 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSin3DM: Learning a Diffusion Model from a Single 3D Textured Shape
May 24, 2023



Synthesizing novel 3D models that resemble the input example has long been pursued by researchers and artists in computer graphics. In this paper, we present Sin3DM, a diffusion model that learns the internal patch distribution from a single 3D textured shape and generates high-quality variations with fine geometry and texture details. Training a diffusion model directly in 3D would induce large memory and computational cost. Therefore, we first compress the input into a lower-dimensional latent space and then train a diffusion model on it. Specifically, we encode the input 3D textured shape into triplane feature maps that represent the signed distance and texture fields of the input. The denoising network of our diffusion model has a limited receptive field to avoid overfitting, and uses triplane-aware 2D convolution blocks to improve the result quality. Aside from randomly generating new samples, our model also facilitates applications such as retargeting, outpainting and local editing. Through extensive qualitative and quantitative evaluation, we show that our model can generate 3D shapes of various types with better quality than prior methods.
Tracking through Containers and Occluders in the Wild
May 04, 2023Tracking objects with persistence in cluttered and dynamic environments remains a difficult challenge for computer vision systems. In this paper, we introduce $\textbf{TCOW}$, a new benchmark and model for visual tracking through heavy occlusion and containment. We set up a task where the goal is to, given a video sequence, segment both the projected extent of the target object, as well as the surrounding container or occluder whenever one exists. To study this task, we create a mixture of synthetic and annotated real datasets to support both supervised learning and structured evaluation of model performance under various forms of task variation, such as moving or nested containment. We evaluate two recent transformer-based video models and find that while they can be surprisingly capable of tracking targets under certain settings of task variation, there remains a considerable performance gap before we can claim a tracking model to have acquired a true notion of object permanence.
Humans as Light Bulbs: 3D Human Reconstruction from Thermal Reflection
May 02, 2023The relatively hot temperature of the human body causes people to turn into long-wave infrared light sources. Since this emitted light has a larger wavelength than visible light, many surfaces in typical scenes act as infrared mirrors with strong specular reflections. We exploit the thermal reflections of a person onto objects in order to locate their position and reconstruct their pose, even if they are not visible to a normal camera. We propose an analysis-by-synthesis framework that jointly models the objects, people, and their thermal reflections, which allows us to combine generative models with differentiable rendering of reflections. Quantitative and qualitative experiments show our approach works in highly challenging cases, such as with curved mirrors or when the person is completely unseen by a normal camera.
SURFSUP: Learning Fluid Simulation for Novel Surfaces
Apr 13, 2023



Modeling the mechanics of fluid in complex scenes is vital to applications in design, graphics, and robotics. Learning-based methods provide fast and differentiable fluid simulators, however most prior work is unable to accurately model how fluids interact with genuinely novel surfaces not seen during training. We introduce SURFSUP, a framework that represents objects implicitly using signed distance functions (SDFs), rather than an explicit representation of meshes or particles. This continuous representation of geometry enables more accurate simulation of fluid-object interactions over long time periods while simultaneously making computation more efficient. Moreover, SURFSUP trained on simple shape primitives generalizes considerably out-of-distribution, even to complex real-world scenes and objects. Finally, we show we can invert our model to design simple objects to manipulate fluid flow.
Zero-1-to-3: Zero-shot One Image to 3D Object
Mar 20, 2023



We introduce Zero-1-to-3, a framework for changing the camera viewpoint of an object given just a single RGB image. To perform novel view synthesis in this under-constrained setting, we capitalize on the geometric priors that large-scale diffusion models learn about natural images. Our conditional diffusion model uses a synthetic dataset to learn controls of the relative camera viewpoint, which allow new images to be generated of the same object under a specified camera transformation. Even though it is trained on a synthetic dataset, our model retains a strong zero-shot generalization ability to out-of-distribution datasets as well as in-the-wild images, including impressionist paintings. Our viewpoint-conditioned diffusion approach can further be used for the task of 3D reconstruction from a single image. Qualitative and quantitative experiments show that our method significantly outperforms state-of-the-art single-view 3D reconstruction and novel view synthesis models by leveraging Internet-scale pre-training.
ViperGPT: Visual Inference via Python Execution for Reasoning
Mar 14, 2023



Answering visual queries is a complex task that requires both visual processing and reasoning. End-to-end models, the dominant approach for this task, do not explicitly differentiate between the two, limiting interpretability and generalization. Learning modular programs presents a promising alternative, but has proven challenging due to the difficulty of learning both the programs and modules simultaneously. We introduce ViperGPT, a framework that leverages code-generation models to compose vision-and-language models into subroutines to produce a result for any query. ViperGPT utilizes a provided API to access the available modules, and composes them by generating Python code that is later executed. This simple approach requires no further training, and achieves state-of-the-art results across various complex visual tasks.
Affective Faces for Goal-Driven Dyadic Communication
Jan 26, 2023



We introduce a video framework for modeling the association between verbal and non-verbal communication during dyadic conversation. Given the input speech of a speaker, our approach retrieves a video of a listener, who has facial expressions that would be socially appropriate given the context. Our approach further allows the listener to be conditioned on their own goals, personalities, or backgrounds. Our approach models conversations through a composition of large language models and vision-language models, creating internal representations that are interpretable and controllable. To study multimodal communication, we propose a new video dataset of unscripted conversations covering diverse topics and demographics. Experiments and visualizations show our approach is able to output listeners that are significantly more socially appropriate than baselines. However, many challenges remain, and we release our dataset publicly to spur further progress. See our website for video results, data, and code: https://realtalk.cs.columbia.edu.
Understanding Zero-Shot Adversarial Robustness for Large-Scale Models
Dec 14, 2022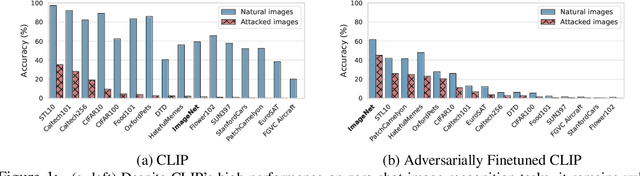
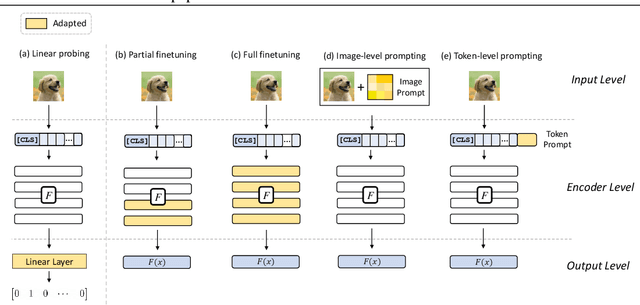
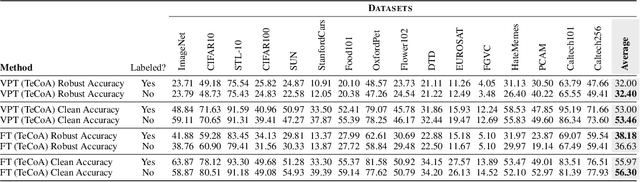
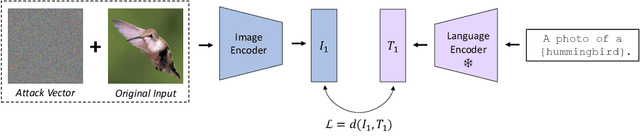
Pretrained large-scale vision-language models like CLIP have exhibited strong generalization over unseen tasks. Yet imperceptible adversarial perturbations can significantly reduce CLIP's performance on new tasks. In this work, we identify and explore the problem of \emph{adapting large-scale models for zero-shot adversarial robustness}. We first identify two key factors during model adaption -- training losses and adaptation methods -- that affect the model's zero-shot adversarial robustness. We then propose a text-guided contrastive adversarial training loss, which aligns the text embeddings and the adversarial visual features with contrastive learning on a small set of training data. We apply this training loss to two adaption methods, model finetuning and visual prompt tuning. We find that visual prompt tuning is more effective in the absence of texts, while finetuning wins in the existence of text guidance. Overall, our approach significantly improves the zero-shot adversarial robustness over CLIP, seeing an average improvement of over 31 points over ImageNet and 15 zero-shot datasets. We hope this work can shed light on understanding the zero-shot adversarial robustness of large-scale models.
Adversarially Robust Video Perception by Seeing Motion
Dec 13, 2022Despite their excellent performance, state-of-the-art computer vision models often fail when they encounter adversarial examples. Video perception models tend to be more fragile under attacks, because the adversary has more places to manipulate in high-dimensional data. In this paper, we find one reason for video models' vulnerability is that they fail to perceive the correct motion under adversarial perturbations. Inspired by the extensive evidence that motion is a key factor for the human visual system, we propose to correct what the model sees by restoring the perceived motion information. Since motion information is an intrinsic structure of the video data, recovering motion signals can be done at inference time without any human annotation, which allows the model to adapt to unforeseen, worst-case inputs. Visualizations and empirical experiments on UCF-101 and HMDB-51 datasets show that restoring motion information in deep vision models improves adversarial robustness. Even under adaptive attacks where the adversary knows our defense, our algorithm is still effective. Our work provides new insight into robust video perception algorithms by using intrinsic structures from the data. Our webpage is available at https://motion4robust.cs.columbia.edu.
Robust Perception through Equivariance
Dec 12, 2022Deep networks for computer vision are not reliable when they encounter adversarial examples. In this paper, we introduce a framework that uses the dense intrinsic constraints in natural images to robustify inference. By introducing constraints at inference time, we can shift the burden of robustness from training to the inference algorithm, thereby allowing the model to adjust dynamically to each individual image's unique and potentially novel characteristics at inference time. Among different constraints, we find that equivariance-based constraints are most effective, because they allow dense constraints in the feature space without overly constraining the representation at a fine-grained level. Our theoretical results validate the importance of having such dense constraints at inference time. Our empirical experiments show that restoring feature equivariance at inference time defends against worst-case adversarial perturbations. The method obtains improved adversarial robustness on four datasets (ImageNet, Cityscapes, PASCAL VOC, and MS-COCO) on image recognition, semantic segmentation, and instance segmentation tasks. Project page is available at equi4robust.cs.columbia.edu.