 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Hypothesis Generation for 6D Object Pose Estimation
Jan 02, 2017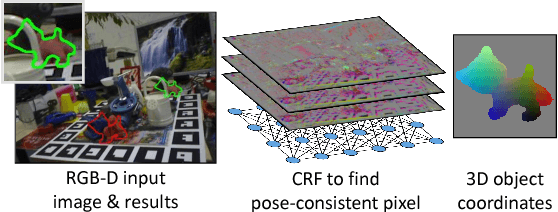
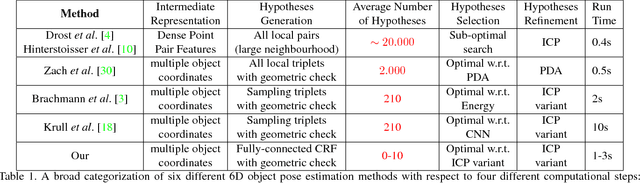
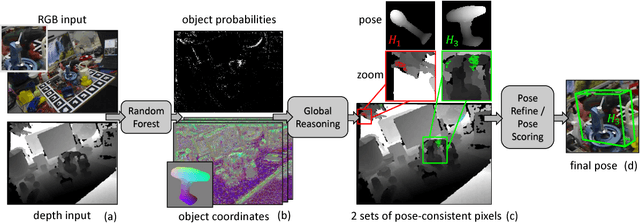
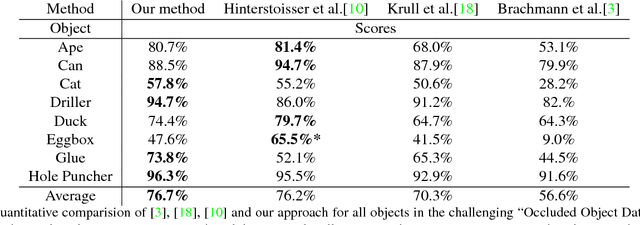
This paper addresses the task of estimating the 6D pose of a known 3D object from a single RGB-D image. Most modern approaches solve this task in three steps: i) Compute local features; ii) Generate a pool of pose-hypotheses; iii) Select and refine a pose from the pool. This work focuses on the second step. While all existing approaches generate the hypotheses pool via local reasoning, e.g. RANSAC or Hough-voting, we are the first to show that global reasoning is beneficial at this stage. In particular, we formulate a novel fully-connected Conditional Random Field (CRF) that outputs a very small number of pose-hypotheses. Despite the potential functions of the CRF being non-Gaussian, we give a new and efficient two-step optimization procedure, with some guarantees for optimality. We utilize our global hypotheses generation procedure to produce results that exceed state-of-the-art for the challenging "Occluded Object Dataset".
Detecting Unexpected Obstacles for Self-Driving Cars: Fusing Deep Learning and Geometric Modeling
Dec 20, 2016
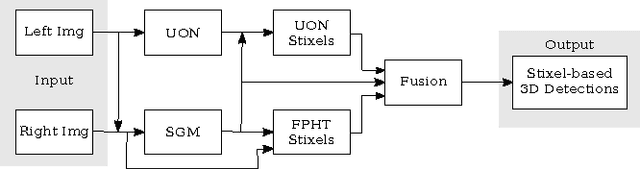

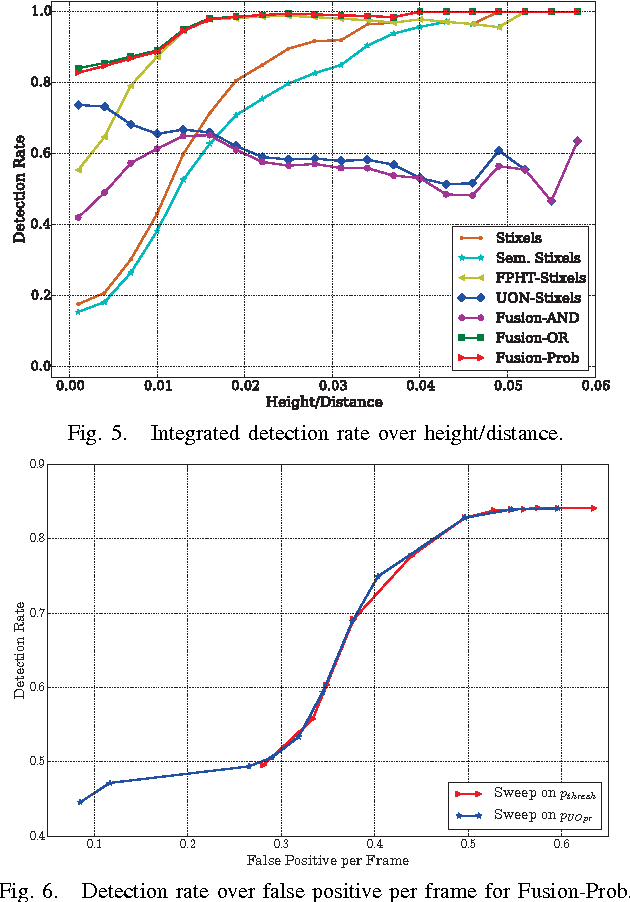
The detection of small road hazards, such as lost cargo, is a vital capability for self-driving cars. We tackle this challenging and rarely addressed problem with a vision system that leverages appearance, contextual as well as geometric cues. To utilize the appearance and contextual cues, we propose a new deep learning-based obstacle detection framework. Here a variant of a fully convolutional network is used to predict a pixel-wise semantic labeling of (i) free-space, (ii) on-road unexpected obstacles, and (iii) background. The geometric cues are exploited using a state-of-the-art detection approach that predicts obstacles from stereo input images via model-based statistical hypothesis tests. We present a principled Bayesian framework to fuse the semantic and stereo-based detection results. The mid-level Stixel representation is used to describe obstacles in a flexible, compact and robust manner. We evaluate our new obstacle detection system on the Lost and Found dataset, which includes very challenging scenes with obstacles of only 5 cm height. Overall, we report a major improvement over the state-of-the-art, with relative performance gains of up to 50%. In particular, we achieve a detection rate of over 90% for distances of up to 50 m. Our system operates at 22 Hz on our self-driving platform.
Implicit Modeling -- A Generalization of Discriminative and Generative Approaches
Dec 05, 2016
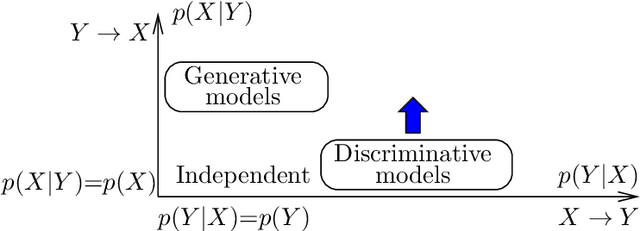
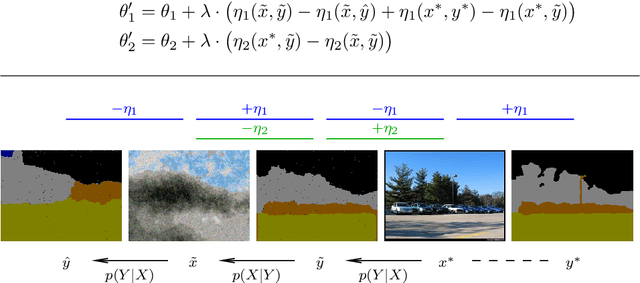
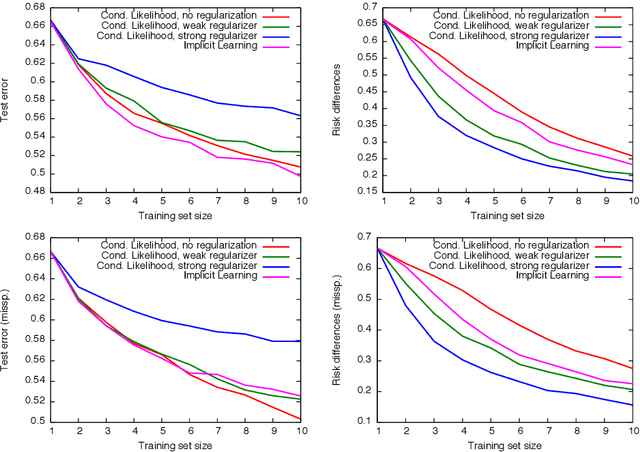
We propose a new modeling approach that is a generalization of generative and discriminative models. The core idea is to use an implicit parameterization of a joint probability distribution by specifying only the conditional distributions. The proposed scheme combines the advantages of both worlds -- it can use powerful complex discriminative models as its parts, having at the same time better generalization capabilities. We thoroughly evaluate the proposed method for a simple classification task with artificial data and illustrate its advantages for real-word scenarios on a semantic image segmentation problem.
InstanceCut: from Edges to Instances with MultiCut
Nov 24, 2016



This work addresses the task of instance-aware semantic segmentation. Our key motivation is to design a simple method with a new modelling-paradigm, which therefore has a different trade-off between advantages and disadvantages compared to known approaches. Our approach, we term InstanceCut, represents the problem by two output modalities: (i) an instance-agnostic semantic segmentation and (ii) all instance-boundaries. The former is computed from a standard convolutional neural network for semantic segmentation, and the latter is derived from a new instance-aware edge detection model. To reason globally about the optimal partitioning of an image into instances, we combine these two modalities into a novel MultiCut formulation. We evaluate our approach on the challenging CityScapes dataset. Despite the conceptual simplicity of our approach, we achieve the best result among all published methods, and perform particularly well for rare object classes.
Can Ground Truth Label Propagation from Video help Semantic Segmentation?
Oct 03, 2016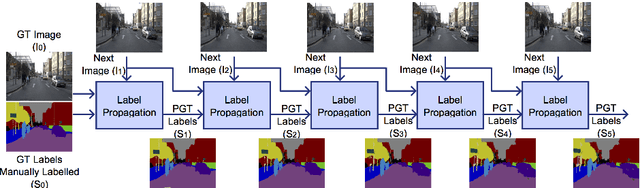
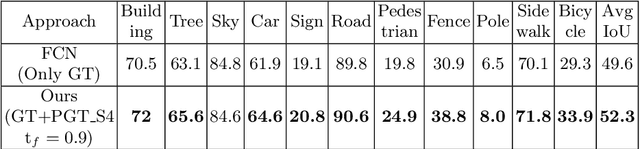

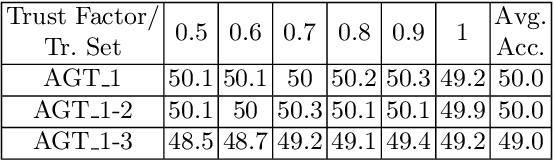
For state-of-the-art semantic segmentation task, training convolutional neural networks (CNNs) requires dense pixelwise ground truth (GT) labeling, which is expensive and involves extensive human effort. In this work, we study the possibility of using auxiliary ground truth, so-called \textit{pseudo ground truth} (PGT) to improve the performance. The PGT is obtained by propagating the labels of a GT frame to its subsequent frames in the video using a simple CRF-based, cue integration framework. Our main contribution is to demonstrate the use of noisy PGT along with GT to improve the performance of a CNN. We perform a systematic analysis to find the right kind of PGT that needs to be added along with the GT for training a CNN. In this regard, we explore three aspects of PGT which influence the learning of a CNN: i) the PGT labeling has to be of good quality; ii) the PGT images have to be different compared to the GT images; iii) the PGT has to be trusted differently than GT. We conclude that PGT which is diverse from GT images and has good quality of labeling can indeed help improve the performance of a CNN. Also, when PGT is multiple folds larger than GT, weighing down the trust on PGT helps in improving the accuracy. Finally, We show that using PGT along with GT, the performance of Fully Convolutional Network (FCN) on Camvid data is increased by $2.7\%$ on IoU accuracy. We believe such an approach can be used to train CNNs for semantic video segmentation where sequentially labeled image frames are needed. To this end, we provide recommendations for using PGT strategically for semantic segmentation and hence bypass the need for extensive human efforts in labeling.
Lost and Found: Detecting Small Road Hazards for Self-Driving Vehicles
Sep 15, 2016
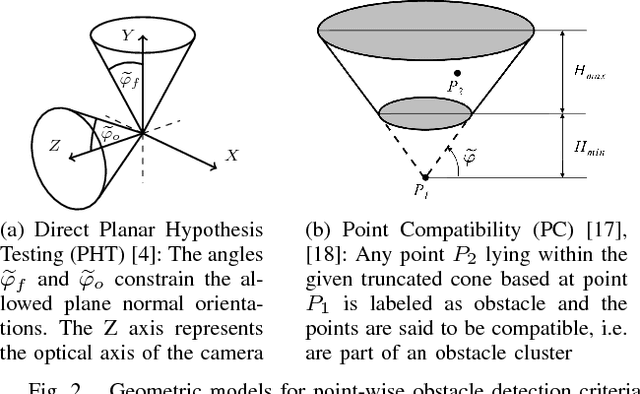

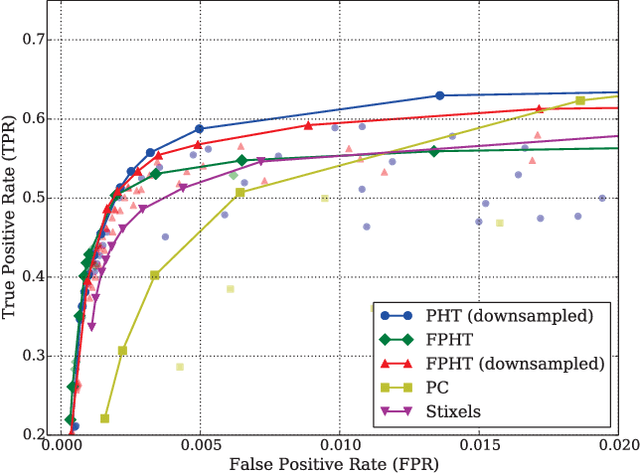
Detecting small obstacles on the road ahead is a critical part of the driving task which has to be mastered by fully autonomous cars. In this paper, we present a method based on stereo vision to reliably detect such obstacles from a moving vehicle. The proposed algorithm performs statistical hypothesis tests in disparity space directly on stereo image data, assessing freespace and obstacle hypotheses on independent local patches. This detection approach does not depend on a global road model and handles both static and moving obstacles. For evaluation, we employ a novel lost-cargo image sequence dataset comprising more than two thousand frames with pixelwise annotations of obstacle and free-space and provide a thorough comparison to several stereo-based baseline methods. The dataset will be made available to the community to foster further research on this important topic. The proposed approach outperforms all considered baselines in our evaluations on both pixel and object level and runs at frame rates of up to 20 Hz on 2 mega-pixel stereo imagery. Small obstacles down to the height of 5 cm can successfully be detected at 20 m distance at low false positive rates.
Joint Training of Generic CNN-CRF Models with Stochastic Optimization
Sep 14, 2016
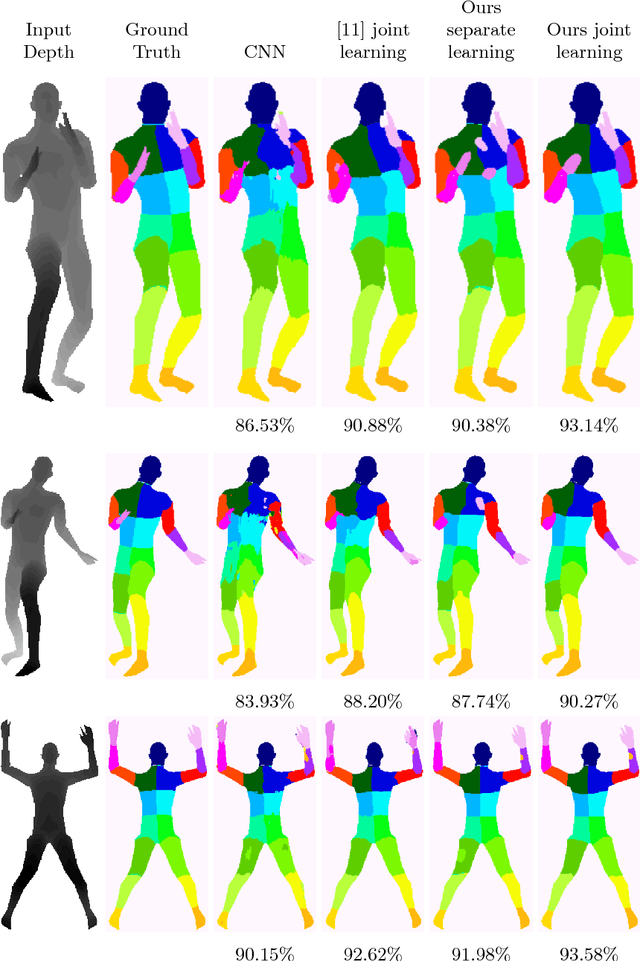
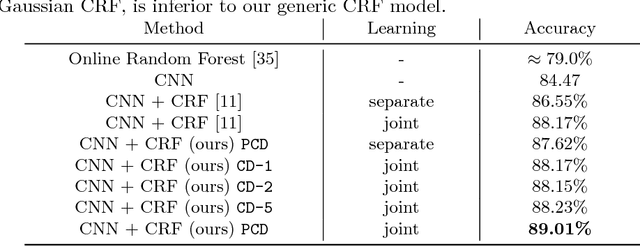
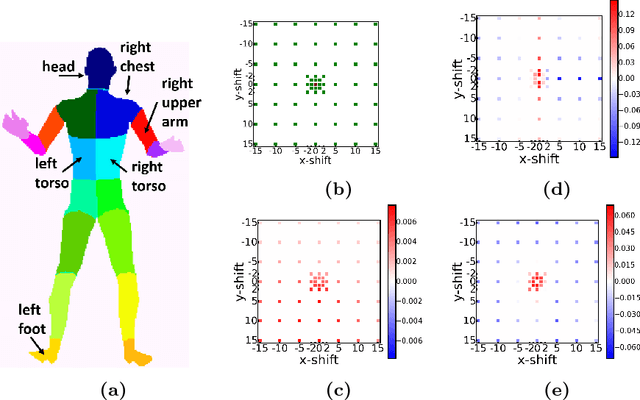
We propose a new CNN-CRF end-to-end learning framework, which is based on joint stochastic optimization with respect to both Convolutional Neural Network (CNN) and Conditional Random Field (CRF) parameters. While stochastic gradient descent is a standard technique for CNN training, it was not used for joint models so far. We show that our learning method is (i) general, i.e. it applies to arbitrary CNN and CRF architectures and potential functions; (ii) scalable, i.e. it has a low memory footprint and straightforwardly parallelizes on GPUs; (iii) easy in implementation. Additionally, the unified CNN-CRF optimization approach simplifies a potential hardware implementation. We empirically evaluate our method on the task of semantic labeling of body parts in depth images and show that it compares favorably to competing techniques.
Stereo Video Deblurring
Jul 28, 2016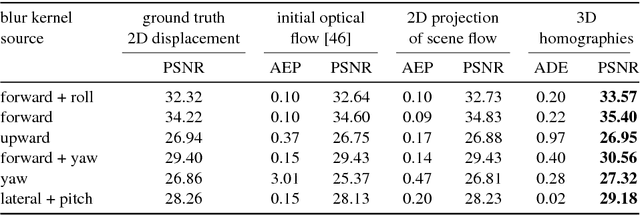
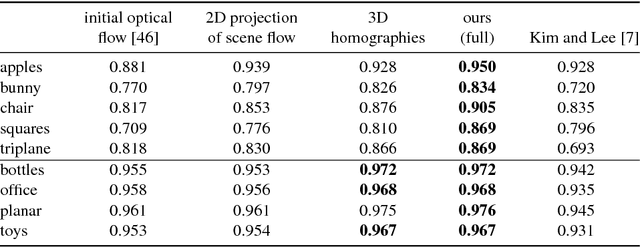
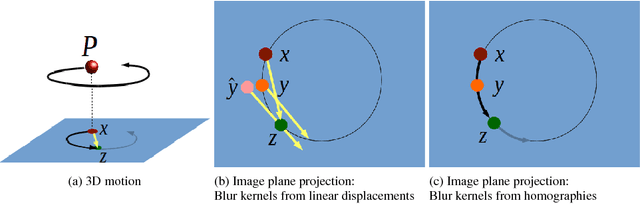

Videos acquired in low-light conditions often exhibit motion blur, which depends on the motion of the objects relative to the camera. This is not only visually unpleasing, but can hamper further processing. With this paper we are the first to show how the availability of stereo video can aid the challenging video deblurring task. We leverage 3D scene flow, which can be estimated robustly even under adverse conditions. We go beyond simply determining the object motion in two ways: First, we show how a piecewise rigid 3D scene flow representation allows to induce accurate blur kernels via local homographies. Second, we exploit the estimated motion boundaries of the 3D scene flow to mitigate ringing artifacts using an iterative weighting scheme. Being aware of 3D object motion, our approach can deal robustly with an arbitrary number of independently moving objects. We demonstrate its benefit over state-of-the-art video deblurring using quantitative and qualitative experiments on rendered scenes and real videos.
Joint M-Best-Diverse Labelings as a Parametric Submodular Minimization
Jun 23, 2016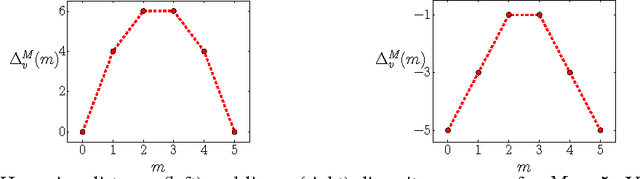
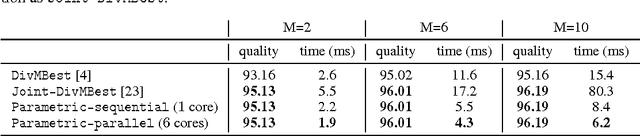
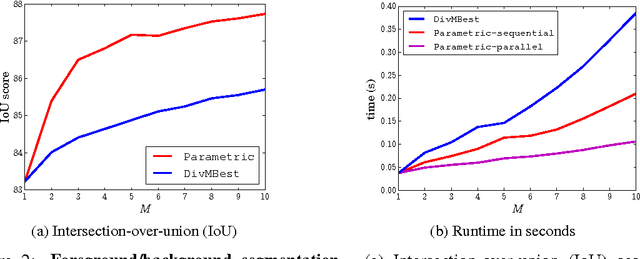
We consider the problem of jointly inferring the M-best diverse labelings for a binary (high-order) submodular energy of a graphical model. Recently, it was shown that this problem can be solved to a global optimum, for many practically interesting diversity measures. It was noted that the labelings are, so-called, nested. This nestedness property also holds for labelings of a class of parametric submodular minimization problems, where different values of the global parameter $\gamma$ give rise to different solutions. The popular example of the parametric submodular minimization is the monotonic parametric max-flow problem, which is also widely used for computing multiple labelings. As the main contribution of this work we establish a close relationship between diversity with submodular energies and the parametric submodular minimization. In particular, the joint M-best diverse labelings can be obtained by running a non-parametric submodular minimization (in the special case - max-flow) solver for M different values of $\gamma$ in parallel, for certain diversity measures. Importantly, the values for $\gamma$ can be computed in a closed form in advance, prior to any optimization. These theoretical results suggest two simple yet efficient algorithms for the joint M-best diverse problem, which outperform competitors in terms of runtime and quality of results. In particular, as we show in the paper, the new methods compute the exact M-best diverse labelings faster than a popular method of Batra et al., which in some sense only obtains approximate solutions.
Convexity Shape Constraints for Image Segmentation
Sep 07, 2015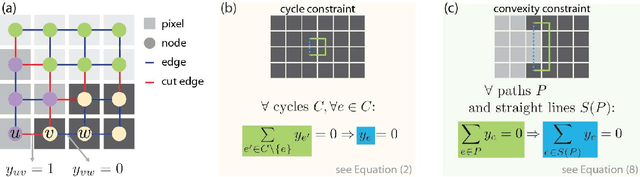

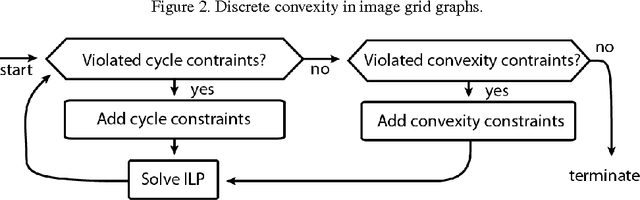

Segmenting an image into multiple components is a central task in computer vision. In many practical scenarios, prior knowledge about plausible components is available. Incorporating such prior knowledge into models and algorithms for image segmentation is highly desirable, yet can be non-trivial. In this work, we introduce a new approach that allows, for the first time, to constrain some or all components of a segmentation to have convex shapes. Specifically, we extend the Minimum Cost Multicut Problem by a class of constraints that enforce convexity. To solve instances of this APX-hard integer linear program to optimality, we separate the proposed constraints in the branch-and-cut loop of a state-of-the-art ILP solver. Results on natural and biological images demonstrate the effectiveness of the approach as well as its advantage over the state-of-the-art heuristic.