 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatically Summarizing Evidence from Clinical Trials: A Prototype Highlighting Current Challenges
Mar 07, 2023



We present TrialsSummarizer, a system that aims to automatically summarize evidence presented in the set of randomized controlled trials most relevant to a given query. Building on prior work, the system retrieves trial publications matching a query specifying a combination of condition, intervention(s), and outcome(s), and ranks these according to sample size and estimated study quality. The top-k such studies are passed through a neural multi-document summarization system, yielding a synopsis of these trials. We consider two architectures: A standard sequence-to-sequence model based on BART and a multi-headed architecture intended to provide greater transparency to end-users. Both models produce fluent and relevant summaries of evidence retrieved for queries, but their tendency to introduce unsupported statements render them inappropriate for use in this domain at present. The proposed architecture may help users verify outputs allowing users to trace generated tokens back to inputs.
CHiLL: Zero-shot Custom Interpretable Feature Extraction from Clinical Notes with Large Language Models
Feb 23, 2023



Large Language Models (LLMs) have yielded fast and dramatic progress in NLP, and now offer strong few- and zero-shot capabilities on new tasks, reducing the need for annotation. This is especially exciting for the medical domain, in which supervision is often scant and expensive. At the same time, model predictions are rarely so accurate that they can be trusted blindly. Clinicians therefore tend to favor "interpretable" classifiers over opaque LLMs. For example, risk prediction tools are often linear models defined over manually crafted predictors that must be laboriously extracted from EHRs. We propose CHiLL (Crafting High-Level Latents), which uses LLMs to permit natural language specification of high-level features for linear models via zero-shot feature extraction using expert-composed queries. This approach has the promise to empower physicians to use their domain expertise to craft features which are clinically meaningful for a downstream task of interest, without having to manually extract these from raw EHR (as often done now). We are motivated by a real-world risk prediction task, but as a reproducible proxy, we use MIMIC-III and MIMIC-CXR data and standard predictive tasks (e.g., 30-day readmission) to evaluate our approach. We find that linear models using automatically extracted features are comparably performant to models using reference features, and provide greater interpretability than linear models using "Bag-of-Words" features. We verify that learned feature weights align well with clinical expectations.
NapSS: Paragraph-level Medical Text Simplification via Narrative Prompting and Sentence-matching Summarization
Feb 11, 2023Accessing medical literature is difficult for laypeople as the content is written for specialists and contains medical jargon. Automated text simplification methods offer a potential means to address this issue. In this work, we propose a summarize-then-simplify two-stage strategy, which we call NapSS, identifying the relevant content to simplify while ensuring that the original narrative flow is preserved. In this approach, we first generate reference summaries via sentence matching between the original and the simplified abstracts. These summaries are then used to train an extractive summarizer, learning the most relevant content to be simplified. Then, to ensure the narrative consistency of the simplified text, we synthesize auxiliary narrative prompts combining key phrases derived from the syntactical analyses of the original text. Our model achieves results significantly better than the seq2seq baseline on an English medical corpus, yielding 3%~4% absolute improvements in terms of lexical similarity, and providing a further 1.1% improvement of SARI score when combined with the baseline. We also highlight shortcomings of existing evaluation methods, and introduce new metrics that take into account both lexical and high-level semantic similarity. A human evaluation conducted on a random sample of the test set further establishes the effectiveness of the proposed approach. Codes and models are released here: https://github.com/LuJunru/NapSS.
How Many and Which Training Points Would Need to be Removed to Flip this Prediction?
Feb 09, 2023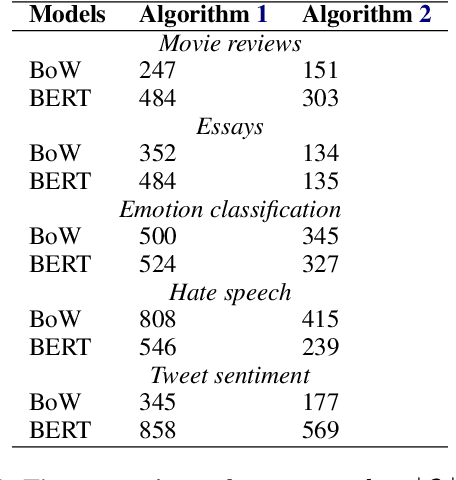



We consider the problem of identifying a minimal subset of training data $\mathcal{S}_t$ such that if the instances comprising $\mathcal{S}_t$ had been removed prior to training, the categorization of a given test point $x_t$ would have been different. Identifying such a set may be of interest for a few reasons. First, the cardinality of $\mathcal{S}_t$ provides a measure of robustness (if $|\mathcal{S}_t|$ is small for $x_t$, we might be less confident in the corresponding prediction), which we show is correlated with but complementary to predicted probabilities. Second, interrogation of $\mathcal{S}_t$ may provide a novel mechanism for contesting a particular model prediction: If one can make the case that the points in $\mathcal{S}_t$ are wrongly labeled or irrelevant, this may argue for overturning the associated prediction. Identifying $\mathcal{S}_t$ via brute-force is intractable. We propose comparatively fast approximation methods to find $\mathcal{S}_t$ based on influence functions, and find that -- for simple convex text classification models -- these approaches can often successfully identify relatively small sets of training examples which, if removed, would flip the prediction.
Do Multi-Document Summarization Models Synthesize?
Jan 31, 2023Multi-document summarization entails producing concise synopses of collections of inputs. For some applications, the synopsis should accurately \emph{synthesize} inputs with respect to a key property or aspect. For example, a synopsis of film reviews all written about a particular movie should reflect the average critic consensus. As a more consequential example, consider narrative summaries that accompany biomedical \emph{systematic reviews} of clinical trial results. These narratives should fairly summarize the potentially conflicting results from individual trials. In this paper we ask: To what extent do modern multi-document summarization models implicitly perform this type of synthesis? To assess this we perform a suite of experiments that probe the degree to which conditional generation models trained for summarization using standard methods yield outputs that appropriately synthesize inputs. We find that existing models do partially perform synthesis, but do so imperfectly. In particular, they are over-sensitive to changes in input ordering and under-sensitive to changes in input compositions (e.g., the ratio of positive to negative movie reviews). We propose a simple, general method for improving model synthesis capabilities by generating an explicitly diverse set of candidate outputs, and then selecting from these the string best aligned with the expected aggregate measure for the inputs, or \emph{abstaining} when the model produces no good candidate. This approach improves model synthesis performance. We hope highlighting the need for synthesis (in some summarization settings), motivates further research into multi-document summarization methods and learning objectives that explicitly account for the need to synthesize.
Intermediate Entity-based Sparse Interpretable Representation Learning
Dec 03, 2022



Interpretable entity representations (IERs) are sparse embeddings that are "human-readable" in that dimensions correspond to fine-grained entity types and values are predicted probabilities that a given entity is of the corresponding type. These methods perform well in zero-shot and low supervision settings. Compared to standard dense neural embeddings, such interpretable representations may permit analysis and debugging. However, while fine-tuning sparse, interpretable representations improves accuracy on downstream tasks, it destroys the semantics of the dimensions which were enforced in pre-training. Can we maintain the interpretable semantics afforded by IERs while improving predictive performance on downstream tasks? Toward this end, we propose Intermediate enTity-based Sparse Interpretable Representation Learning (ItsIRL). ItsIRL realizes improved performance over prior IERs on biomedical tasks, while maintaining "interpretability" generally and their ability to support model debugging specifically. The latter is enabled in part by the ability to perform "counterfactual" fine-grained entity type manipulation, which we explore in this work. Finally, we propose a method to construct entity type based class prototypes for revealing global semantic properties of classes learned by our model.
Influence Functions for Sequence Tagging Models
Oct 25, 2022



Many language tasks (e.g., Named Entity Recognition, Part-of-Speech tagging, and Semantic Role Labeling) are naturally framed as sequence tagging problems. However, there has been comparatively little work on interpretability methods for sequence tagging models. In this paper, we extend influence functions - which aim to trace predictions back to the training points that informed them - to sequence tagging tasks. We define the influence of a training instance segment as the effect that perturbing the labels within this segment has on a test segment level prediction. We provide an efficient approximation to compute this, and show that it tracks with the true segment influence, measured empirically. We show the practical utility of segment influence by using the method to identify systematic annotation errors in two named entity recognition corpora. Code to reproduce our results is available at https://github.com/successar/Segment_Influence_Functions.
PHEE: A Dataset for Pharmacovigilance Event Extraction from Text
Oct 22, 2022



The primary goal of drug safety researchers and regulators is to promptly identify adverse drug reactions. Doing so may in turn prevent or reduce the harm to patients and ultimately improve public health. Evaluating and monitoring drug safety (i.e., pharmacovigilance) involves analyzing an ever growing collection of spontaneous reports from health professionals, physicians, and pharmacists, and information voluntarily submitted by patients. In this scenario, facilitating analysis of such reports via automation has the potential to rapidly identify safety signals. Unfortunately, public resources for developing natural language models for this task are scant. We present PHEE, a novel dataset for pharmacovigilance comprising over 5000 annotated events from medical case reports and biomedical literature, making it the largest such public dataset to date. We describe the hierarchical event schema designed to provide coarse and fine-grained information about patients' demographics, treatments and (side) effects. Along with the discussion of the dataset, we present a thorough experimental evaluation of current state-of-the-art approaches for biomedical event extraction, point out their limitations, and highlight open challenges to foster future research in this area.
Self-Repetition in Abstractive Neural Summarizers
Oct 14, 2022
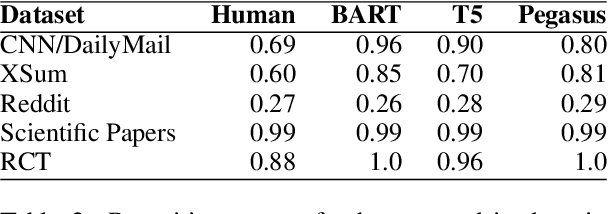
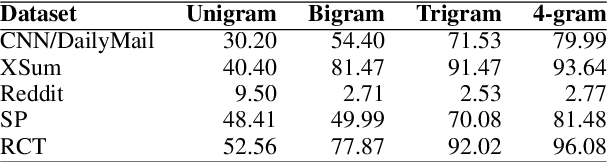

We provide a quantitative and qualitative analysis of self-repetition in the output of neural summarizers. We measure self-repetition as the number of n-grams of length four or longer that appear in multiple outputs of the same system. We analyze the behavior of three popular architectures (BART, T5, and Pegasus), fine-tuned on five datasets. In a regression analysis, we find that the three architectures have different propensities for repeating content across output summaries for inputs, with BART being particularly prone to self-repetition. Fine-tuning on more abstractive data, and on data featuring formulaic language, is associated with a higher rate of self-repetition. In qualitative analysis we find systems produce artefacts such as ads and disclaimers unrelated to the content being summarized, as well as formulaic phrases common in the fine-tuning domain. Our approach to corpus-level analysis of self-repetition may help practitioners clean up training data for summarizers and ultimately support methods for minimizing the amount of self-repetition.
Learning to Ask Like a Physician
Jun 06, 2022
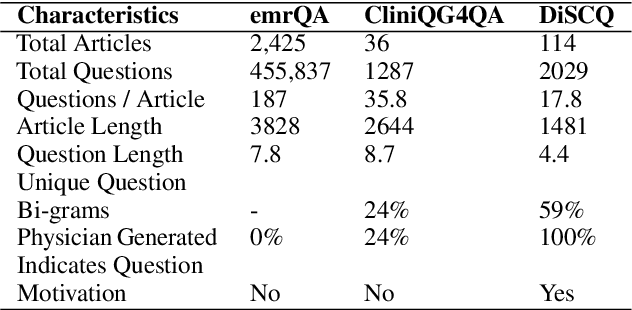

Existing question answering (QA) datasets derived from electronic health records (EHR) are artificially generated and consequently fail to capture realistic physician information needs. We present Discharge Summary Clinical Questions (DiSCQ), a newly curated question dataset composed of 2,000+ questions paired with the snippets of text (triggers) that prompted each question. The questions are generated by medical experts from 100+ MIMIC-III discharge summaries. We analyze this dataset to characterize the types of information sought by medical experts. We also train baseline models for trigger detection and question generation (QG), paired with unsupervised answer retrieval over EHRs. Our baseline model is able to generate high quality questions in over 62% of cases when prompted with human selected triggers. We release this dataset (and all code to reproduce baseline model results) to facilitate further research into realistic clinical QA and QG: https://github.com/elehman16/discq.