 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCP-Atlas: A Large-Scale Benchmark for Tool-Use Competency with Real MCP Servers
Jan 31, 2026The Model Context Protocol (MCP) is rapidly becoming the standard interface for Large Language Models (LLMs) to discover and invoke external tools. However, existing evaluations often fail to capture the complexity of real-world scenarios, relying on restricted toolsets, simplistic workflows, or subjective LLM-as-a-judge metrics. We introduce MCP-Atlas, a large-scale benchmark for evaluating tool-use competency, comprising 36 real MCP servers and 220 tools. It includes 1,000 tasks designed to assess tool-use competency in realistic, multi-step workflows. Tasks use natural language prompts that avoid naming specific tools or servers, requiring agents to identify and orchestrate 3-6 tool calls across multiple servers. We score tasks using a claims-based rubric that awards partial credit based on the factual claims satisfied in the model's final answer, complemented by internal diagnostics on tool discovery, parameterization, syntax, error recovery, and efficiency. Evaluation results on frontier models reveal that top models achieve pass rates exceeding 50%, with primary failures arising from inadequate tool usage and task understanding. We release the task schema, containerized harness, and a 500-task public subset of the benchmark dataset to facilitate reproducible comparisons and advance the development of robust, tool-augmented agents.
ResearchRubrics: A Benchmark of Prompts and Rubrics For Evaluating Deep Research Agents
Nov 10, 2025Deep Research (DR) is an emerging agent application that leverages large language models (LLMs) to address open-ended queries. It requires the integration of several capabilities, including multi-step reasoning, cross-document synthesis, and the generation of evidence-backed, long-form answers. Evaluating DR remains challenging because responses are lengthy and diverse, admit many valid solutions, and often depend on dynamic information sources. We introduce ResearchRubrics, a standardized benchmark for DR built with over 2,800+ hours of human labor that pairs realistic, domain-diverse prompts with 2,500+ expert-written, fine-grained rubrics to assess factual grounding, reasoning soundness, and clarity. We also propose a new complexity framework for categorizing DR tasks along three axes: conceptual breadth, logical nesting, and exploration. In addition, we develop human and model-based evaluation protocols that measure rubric adherence for DR agents. We evaluate several state-of-the-art DR systems and find that even leading agents like Gemini's DR and OpenAI's DR achieve under 68% average compliance with our rubrics, primarily due to missed implicit context and inadequate reasoning about retrieved information. Our results highlight the need for robust, scalable assessment of deep research capabilities, to which end we release ResearchRubrics(including all prompts, rubrics, and evaluation code) to facilitate progress toward well-justified research assistants.
Position: Require Frontier AI Labs To Release Small "Analog" Models
Oct 15, 2025Recent proposals for regulating frontier AI models have sparked concerns about the cost of safety regulation, and most such regulations have been shelved due to the safety-innovation tradeoff. This paper argues for an alternative regulatory approach that ensures AI safety while actively promoting innovation: mandating that large AI laboratories release small, openly accessible analog models (scaled-down versions) trained similarly to and distilled from their largest proprietary models. Analog models serve as public proxies, allowing broad participation in safety verification, interpretability research, and algorithmic transparency without forcing labs to disclose their full-scale models. Recent research demonstrates that safety and interpretability methods developed using these smaller models generalize effectively to frontier-scale systems. By enabling the wider research community to directly investigate and innovate upon accessible analogs, our policy substantially reduces the regulatory burden and accelerates safety advancements. This mandate promises minimal additional costs, leveraging reusable resources like data and infrastructure, while significantly contributing to the public good. Our hope is not only that this policy be adopted, but that it illustrates a broader principle supporting fundamental research in machine learning: deeper understanding of models relaxes the safety-innovation tradeoff and lets us have more of both.
REL: Working out is all you need
Dec 05, 2024



Recent developments, particularly OpenAI's O1 model, have demonstrated the remarkable potential of Large Language Models (LLMs) for complex reasoning tasks. Through analysis of O1's outputs and provided sample Chain-of-Thought (CoT) demonstrations, we observe that it approaches problem-solving in a distinctly human-like manner, systematically brainstorming ideas, testing hypotheses, verifying results, and planning comprehensive solutions. These sophisticated reasoning capabilities remain notably absent in other state-of-the-art language models. In this paper, we hypothesize that this performance gap stems from the limited availability of high-quality reasoning process data in current training sets. We demonstrate that by constructing a specialized dataset focused on explicit problem-solving workflows ("worked solutions"), we can elicit substantially improved planning capabilities from existing models. Additionally, we propose the Reasoning Enhancement Loop (REL), a method for generating synthetic worked solutions.
Adversarial Multi-Agent Evaluation of Large Language Models through Iterative Debates
Oct 07, 2024


This paper explores optimal architectures for evaluating the outputs of large language models (LLMs) using LLMs themselves. We propose a novel framework that interprets LLMs as advocates within an ensemble of interacting agents, allowing them to defend their answers and reach conclusions through a judge and jury system. This approach offers a more dynamic and comprehensive evaluation process compared to traditional human-based assessments or automated metrics. We discuss the motivation behind this framework, its key components, and comparative advantages. We also present a probabilistic model to evaluate the error reduction achieved by iterative advocate systems. Finally, we outline experiments to validate the effectiveness of multi-advocate architectures and discuss future research directions.
An Application of Newsboy Problem in Supply Chain Optimisation of Online Fashion E-Commerce
Jul 06, 2020

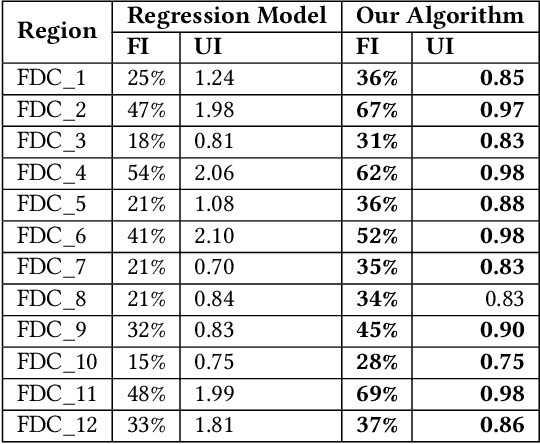

We describe a supply chain optimization model deployed in an online fashion e-commerce company in India called Myntra. Our model is simple, elegant and easy to put into service. The model utilizes historic data and predicts the quantity of Stock Keeping Units (SKUs) to hold so that the metrics "Fulfilment Index" and "Utilization Index" are optimized. We present the mathematics central to our model as well as compare the performance of our model with baseline regression based solutions.