 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Hoc Reversal: Are We Selecting Models Prematurely?
Apr 11, 2024



Trained models are often composed with post-hoc transforms such as temperature scaling (TS), ensembling and stochastic weight averaging (SWA) to improve performance, robustness, uncertainty estimation, etc. However, such transforms are typically applied only after the base models have already been finalized by standard means. In this paper, we challenge this practice with an extensive empirical study. In particular, we demonstrate a phenomenon that we call post-hoc reversal, where performance trends are reversed after applying these post-hoc transforms. This phenomenon is especially prominent in high-noise settings. For example, while base models overfit badly early in training, both conventional ensembling and SWA favor base models trained for more epochs. Post-hoc reversal can also suppress the appearance of double descent and mitigate mismatches between test loss and test error seen in base models. Based on our findings, we propose post-hoc selection, a simple technique whereby post-hoc metrics inform model development decisions such as early stopping, checkpointing, and broader hyperparameter choices. Our experimental analyses span real-world vision, language, tabular and graph datasets from domains like satellite imaging, language modeling, census prediction and social network analysis. On an LLM instruction tuning dataset, post-hoc selection results in > 1.5x MMLU improvement compared to naive selection. Code is available at https://github.com/rishabh-ranjan/post-hoc-reversal.
ACORN: Performant and Predicate-Agnostic Search Over Vector Embeddings and Structured Data
Mar 07, 2024



Applications increasingly leverage mixed-modality data, and must jointly search over vector data, such as embedded images, text and video, as well as structured data, such as attributes and keywords. Proposed methods for this hybrid search setting either suffer from poor performance or support a severely restricted set of search predicates (e.g., only small sets of equality predicates), making them impractical for many applications. To address this, we present ACORN, an approach for performant and predicate-agnostic hybrid search. ACORN builds on Hierarchical Navigable Small Worlds (HNSW), a state-of-the-art graph-based approximate nearest neighbor index, and can be implemented efficiently by extending existing HNSW libraries. ACORN introduces the idea of predicate subgraph traversal to emulate a theoretically ideal, but impractical, hybrid search strategy. ACORN's predicate-agnostic construction algorithm is designed to enable this effective search strategy, while supporting a wide array of predicate sets and query semantics. We systematically evaluate ACORN on both prior benchmark datasets, with simple, low-cardinality predicate sets, and complex multi-modal datasets not supported by prior methods. We show that ACORN achieves state-of-the-art performance on all datasets, outperforming prior methods with 2-1,000x higher throughput at a fixed recall.
Unifying Corroborative and Contributive Attributions in Large Language Models
Nov 20, 2023As businesses, products, and services spring up around large language models, the trustworthiness of these models hinges on the verifiability of their outputs. However, methods for explaining language model outputs largely fall across two distinct fields of study which both use the term "attribution" to refer to entirely separate techniques: citation generation and training data attribution. In many modern applications, such as legal document generation and medical question answering, both types of attributions are important. In this work, we argue for and present a unified framework of large language model attributions. We show how existing methods of different types of attribution fall under the unified framework. We also use the framework to discuss real-world use cases where one or both types of attributions are required. We believe that this unified framework will guide the use case driven development of systems that leverage both types of attribution, as well as the standardization of their evaluation.
Learning to (Learn at Test Time)
Oct 20, 2023



We reformulate the problem of supervised learning as learning to learn with two nested loops (i.e. learning problems). The inner loop learns on each individual instance with self-supervision before final prediction. The outer loop learns the self-supervised task used by the inner loop, such that its final prediction improves. Our inner loop turns out to be equivalent to linear attention when the inner-loop learner is only a linear model, and to self-attention when it is a kernel estimator. For practical comparison with linear or self-attention layers, we replace each of them in a transformer with an inner loop, so our outer loop is equivalent to training the architecture. When each inner-loop learner is a neural network, our approach vastly outperforms transformers with linear attention on ImageNet from 224 x 224 raw pixels in both accuracy and FLOPs, while (regular) transformers cannot run.
Beyond Confidence: Reliable Models Should Also Consider Atypicality
May 29, 2023While most machine learning models can provide confidence in their predictions, confidence is insufficient to understand a prediction's reliability. For instance, the model may have a low confidence prediction if the input is not well-represented in the training dataset or if the input is inherently ambiguous. In this work, we investigate the relationship between how atypical(rare) a sample or a class is and the reliability of a model's predictions. We first demonstrate that atypicality is strongly related to miscalibration and accuracy. In particular, we empirically show that predictions for atypical inputs or atypical classes are more overconfident and have lower accuracy. Using these insights, we show incorporating atypicality improves uncertainty quantification and model performance for discriminative neural networks and large language models. In a case study, we show that using atypicality improves the performance of a skin lesion classifier across different skin tone groups without having access to the group attributes. Overall, we propose that models should use not only confidence but also atypicality to improve uncertainty quantification and performance. Our results demonstrate that simple post-hoc atypicality estimators can provide significant value.
AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback
May 22, 2023



Large language models (LLMs) such as ChatGPT have seen widespread adoption due to their ability to follow user instructions well. Developing these LLMs involves a complex yet poorly understood workflow requiring training with human feedback. Replicating and understanding this instruction-following process faces three major challenges: the high cost of data collection, the lack of trustworthy evaluation, and the absence of reference method implementations. We address these challenges with AlpacaFarm, a simulator that enables research and development for learning from feedback at a low cost. First, we design LLM prompts to simulate human feedback that are 45x cheaper than crowdworkers and display high agreement with humans. Second, we propose an automatic evaluation and validate it against human instructions obtained on real-world interactions. Third, we contribute reference implementations for several methods (PPO, best-of-n, expert iteration, and more) that learn from pairwise feedback. Finally, as an end-to-end validation of AlpacaFarm, we train and evaluate eleven models on 10k pairs of real human feedback and show that rankings of models trained in AlpacaFarm match rankings of models trained on human data. As a demonstration of the research possible in AlpacaFarm, we find that methods that use a reward model can substantially improve over supervised fine-tuning and that our reference PPO implementation leads to a +10% improvement in win-rate against Davinci003. We release all components of AlpacaFarm at https://github.com/tatsu-lab/alpaca_farm.
Exploiting Programmatic Behavior of LLMs: Dual-Use Through Standard Security Attacks
Feb 11, 2023Recent advances in instruction-following large language models (LLMs) have led to dramatic improvements in a range of NLP tasks. Unfortunately, we find that the same improved capabilities amplify the dual-use risks for malicious purposes of these models. Dual-use is difficult to prevent as instruction-following capabilities now enable standard attacks from computer security. The capabilities of these instruction-following LLMs provide strong economic incentives for dual-use by malicious actors. In particular, we show that instruction-following LLMs can produce targeted malicious content, including hate speech and scams, bypassing in-the-wild defenses implemented by LLM API vendors. Our analysis shows that this content can be generated economically and at cost likely lower than with human effort alone. Together, our findings suggest that LLMs will increasingly attract more sophisticated adversaries and attacks, and addressing these attacks may require new approaches to mitigations.
Learning Neural Network Subspaces
Feb 20, 2021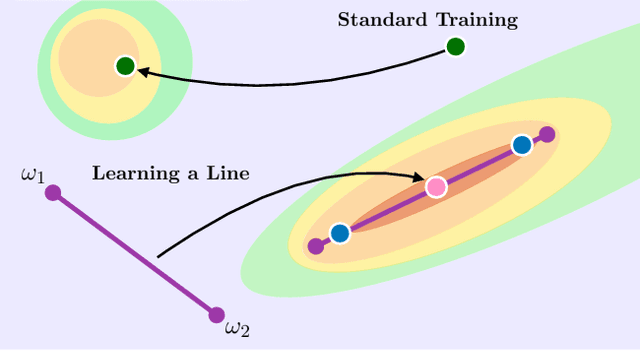


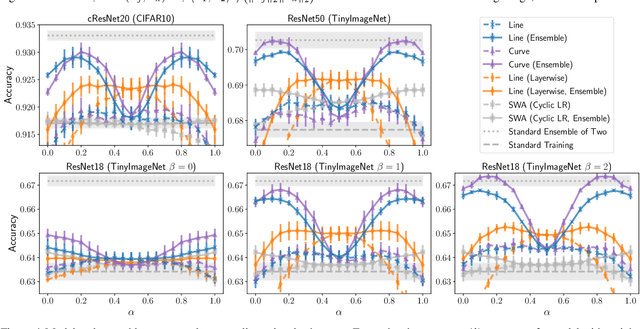
Recent observations have advanced our understanding of the neural network optimization landscape, revealing the existence of (1) paths of high accuracy containing diverse solutions and (2) wider minima offering improved performance. Previous methods observing diverse paths require multiple training runs. In contrast we aim to leverage both property (1) and (2) with a single method and in a single training run. With a similar computational cost as training one model, we learn lines, curves, and simplexes of high-accuracy neural networks. These neural network subspaces contain diverse solutions that can be ensembled, approaching the ensemble performance of independently trained networks without the training cost. Moreover, using the subspace midpoint boosts accuracy, calibration, and robustness to label noise, outperforming Stochastic Weight Averaging.
AdaScale SGD: A User-Friendly Algorithm for Distributed Training
Jul 09, 2020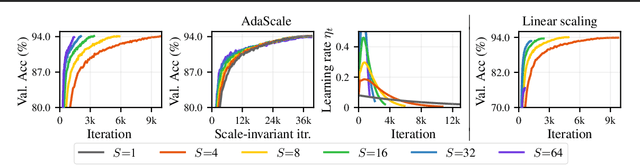

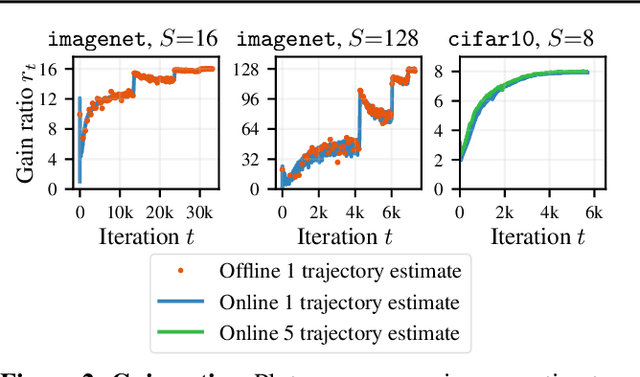
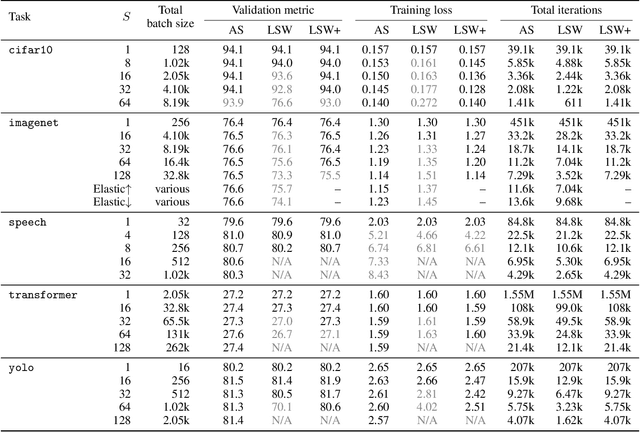
When using large-batch training to speed up stochastic gradient descent, learning rates must adapt to new batch sizes in order to maximize speed-ups and preserve model quality. Re-tuning learning rates is resource intensive, while fixed scaling rules often degrade model quality. We propose AdaScale SGD, an algorithm that reliably adapts learning rates to large-batch training. By continually adapting to the gradient's variance, AdaScale automatically achieves speed-ups for a wide range of batch sizes. We formally describe this quality with AdaScale's convergence bound, which maintains final objective values, even as batch sizes grow large and the number of iterations decreases. In empirical comparisons, AdaScale trains well beyond the batch size limits of popular "linear learning rate scaling" rules. This includes large-batch training with no model degradation for machine translation, image classification, object detection, and speech recognition tasks. AdaScale's qualitative behavior is similar to that of "warm-up" heuristics, but unlike warm-up, this behavior emerges naturally from a principled mechanism. The algorithm introduces negligible computational overhead and no new hyperparameters, making AdaScale an attractive choice for large-scale training in practice.
Set Distribution Networks: a Generative Model for Sets of Images
Jun 18, 2020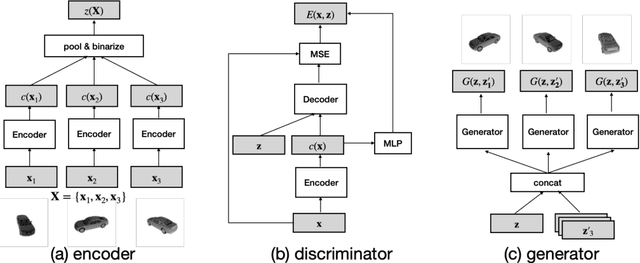
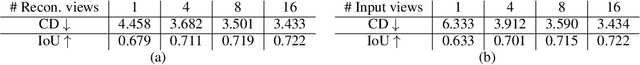


Images with shared characteristics naturally form sets. For example, in a face verification benchmark, images of the same identity form sets. For generative models, the standard way of dealing with sets is to represent each as a one hot vector, and learn a conditional generative model $p(\mathbf{x}|\mathbf{y})$. This representation assumes that the number of sets is limited and known, such that the distribution over sets reduces to a simple multinomial distribution. In contrast, we study a more generic problem where the number of sets is large and unknown. We introduce Set Distribution Networks (SDNs), a novel framework that learns to autoencode and freely generate sets. We achieve this by jointly learning a set encoder, set discriminator, set generator, and set prior. We show that SDNs are able to reconstruct image sets that preserve salient attributes of the inputs in our benchmark datasets, and are also able to generate novel objects/identities. We examine the sets generated by SDN with a pre-trained 3D reconstruction network and a face verification network, respectively, as a novel way to evaluate the quality of generated sets of images.