 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing unsupervised learning to improve sward content prediction and herbage mass estimation
Apr 20, 2022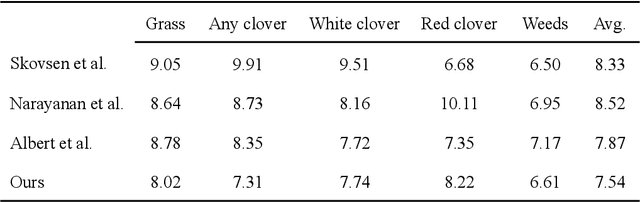
Sward species composition estimation is a tedious one. Herbage must be collected in the field, manually separated into components, dried and weighed to estimate species composition. Deep learning approaches using neural networks have been used in previous work to propose faster and more cost efficient alternatives to this process by estimating the biomass information from a picture of an area of pasture alone. Deep learning approaches have, however, struggled to generalize to distant geographical locations and necessitated further data collection to retrain and perform optimally in different climates. In this work, we enhance the deep learning solution by reducing the need for ground-truthed (GT) images when training the neural network. We demonstrate how unsupervised contrastive learning can be used in the sward composition prediction problem and compare with the state-of-the-art on the publicly available GrassClover dataset collected in Denmark as well as a more recent dataset from Ireland where we tackle herbage mass and height estimation.
Unsupervised domain adaptation and super resolution on drone images for autonomous dry herbage biomass estimation
Apr 18, 2022

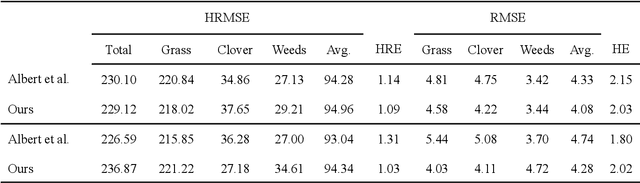
Herbage mass yield and composition estimation is an important tool for dairy farmers to ensure an adequate supply of high quality herbage for grazing and subsequently milk production. By accurately estimating herbage mass and composition, targeted nitrogen fertiliser application strategies can be deployed to improve localised regions in a herbage field, effectively reducing the negative impacts of over-fertilization on biodiversity and the environment. In this context, deep learning algorithms offer a tempting alternative to the usual means of sward composition estimation, which involves the destructive process of cutting a sample from the herbage field and sorting by hand all plant species in the herbage. The process is labour intensive and time consuming and so not utilised by farmers. Deep learning has been successfully applied in this context on images collected by high-resolution cameras on the ground. Moving the deep learning solution to drone imaging, however, has the potential to further improve the herbage mass yield and composition estimation task by extending the ground-level estimation to the large surfaces occupied by fields/paddocks. Drone images come at the cost of lower resolution views of the fields taken from a high altitude and requires further herbage ground-truth collection from the large surfaces covered by drone images. This paper proposes to transfer knowledge learned on ground-level images to raw drone images in an unsupervised manner. To do so, we use unpaired image style translation to enhance the resolution of drone images by a factor of eight and modify them to appear closer to their ground-level counterparts. We then ... ~\url{www.github.com/PaulAlbert31/Clover_SSL}.
A Rationale-Centric Framework for Human-in-the-loop Machine Learning
Mar 24, 2022

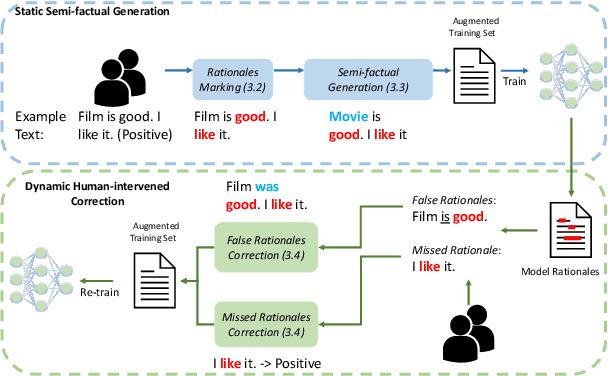

We present a novel rationale-centric framework with human-in-the-loop -- Rationales-centric Double-robustness Learning (RDL) -- to boost model out-of-distribution performance in few-shot learning scenarios. By using static semi-factual generation and dynamic human-intervened correction, RDL exploits rationales (i.e. phrases that cause the prediction), human interventions and semi-factual augmentations to decouple spurious associations and bias models towards generally applicable underlying distributions, which enables fast and accurate generalisation. Experimental results show that RDL leads to significant prediction benefits on both in-distribution and out-of-distribution tests compared to many state-of-the-art benchmarks -- especially for few-shot learning scenarios. We also perform extensive ablation studies to support in-depth analyses of each component in our framework.
Semi-supervised dry herbage mass estimation using automatic data and synthetic images
Oct 26, 2021

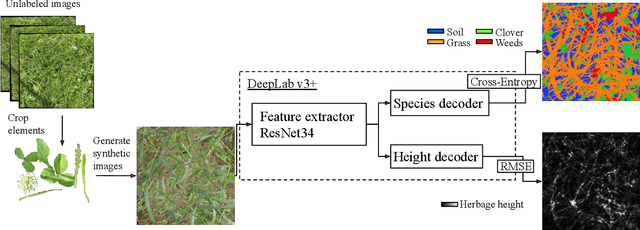

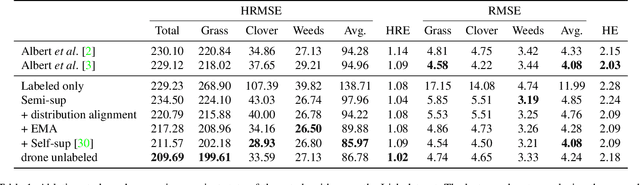
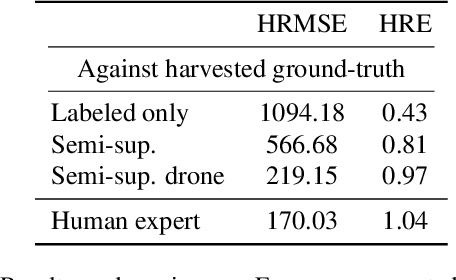
Monitoring species-specific dry herbage biomass is an important aspect of pasture-based milk production systems. Being aware of the herbage biomass in the field enables farmers to manage surpluses and deficits in herbage supply, as well as using targeted nitrogen fertilization when necessary. Deep learning for computer vision is a powerful tool in this context as it can accurately estimate the dry biomass of a herbage parcel using images of the grass canopy taken using a portable device. However, the performance of deep learning comes at the cost of an extensive, and in this case destructive, data gathering process. Since accurate species-specific biomass estimation is labor intensive and destructive for the herbage parcel, we propose in this paper to study low supervision approaches to dry biomass estimation using computer vision. Our contributions include: a synthetic data generation algorithm to generate data for a herbage height aware semantic segmentation task, an automatic process to label data using semantic segmentation maps, and a robust regression network trained to predict dry biomass using approximate biomass labels and a small trusted dataset with gold standard labels. We design our approach on a herbage mass estimation dataset collected in Ireland and also report state-of-the-art results on the publicly released Grass-Clover biomass estimation dataset from Denmark. Our code is available at https://git.io/J0L2a
Random Walk-steered Majority Undersampling
Sep 25, 2021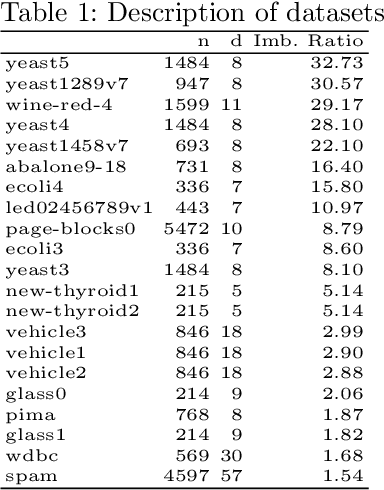
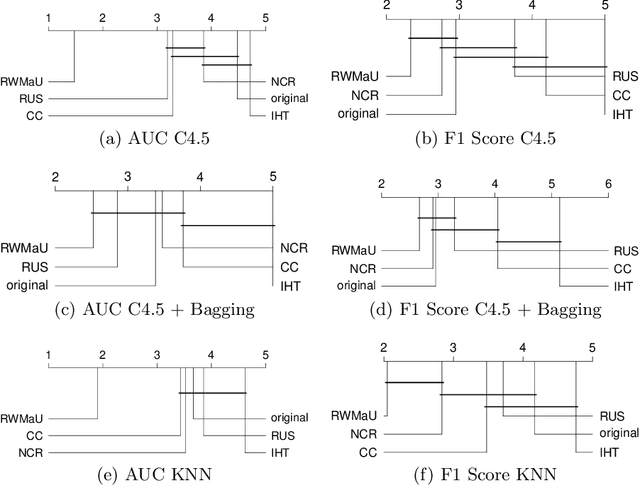
In this work, we propose Random Walk-steered Majority Undersampling (RWMaU), which undersamples the majority points of a class imbalanced dataset, in order to balance the classes. Rather than marking the majority points which belong to the neighborhood of a few minority points, we are interested to perceive the closeness of the majority points to the minority class. Random walk, a powerful tool for perceiving the proximities of connected points in a graph, is used to identify the majority points which lie close to the minority class of a class-imbalanced dataset. The visit frequencies and the order of visits of the majority points in the walks enable us to perceive an overall closeness of the majority points to the minority class. The ones lying close to the minority class are subsequently undersampled. Empirical evaluation on 21 datasets and 3 classifiers demonstrate substantial improvement in performance of RWMaU over the competing methods.
Integrating Unsupervised Clustering and Label-specific Oversampling to Tackle Imbalanced Multi-label Data
Sep 25, 2021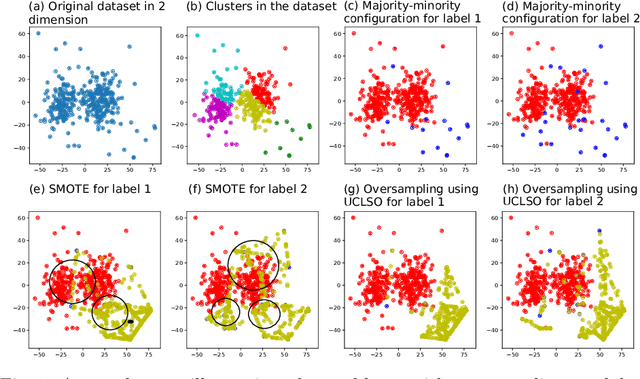
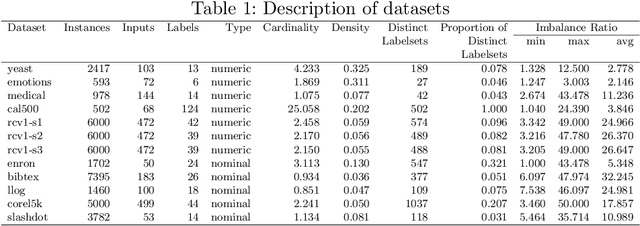
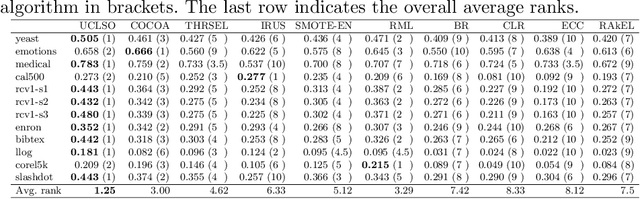
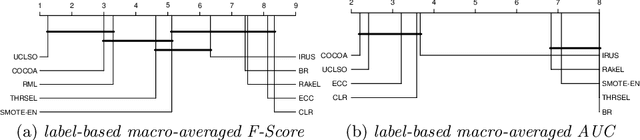
There is often a mixture of very frequent labels and very infrequent labels in multi-label datatsets. This variation in label frequency, a type class imbalance, creates a significant challenge for building efficient multi-label classification algorithms. In this paper, we tackle this problem by proposing a minority class oversampling scheme, UCLSO, which integrates Unsupervised Clustering and Label-Specific data Oversampling. Clustering is performed to find out the key distinct and locally connected regions of a multi-label dataset (irrespective of the label information). Next, for each label, we explore the distributions of minority points in the cluster sets. Only the minority points within a cluster are used to generate the synthetic minority points that are used for oversampling. Even though the cluster set is the same across all labels, the distributions of the synthetic minority points will vary across the labels. The training dataset is augmented with the set of label-specific synthetic minority points, and classifiers are trained to predict the relevance of each label independently. Experiments using 12 multi-label datasets and several multi-label algorithms show that the proposed method performed very well compared to the other competing algorithms.
Pseudo-labelling Enhanced Media Bias Detection
Jul 16, 2021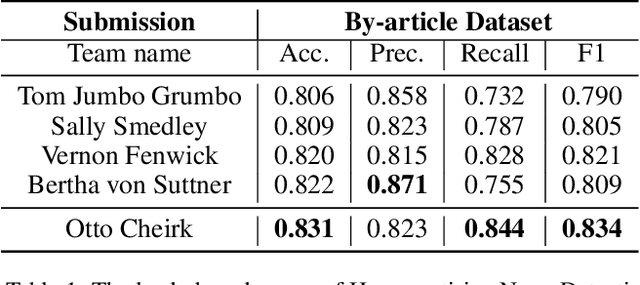
Leveraging unlabelled data through weak or distant supervision is a compelling approach to developing more effective text classification models. This paper proposes a simple but effective data augmentation method, which leverages the idea of pseudo-labelling to select samples from noisy distant supervision annotation datasets. The result shows that the proposed method improves the accuracy of biased news detection models.
On the Importance of Regularisation & Auxiliary Information in OOD Detection
Jul 15, 2021

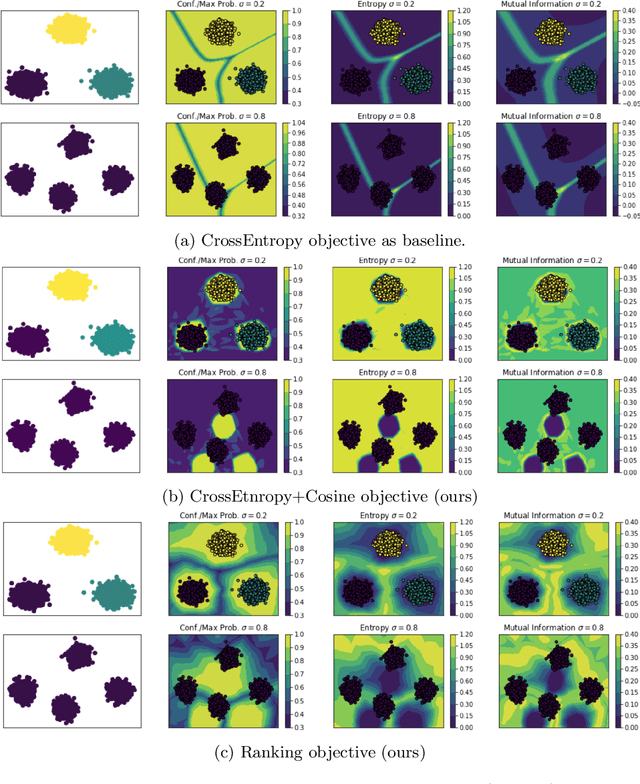
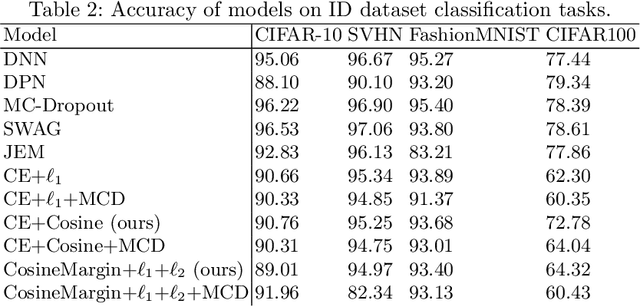
Neural networks are often utilised in critical domain applications (e.g.~self-driving cars, financial markets, and aerospace engineering), even though they exhibit overconfident predictions for ambiguous inputs. This deficiency demonstrates a fundamental flaw indicating that neural networks often overfit on spurious correlations. To address this problem in this work we present two novel objectives that improve the ability of a network to detect out-of-distribution samples and therefore avoid overconfident predictions for ambiguous inputs. We empirically demonstrate that our methods outperform the baseline and perform better than the majority of existing approaches, while performing competitively those that they don't outperform. Additionally, we empirically demonstrate the robustness of our approach against common corruptions and demonstrate the importance of regularisation and auxiliary information in out-of-distribution detection.
A Sentence-level Hierarchical BERT Model for Document Classification with Limited Labelled Data
Jun 12, 2021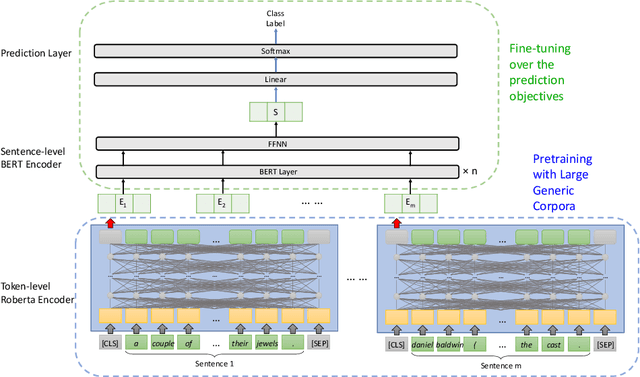
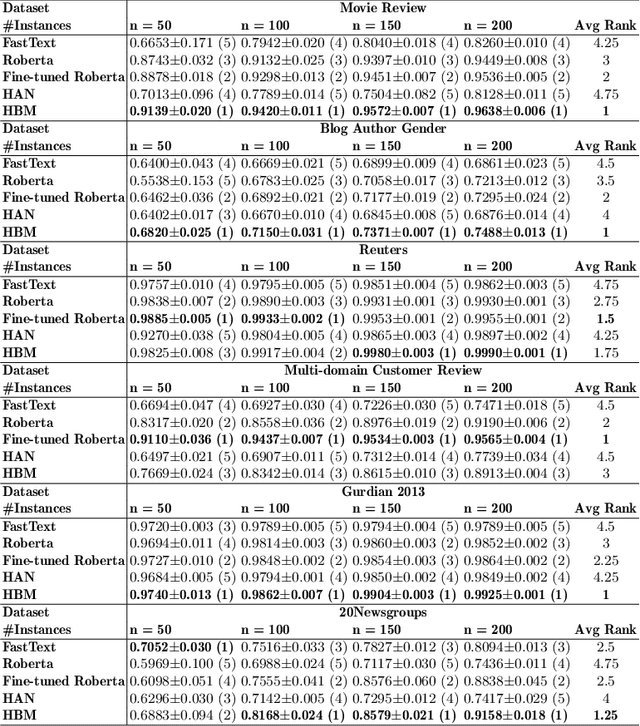
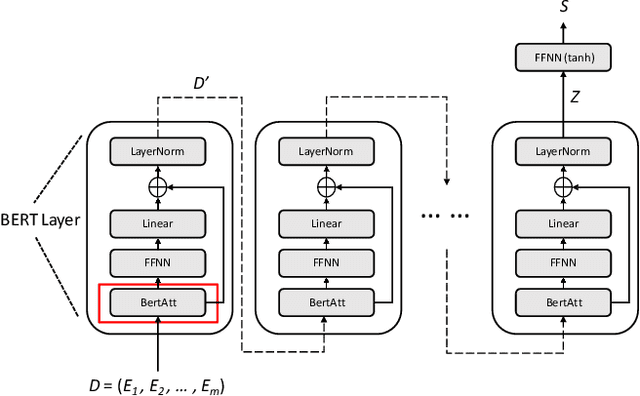

Training deep learning models with limited labelled data is an attractive scenario for many NLP tasks, including document classification. While with the recent emergence of BERT, deep learning language models can achieve reasonably good performance in document classification with few labelled instances, there is a lack of evidence in the utility of applying BERT-like models on long document classification. This work introduces a long-text-specific model -- the Hierarchical BERT Model (HBM) -- that learns sentence-level features of the text and works well in scenarios with limited labelled data. Various evaluation experiments have demonstrated that HBM can achieve higher performance in document classification than the previous state-of-the-art methods with only 50 to 200 labelled instances, especially when documents are long. Also, as an extra benefit of HBM, the salient sentences identified by learned HBM are useful as explanations for labelling documents based on a user study.
The Deep Radial Basis Function Data Descriptor (D-RBFDD) Network: A One-Class Neural Network for Anomaly Detection
Jan 29, 2021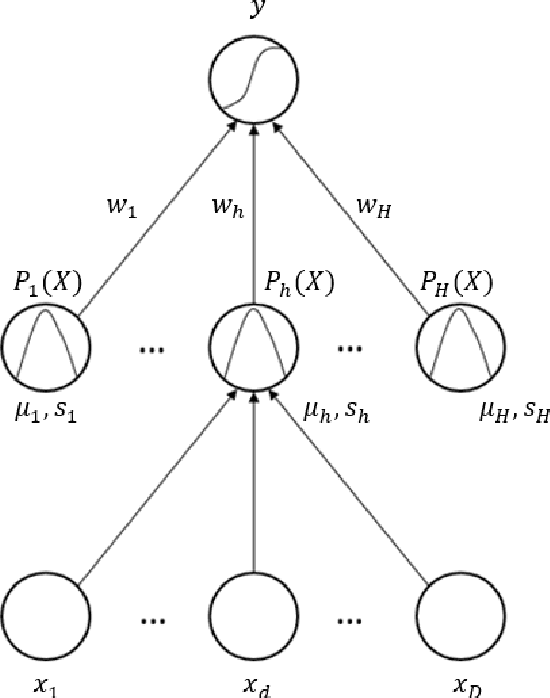
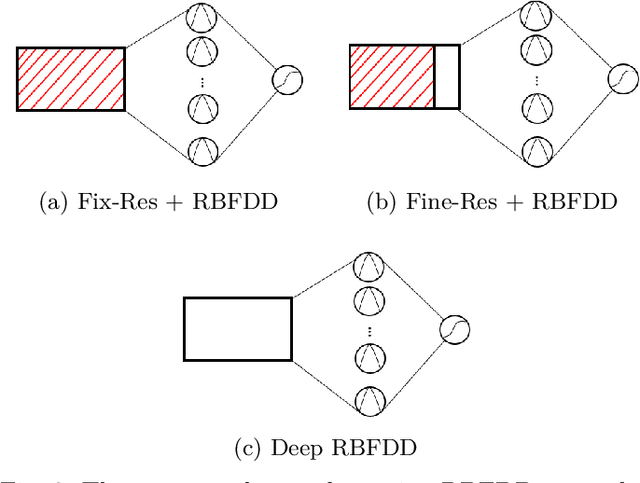
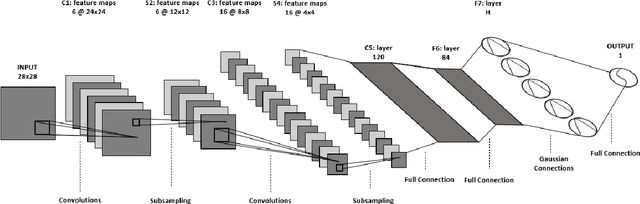
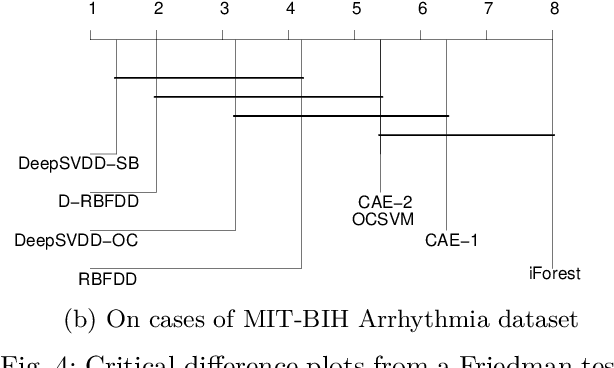
Anomaly detection is a challenging problem in machine learning, and is even more so when dealing with instances that are captured in low-level, raw data representations without a well-behaved set of engineered features. The Radial Basis Function Data Descriptor (RBFDD) network is an effective solution for anomaly detection, however, it is a shallow model that does not deal effectively with raw data representations. This paper investigates approaches to modifying the RBFDD network to transform it into a deep one-class classifier suitable for anomaly detection problems with low-level raw data representations. We show that approaches based on transfer learning are not effective and our results suggest that this is because the latent representations learned by generic classification models are not suitable for anomaly detection. Instead we show that an approach that adds multiple convolutional layers before the RBF layer, to form a Deep Radial Basis Function Data Descriptor (D-RBFDD) network, is very effective. This is shown in a set of evaluation experiments using multiple anomaly detection scenarios created from publicly available image classification datasets, and a real-world anomaly detection dataset in which different types of arrhythmia are detected in electrocardiogram (ECG) data. Our experiments show that the D-RBFDD network out-performs state-of-the-art anomaly detection methods including the Deep Support Vector Data Descriptor (Deep SVDD), One-Class SVM, and Isolation Forest on the image datasets, and produces competitive results for the ECG dataset.