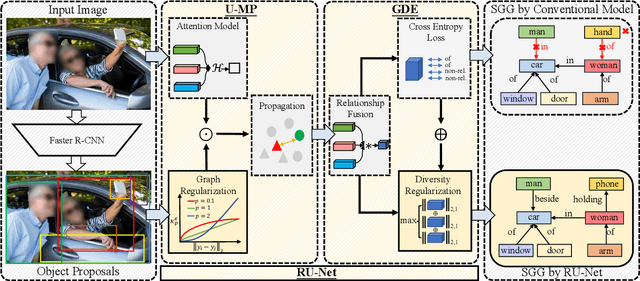
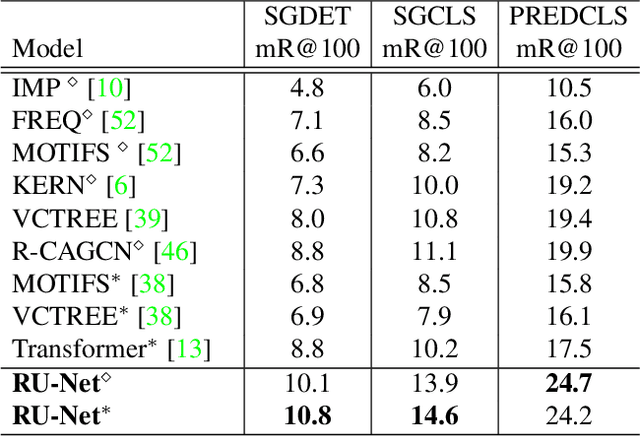
Scene graph generation (SGG) aims to detect objects and predict the relationships between each pair of objects. Existing SGG methods usually suffer from several issues, including 1) ambiguous object representations, as graph neural network-based message passing (GMP) modules are typically sensitive to spurious inter-node correlations, and 2) low diversity in relationship predictions due to severe class imbalance and a large number of missing annotations. To address both problems, in this paper, we propose a regularized unrolling network (RU-Net). We first study the relation between GMP and graph Laplacian denoising (GLD) from the perspective of the unrolling technique, determining that GMP can be formulated as a solver for GLD. Based on this observation, we propose an unrolled message passing module and introduce an $\ell_p$-based graph regularization to suppress spurious connections between nodes. Second, we propose a group diversity enhancement module that promotes the prediction diversity of relationships via rank maximization. Systematic experiments demonstrate that RU-Net is effective under a variety of settings and metrics. Furthermore, RU-Net achieves new state-of-the-arts on three popular databases: VG, VRD, and OI. Code is available at https://github.com/siml3/RU-Net.
Few-Shot Head Swapping in the Wild
Apr 27, 2022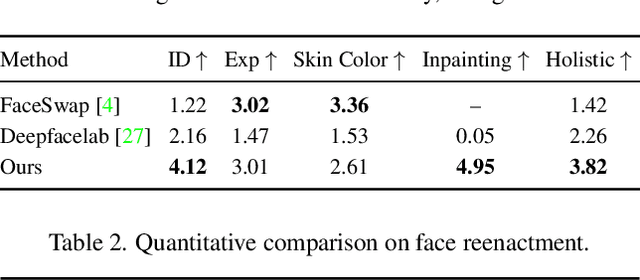
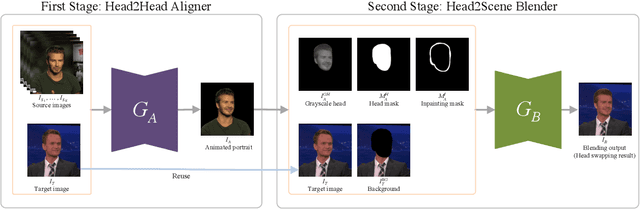
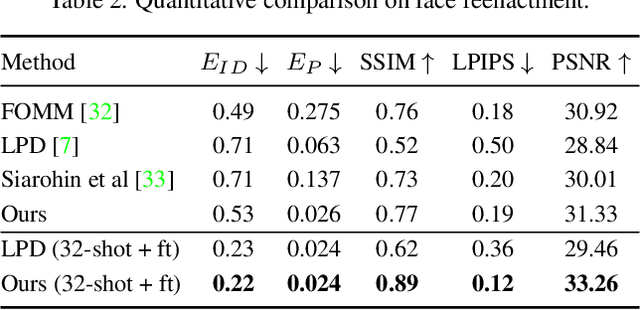
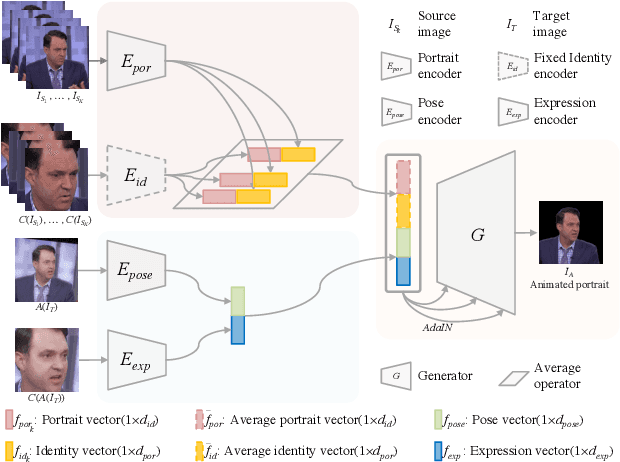
The head swapping task aims at flawlessly placing a source head onto a target body, which is of great importance to various entertainment scenarios. While face swapping has drawn much attention, the task of head swapping has rarely been explored, particularly under the few-shot setting. It is inherently challenging due to its unique needs in head modeling and background blending. In this paper, we present the Head Swapper (HeSer), which achieves few-shot head swapping in the wild through two delicately designed modules. Firstly, a Head2Head Aligner is devised to holistically migrate pose and expression information from the target to the source head by examining multi-scale information. Secondly, to tackle the challenges of skin color variations and head-background mismatches in the swapping procedure, a Head2Scene Blender is introduced to simultaneously modify facial skin color and fill mismatched gaps in the background around the head. Particularly, seamless blending is achieved with the help of a Semantic-Guided Color Reference Creation procedure and a Blending UNet. Extensive experiments demonstrate that the proposed method produces superior head swapping results in a variety of scenes.
MobileFaceSwap: A Lightweight Framework for Video Face Swapping
Jan 11, 2022
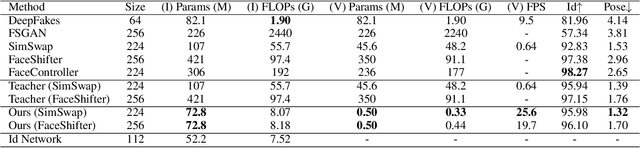
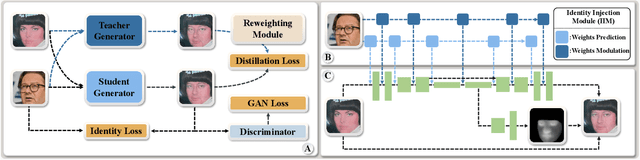
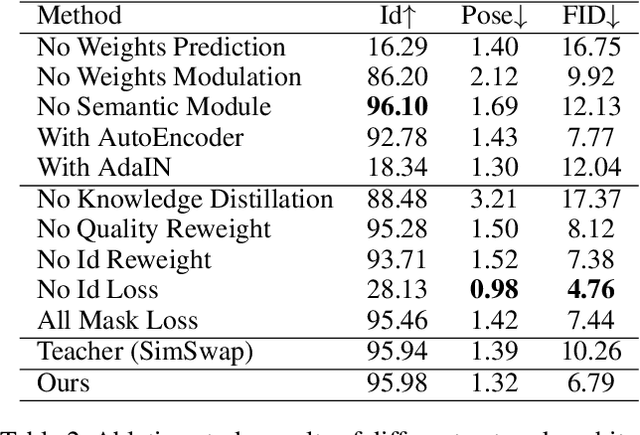
Advanced face swapping methods have achieved appealing results. However, most of these methods have many parameters and computations, which makes it challenging to apply them in real-time applications or deploy them on edge devices like mobile phones. In this work, we propose a lightweight Identity-aware Dynamic Network (IDN) for subject-agnostic face swapping by dynamically adjusting the model parameters according to the identity information. In particular, we design an efficient Identity Injection Module (IIM) by introducing two dynamic neural network techniques, including the weights prediction and weights modulation. Once the IDN is updated, it can be applied to swap faces given any target image or video. The presented IDN contains only 0.50M parameters and needs 0.33G FLOPs per frame, making it capable for real-time video face swapping on mobile phones. In addition, we introduce a knowledge distillation-based method for stable training, and a loss reweighting module is employed to obtain better synthesized results. Finally, our method achieves comparable results with the teacher models and other state-of-the-art methods.
Quality-aware Part Models for Occluded Person Re-identification
Jan 01, 2022
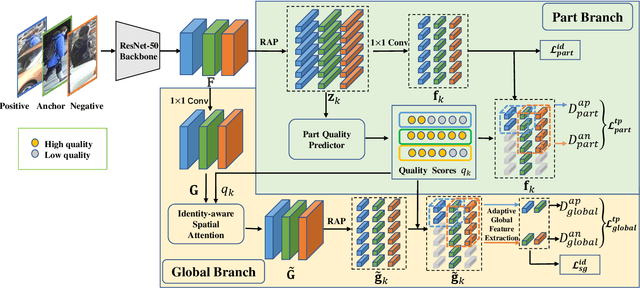
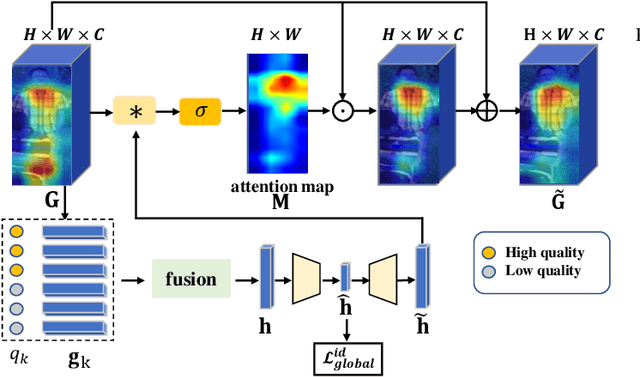

Occlusion poses a major challenge for person re-identification (ReID). Existing approaches typically rely on outside tools to infer visible body parts, which may be suboptimal in terms of both computational efficiency and ReID accuracy. In particular, they may fail when facing complex occlusions, such as those between pedestrians. Accordingly, in this paper, we propose a novel method named Quality-aware Part Models (QPM) for occlusion-robust ReID. First, we propose to jointly learn part features and predict part quality scores. As no quality annotation is available, we introduce a strategy that automatically assigns low scores to occluded body parts, thereby weakening the impact of occluded body parts on ReID results. Second, based on the predicted part quality scores, we propose a novel identity-aware spatial attention (ISA) module. In this module, a coarse identity-aware feature is utilized to highlight pixels of the target pedestrian, so as to handle the occlusion between pedestrians. Third, we design an adaptive and efficient approach for generating global features from common non-occluded regions with respect to each image pair. This design is crucial, but is often ignored by existing methods. QPM has three key advantages: 1) it does not rely on any outside tools in either the training or inference stages; 2) it handles occlusions caused by both objects and other pedestrians;3) it is highly computationally efficient. Experimental results on four popular databases for occluded ReID demonstrate that QPM consistently outperforms state-of-the-art methods by significant margins. The code of QPM will be released.
Uncertainty-aware Clustering for Unsupervised Domain Adaptive Object Re-identification
Aug 22, 2021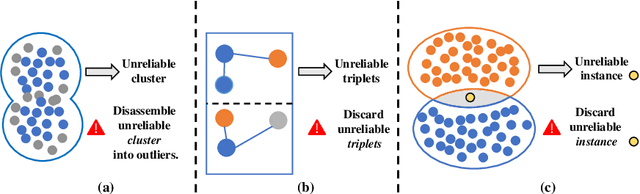
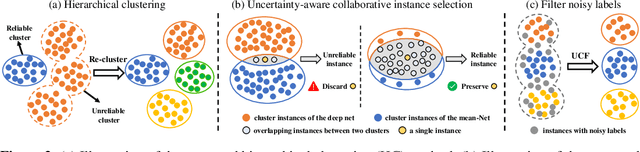
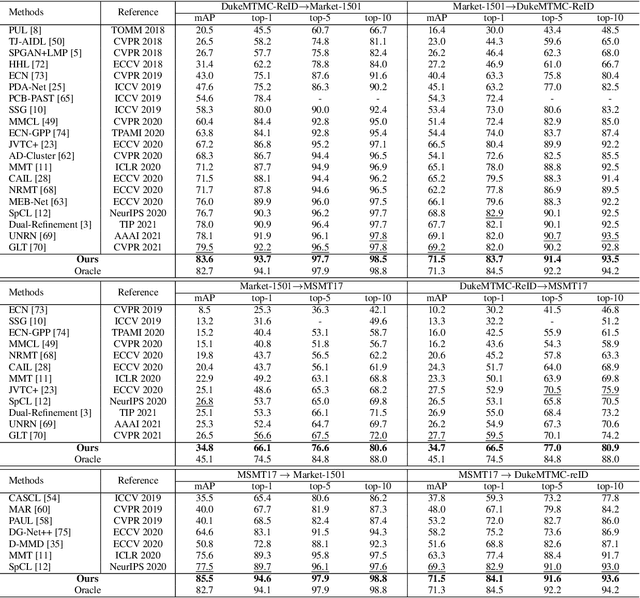
Unsupervised Domain Adaptive (UDA) object re-identification (Re-ID) aims at adapting a model trained on a labeled source domain to an unlabeled target domain. State-of-the-art object Re-ID approaches adopt clustering algorithms to generate pseudo-labels for the unlabeled target domain. However, the inevitable label noise caused by the clustering procedure significantly degrades the discriminative power of Re-ID model. To address this problem, we propose an uncertainty-aware clustering framework (UCF) for UDA tasks. First, a novel hierarchical clustering scheme is proposed to promote clustering quality. Second, an uncertainty-aware collaborative instance selection method is introduced to select images with reliable labels for model training. Combining both techniques effectively reduces the impact of noisy labels. In addition, we introduce a strong baseline that features a compact contrastive loss. Our UCF method consistently achieves state-of-the-art performance in multiple UDA tasks for object Re-ID, and significantly reduces the gap between unsupervised and supervised Re-ID performance. In particular, the performance of our unsupervised UCF method in the MSMT17$\to$Market1501 task is better than that of the fully supervised setting on Market1501. The code of UCF is available at https://github.com/Wang-pengfei/UCF.
Semantically Self-Aligned Network for Text-to-Image Part-aware Person Re-identification
Aug 09, 2021
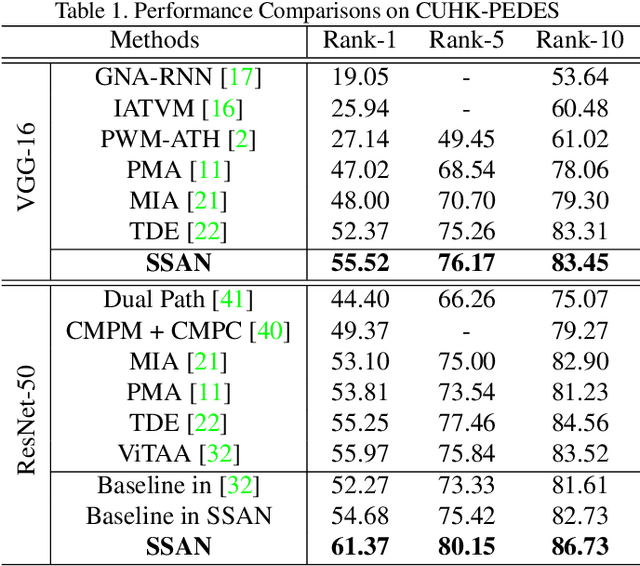
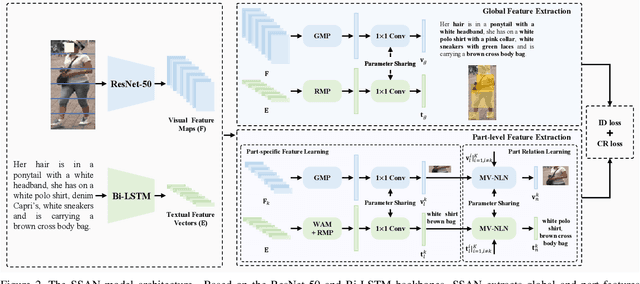
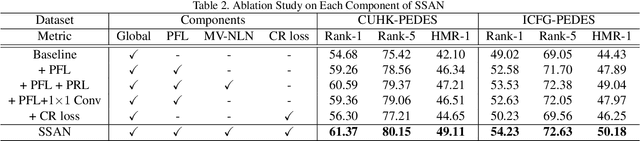
Text-to-image person re-identification (ReID) aims to search for images containing a person of interest using textual descriptions. However, due to the significant modality gap and the large intra-class variance in textual descriptions, text-to-image ReID remains a challenging problem. Accordingly, in this paper, we propose a Semantically Self-Aligned Network (SSAN) to handle the above problems. First, we propose a novel method that automatically extracts semantically aligned part-level features from the two modalities. Second, we design a multi-view non-local network that captures the relationships between body parts, thereby establishing better correspondences between body parts and noun phrases. Third, we introduce a Compound Ranking (CR) loss that makes use of textual descriptions for other images of the same identity to provide extra supervision, thereby effectively reducing the intra-class variance in textual features. Finally, to expedite future research in text-to-image ReID, we build a new database named ICFG-PEDES. Extensive experiments demonstrate that SSAN outperforms state-of-the-art approaches by significant margins. Both the new ICFG-PEDES database and the SSAN code are available at https://github.com/zifyloo/SSAN.
Attention-guided Progressive Mapping for Profile Face Recognition
Jun 29, 2021
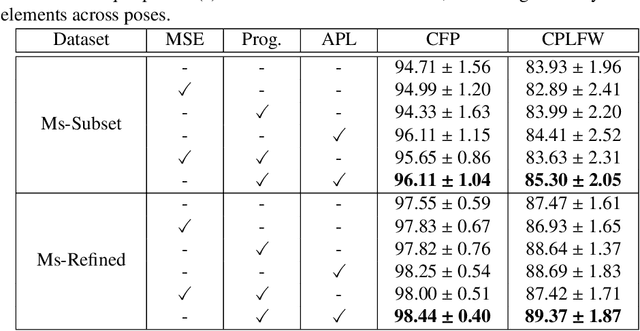
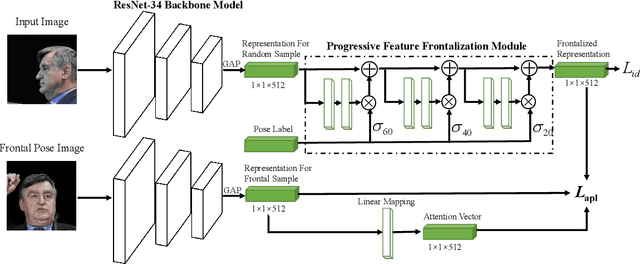
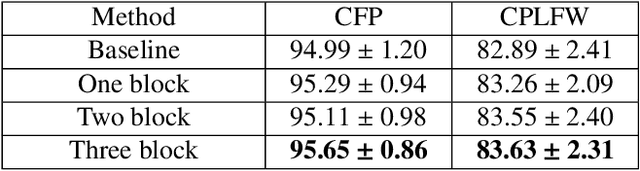
The past few years have witnessed great progress in the domain of face recognition thanks to advances in deep learning. However, cross pose face recognition remains a significant challenge. It is difficult for many deep learning algorithms to narrow the performance gap caused by pose variations; the main reasons for this relate to the intra-class discrepancy between face images in different poses and the pose imbalances of training datasets. Learning pose-robust features by traversing to the feature space of frontal faces provides an effective and cheap way to alleviate this problem. In this paper, we present a method for progressively transforming profile face representations to the canonical pose with an attentive pair-wise loss. Firstly, to reduce the difficulty of directly transforming the profile face features into a frontal pose, we propose to learn the feature residual between the source pose and its nearby pose in a block-byblock fashion, and thus traversing to the feature space of a smaller pose by adding the learned residual. Secondly, we propose an attentive pair-wise loss to guide the feature transformation progressing in the most effective direction. Finally, our proposed progressive module and attentive pair-wise loss are light-weight and easy to implement, adding only about 7:5% extra parameters. Evaluations on the CFP and CPLFW datasets demonstrate the superiority of our proposed method. Code is available at https://github.com/hjy1312/AGPM.
Glance and Gaze: Inferring Action-aware Points for One-Stage Human-Object Interaction Detection
Apr 12, 2021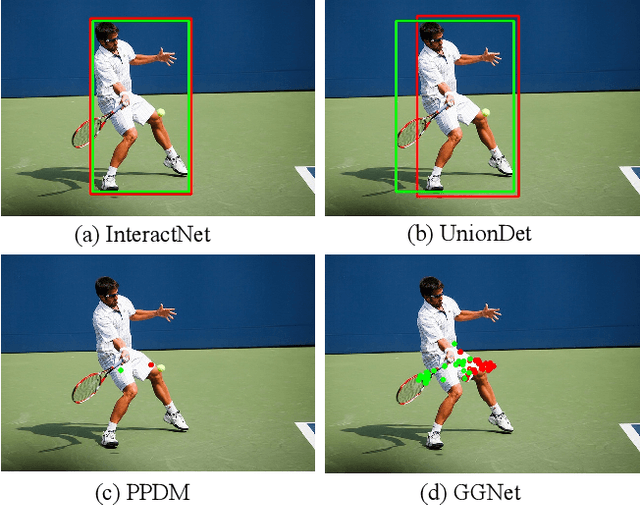
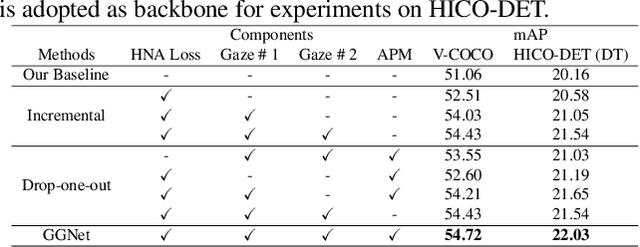
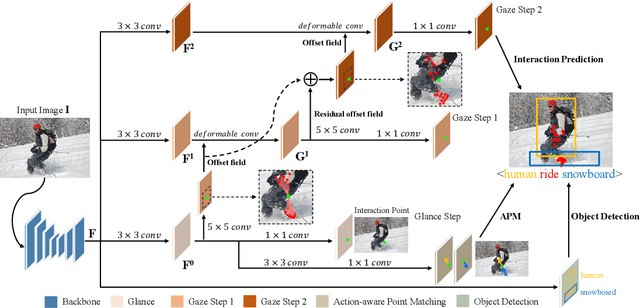
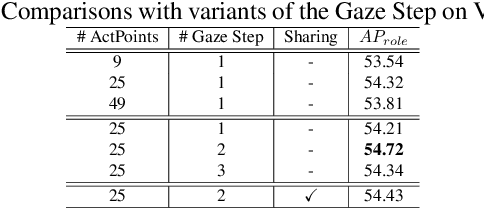
Modern human-object interaction (HOI) detection approaches can be divided into one-stage methods and twostage ones. One-stage models are more efficient due to their straightforward architectures, but the two-stage models are still advantageous in accuracy. Existing one-stage models usually begin by detecting predefined interaction areas or points, and then attend to these areas only for interaction prediction; therefore, they lack reasoning steps that dynamically search for discriminative cues. In this paper, we propose a novel one-stage method, namely Glance and Gaze Network (GGNet), which adaptively models a set of actionaware points (ActPoints) via glance and gaze steps. The glance step quickly determines whether each pixel in the feature maps is an interaction point. The gaze step leverages feature maps produced by the glance step to adaptively infer ActPoints around each pixel in a progressive manner. Features of the refined ActPoints are aggregated for interaction prediction. Moreover, we design an actionaware approach that effectively matches each detected interaction with its associated human-object pair, along with a novel hard negative attentive loss to improve the optimization of GGNet. All the above operations are conducted simultaneously and efficiently for all pixels in the feature maps. Finally, GGNet outperforms state-of-the-art methods by significant margins on both V-COCO and HICODET benchmarks. Code of GGNet is available at https: //github.com/SherlockHolmes221/GGNet.
On Universal Black-Box Domain Adaptation
Apr 10, 2021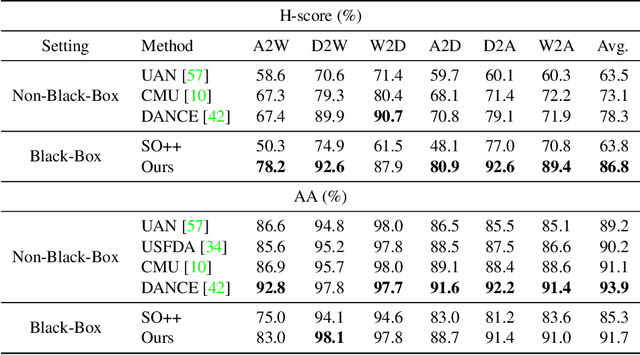
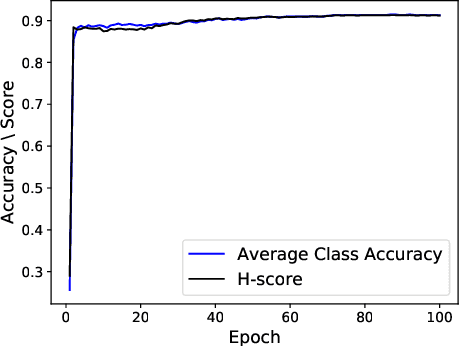
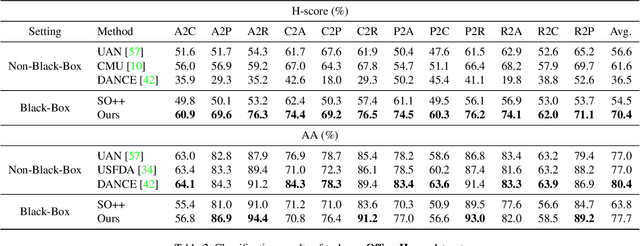

In this paper, we study an arguably least restrictive setting of domain adaptation in a sense of practical deployment, where only the interface of source model is available to the target domain, and where the label-space relations between the two domains are allowed to be different and unknown. We term such a setting as Universal Black-Box Domain Adaptation (UB$^2$DA). The great promise that UB$^2$DA makes, however, brings significant learning challenges, since domain adaptation can only rely on the predictions of unlabeled target data in a partially overlapped label space, by accessing the interface of source model. To tackle the challenges, we first note that the learning task can be converted as two subtasks of in-class\footnote{In this paper we use in-class (out-class) to describe the classes observed (not observed) in the source black-box model.} discrimination and out-class detection, which can be respectively learned by model distillation and entropy separation. We propose to unify them into a self-training framework, regularized by consistency of predictions in local neighborhoods of target samples. Our framework is simple, robust, and easy to be optimized. Experiments on domain adaptation benchmarks show its efficacy. Notably, by accessing the interface of source model only, our framework outperforms existing methods of universal domain adaptation that make use of source data and/or source models, with a newly proposed (and arguably more reasonable) metric of H-score, and performs on par with them with the metric of averaged class accuracy.