 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory Efficient Continual Learning for Neural Text Classification
Mar 09, 2022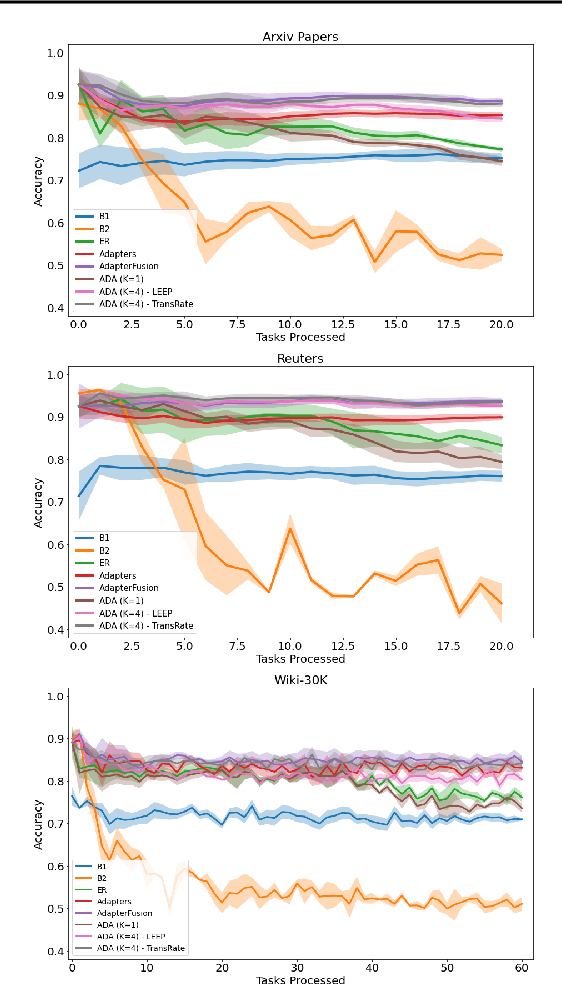
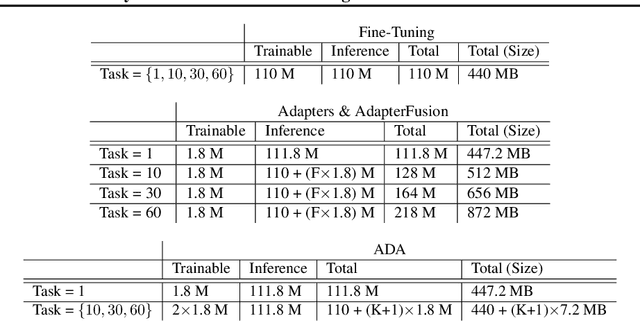
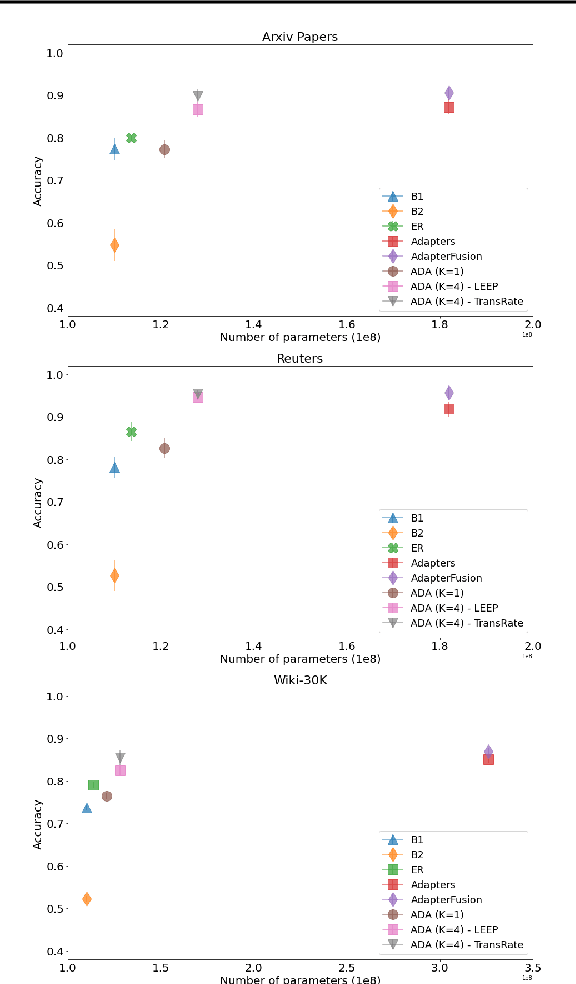
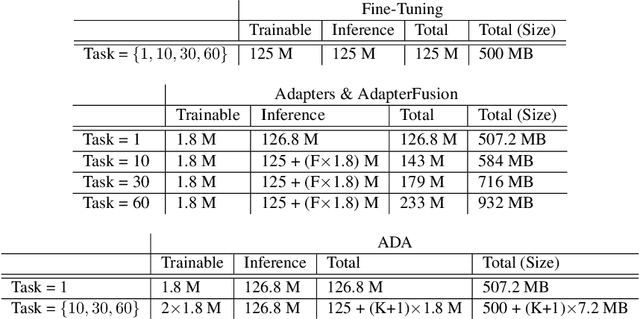
Learning text classifiers based on pre-trained language models has become the standard practice in natural language processing applications. Unfortunately, training large neural language models, such as transformers, from scratch is very costly and requires a vast amount of training data, which might not be available in the application domain of interest. Moreover, in many real-world scenarios, classes are uncovered as more data is seen, calling for class-incremental modelling approaches. In this work we devise a method to perform text classification using pre-trained models on a sequence of classification tasks provided in sequence. We formalize the problem as a continual learning problem where the algorithm learns new tasks without performance degradation on the previous ones and without re-training the model from scratch. We empirically demonstrate that our method requires significantly less model parameters compared to other state of the art methods and that it is significantly faster at inference time. The tight control on the number of model parameters, and so the memory, is not only improving efficiency. It is making possible the usage of the algorithm in real-world applications where deploying a solution with a constantly increasing memory consumption is just unrealistic. While our method suffers little forgetting, it retains a predictive performance on-par with state of the art but less memory efficient methods.
Meta-Forecasting by combining Global Deep Representations with Local Adaptation
Nov 12, 2021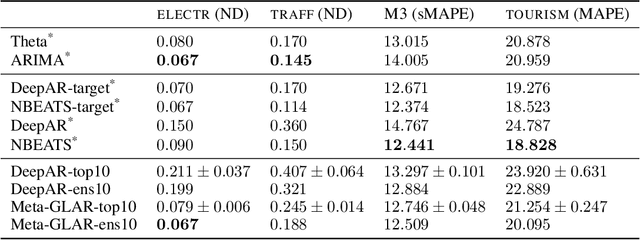
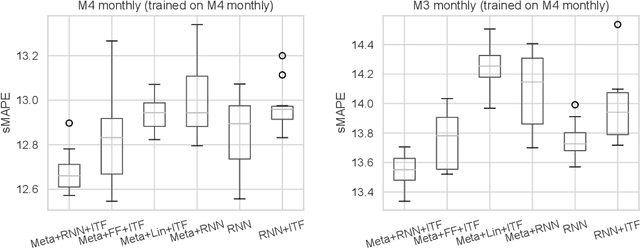
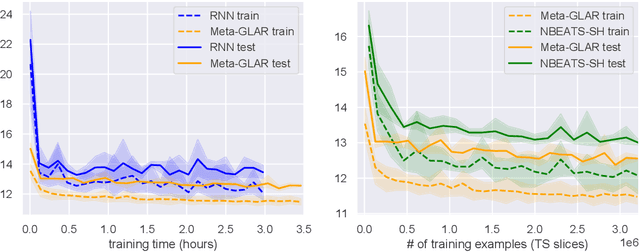

While classical time series forecasting considers individual time series in isolation, recent advances based on deep learning showed that jointly learning from a large pool of related time series can boost the forecasting accuracy. However, the accuracy of these methods suffers greatly when modeling out-of-sample time series, significantly limiting their applicability compared to classical forecasting methods. To bridge this gap, we adopt a meta-learning view of the time series forecasting problem. We introduce a novel forecasting method, called Meta Global-Local Auto-Regression (Meta-GLAR), that adapts to each time series by learning in closed-form the mapping from the representations produced by a recurrent neural network (RNN) to one-step-ahead forecasts. Crucially, the parameters ofthe RNN are learned across multiple time series by backpropagating through the closed-form adaptation mechanism. In our extensive empirical evaluation we show that our method is competitive with the state-of-the-art in out-of-sample forecasting accuracy reported in earlier work.
A multi-objective perspective on jointly tuning hardware and hyperparameters
Jun 10, 2021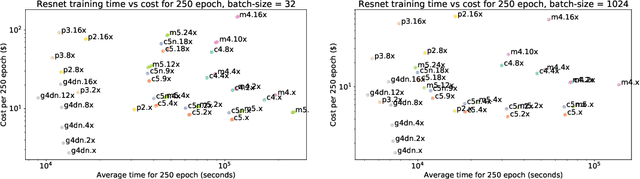
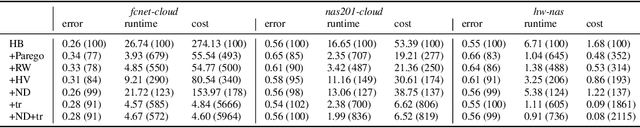
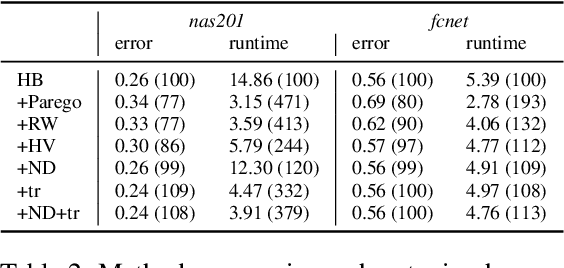
In addition to the best model architecture and hyperparameters, a full AutoML solution requires selecting appropriate hardware automatically. This can be framed as a multi-objective optimization problem: there is not a single best hardware configuration but a set of optimal ones achieving different trade-offs between cost and runtime. In practice, some choices may be overly costly or take days to train. To lift this burden, we adopt a multi-objective approach that selects and adapts the hardware configuration automatically alongside neural architectures and their hyperparameters. Our method builds on Hyperband and extends it in two ways. First, we replace the stopping rule used in Hyperband by a non-dominated sorting rule to preemptively stop unpromising configurations. Second, we leverage hyperparameter evaluations from related tasks via transfer learning by building a probabilistic estimate of the Pareto front that finds promising configurations more efficiently than random search. We show in extensive NAS and HPO experiments that both ingredients bring significant speed-ups and cost savings, with little to no impact on accuracy. In three benchmarks where hardware is selected in addition to hyperparameters, we obtain runtime and cost reductions of at least 5.8x and 8.8x, respectively. Furthermore, when applying our multi-objective method to the tuning of hyperparameters only, we obtain a 10\% improvement in runtime while maintaining the same accuracy on two popular NAS benchmarks.
Overfitting in Bayesian Optimization: an empirical study and early-stopping solution
Apr 16, 2021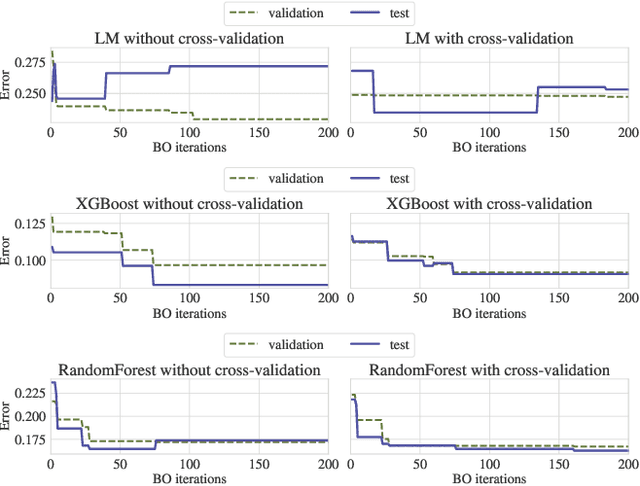
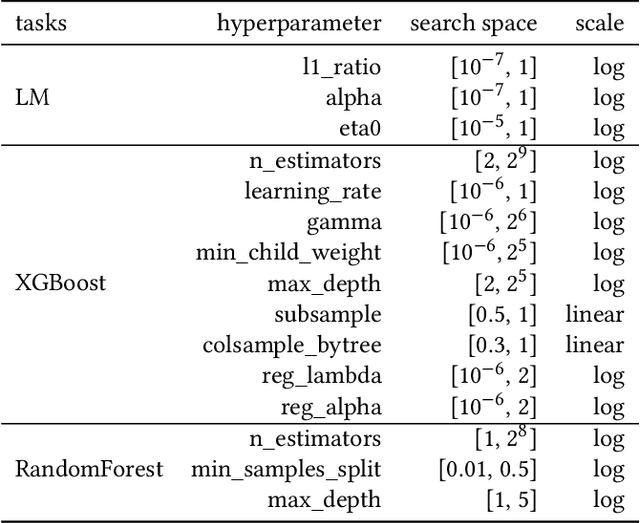
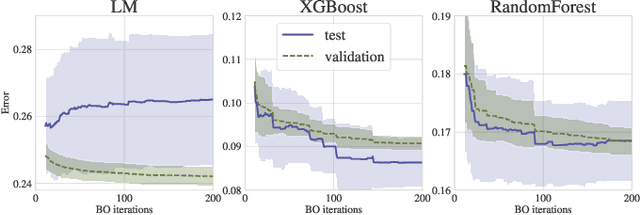
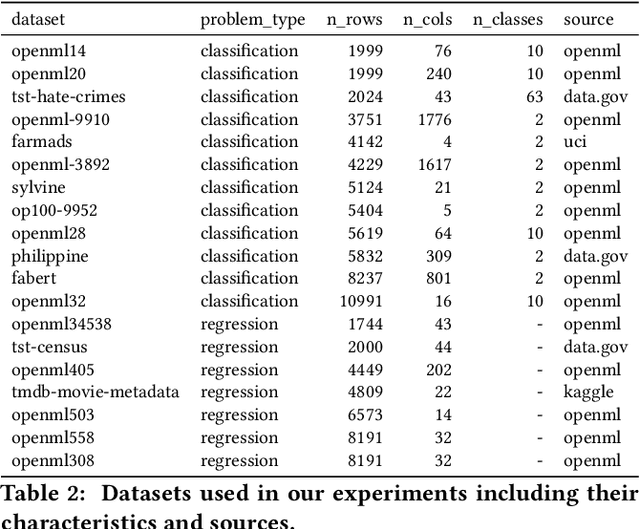
Bayesian Optimization (BO) is a successful methodology to tune the hyperparameters of machine learning algorithms. The user defines a metric of interest, such as the validation error, and BO finds the optimal hyperparameters that minimize it. However, the metric improvements on the validation set may not translate to the test set, especially on small datasets. In other words, BO can overfit. While cross-validation mitigates this, it comes with high computational cost. In this paper, we carry out the first systematic investigation of overfitting in BO and demonstrate that this is a serious yet often overlooked concern in practice. We propose the first problem-adaptive and interpretable criterion to early stop BO, reducing overfitting while mitigating the cost of cross-validation. Experimental results on real-world hyperparameter optimization tasks show that our approach can substantially reduce compute time with little to no loss of test accuracy,demonstrating a clear practical advantage over existing techniques.
BORE: Bayesian Optimization by Density-Ratio Estimation
Feb 17, 2021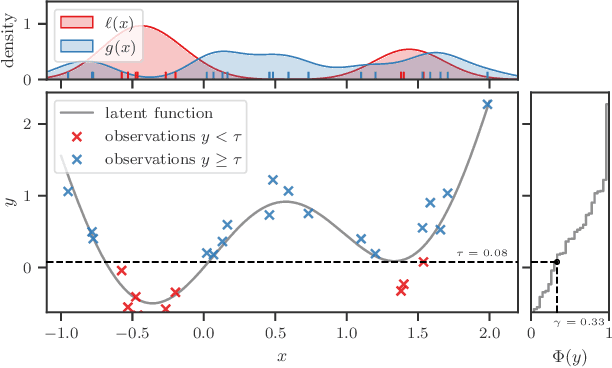

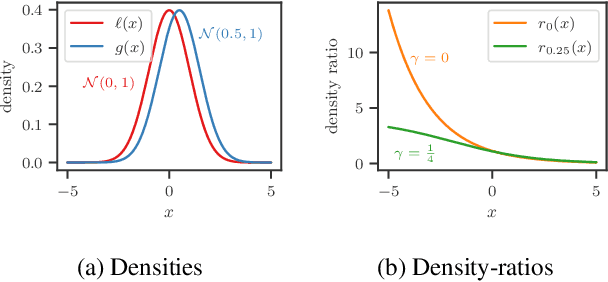

Bayesian optimization (BO) is among the most effective and widely-used blackbox optimization methods. BO proposes solutions according to an explore-exploit trade-off criterion encoded in an acquisition function, many of which are computed from the posterior predictive of a probabilistic surrogate model. Prevalent among these is the expected improvement (EI) function. The need to ensure analytical tractability of the predictive often poses limitations that can hinder the efficiency and applicability of BO. In this paper, we cast the computation of EI as a binary classification problem, building on the link between class-probability estimation and density-ratio estimation, and the lesser-known link between density-ratios and EI. By circumventing the tractability constraints, this reformulation provides numerous advantages, not least in terms of expressiveness, versatility, and scalability.
Model-based Asynchronous Hyperparameter Optimization
Mar 24, 2020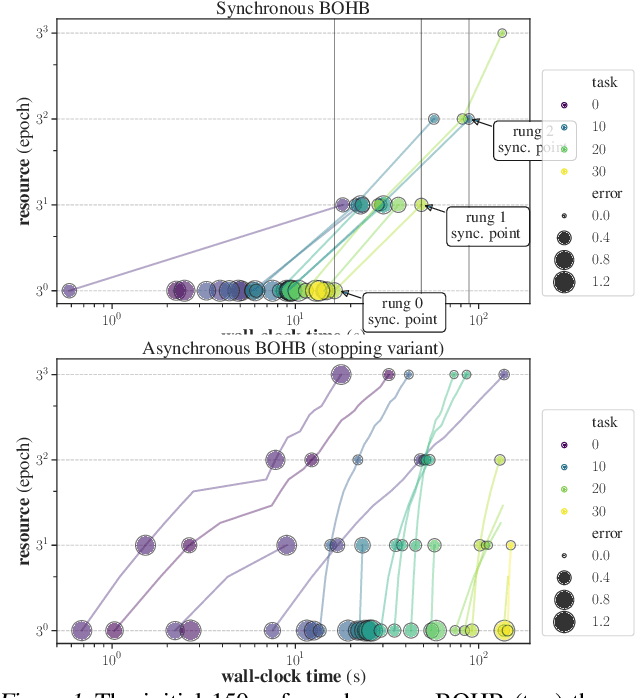


We introduce a model-based asynchronous multi-fidelity hyperparameter optimization (HPO) method, combining strengths of asynchronous Hyperband and Gaussian process-based Bayesian optimization. Our method obtains substantial speed-ups in wall-clock time over, both, synchronous and asynchronous Hyperband, as well as a prior model-based extension of the former. Candidate hyperparameters to evaluate are selected by a novel jointly dependent Gaussian process-based surrogate model over all resource levels, allowing evaluations at one level to be informed by evaluations gathered at all others. We benchmark several covariance functions and conduct extensive experiments on hyperparameter tuning for multi-layer perceptrons on tabular data, convolutional networks on image classification, and recurrent networks on language modelling, demonstrating the benefits of our approach.
Cost-aware Bayesian Optimization
Mar 22, 2020
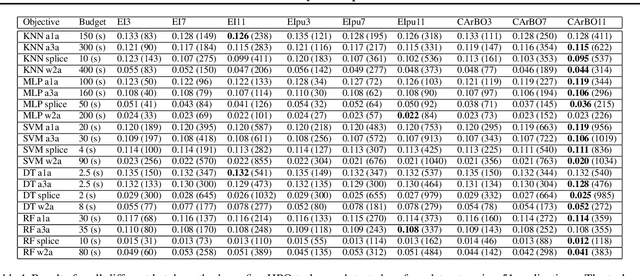
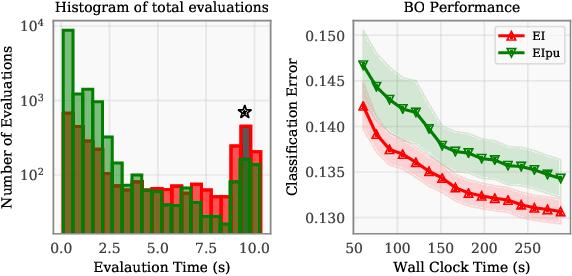
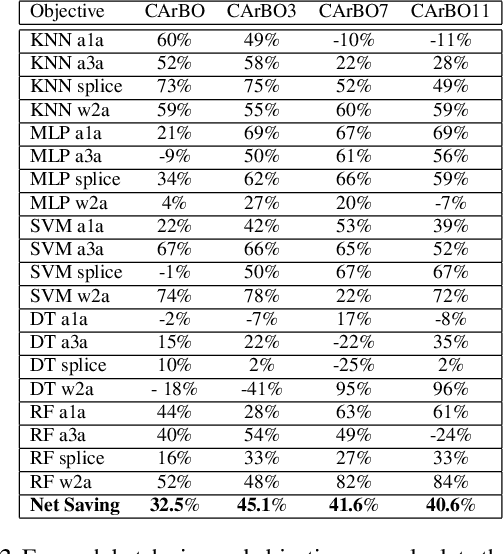
Bayesian optimization (BO) is a class of global optimization algorithms, suitable for minimizing an expensive objective function in as few function evaluations as possible. While BO budgets are typically given in iterations, this implicitly measures convergence in terms of iteration count and assumes each evaluation has identical cost. In practice, evaluation costs may vary in different regions of the search space. For example, the cost of neural network training increases quadratically with layer size, which is a typical hyperparameter. Cost-aware BO measures convergence with alternative cost metrics such as time, energy, or money, for which vanilla BO methods are unsuited. We introduce Cost Apportioned BO (CArBO), which attempts to minimize an objective function in as little cost as possible. CArBO combines a cost-effective initial design with a cost-cooled optimization phase which depreciates a learned cost model as iterations proceed. On a set of 20 black-box function optimization problems we show that, given the same cost budget, CArBO finds significantly better hyperparameter configurations than competing methods.
LEEP: A New Measure to Evaluate Transferability of Learned Representations
Feb 27, 2020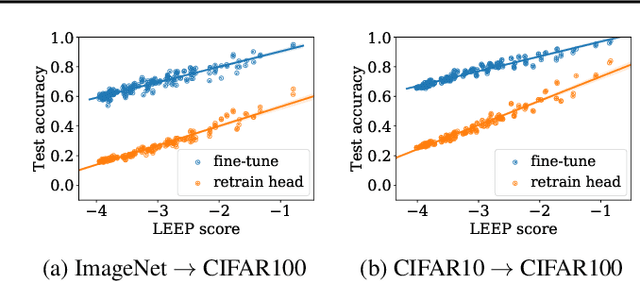
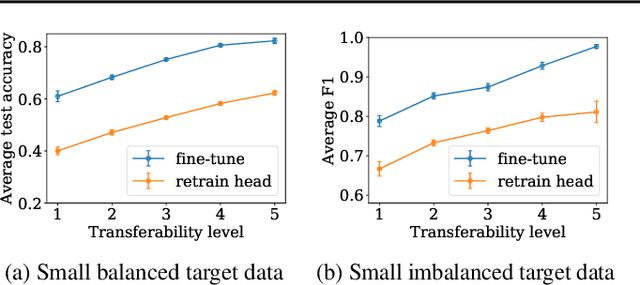
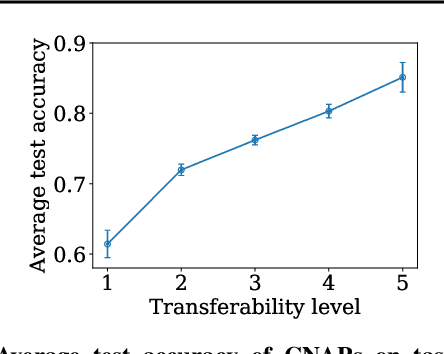
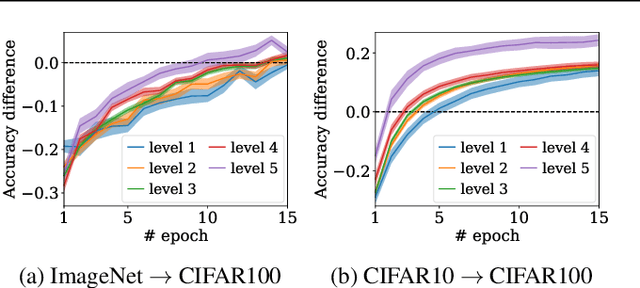
We introduce a new measure to evaluate the transferability of representations learned by classifiers. Our measure, the Log Expected Empirical Prediction (LEEP), is simple and easy to compute: when given a classifier trained on a source data set, it only requires running the target data set through this classifier once. We analyze the properties of LEEP theoretically and demonstrate its effectiveness empirically. Our analysis shows that LEEP can predict the performance and convergence speed of both transfer and meta-transfer learning methods, even for small or imbalanced data. Moreover, LEEP outperforms recently proposed transferability measures such as negative conditional entropy and H scores. Notably, when transferring from ImageNet to CIFAR100, LEEP can achieve up to 30% improvement compared to the best competing method in terms of the correlations with actual transfer accuracy.
Constrained Bayesian Optimization with Max-Value Entropy Search
Oct 15, 2019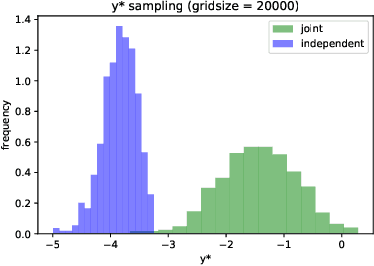
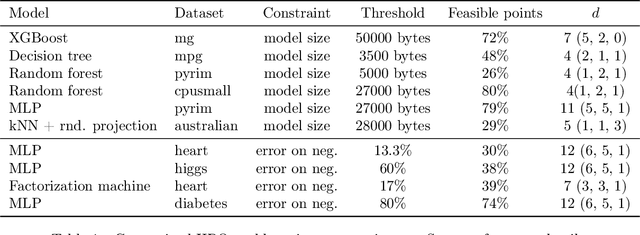
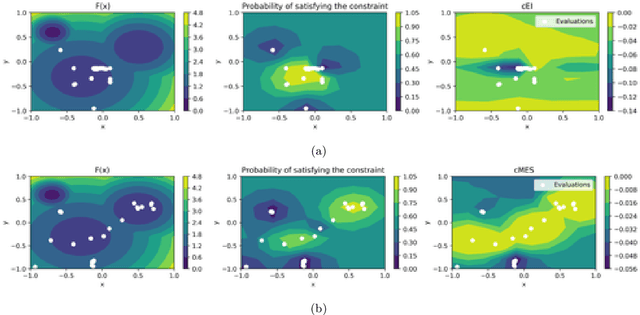
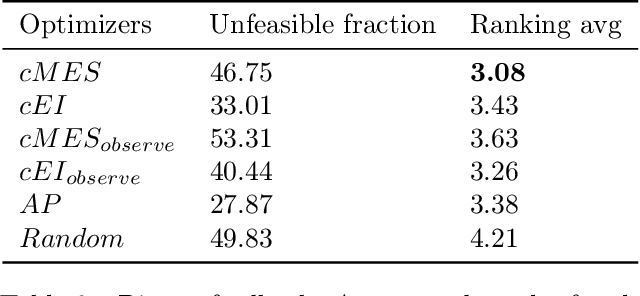
Bayesian optimization (BO) is a model-based approach to sequentially optimize expensive black-box functions, such as the validation error of a deep neural network with respect to its hyperparameters. In many real-world scenarios, the optimization is further subject to a priori unknown constraints. For example, training a deep network configuration may fail with an out-of-memory error when the model is too large. In this work, we focus on a general formulation of Gaussian process-based BO with continuous or binary constraints. We propose constrained Max-value Entropy Search (cMES), a novel information theoretic-based acquisition function implementing this formulation. We also revisit the validity of the factorized approximation adopted for rapid computation of the MES acquisition function, showing empirically that this leads to inaccurate results. On an extensive set of real-world constrained hyperparameter optimization problems we show that cMES compares favourably to prior work, while being simpler to implement and faster than other constrained extensions of Entropy Search.
Learning search spaces for Bayesian optimization: Another view of hyperparameter transfer learning
Sep 27, 2019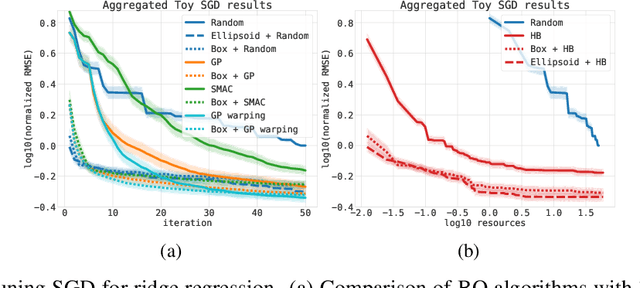
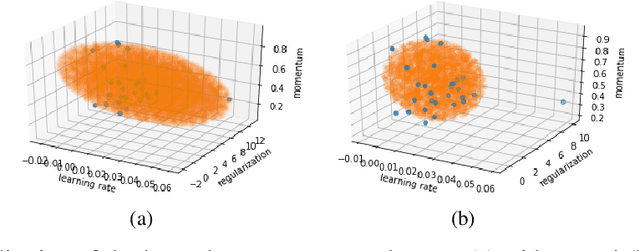
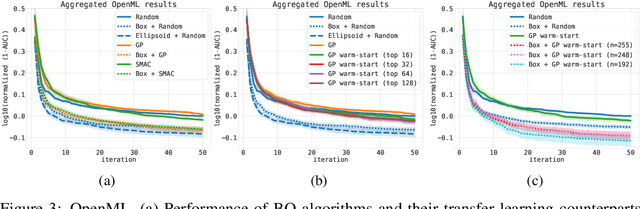
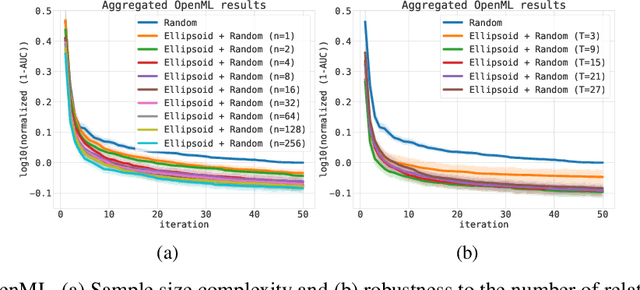
Bayesian optimization (BO) is a successful methodology to optimize black-box functions that are expensive to evaluate. While traditional methods optimize each black-box function in isolation, there has been recent interest in speeding up BO by transferring knowledge across multiple related black-box functions. In this work, we introduce a method to automatically design the BO search space by relying on evaluations of previous black-box functions. We depart from the common practice of defining a set of arbitrary search ranges a priori by considering search space geometries that are learned from historical data. This simple, yet effective strategy can be used to endow many existing BO methods with transfer learning properties. Despite its simplicity, we show that our approach considerably boosts BO by reducing the size of the search space, thus accelerating the optimization of a variety of black-box optimization problems. In particular, the proposed approach combined with random search results in a parameter-free, easy-to-implement, robust hyperparameter optimization strategy. We hope it will constitute a natural baseline for further research attempting to warm-start BO.