 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTADP-RME: A Trust-Adaptive Differential Privacy Framework for Enhancing Reliability of Data-Driven Systems
Apr 09, 2026Ensuring reliability in adversarial settings necessitates treating privacy as a foundational component of data-driven systems. While differential privacy and cryptographic protocols offer strong guarantees, existing schemes rely on a fixed privacy budget, leading to a rigid utility-privacy trade-off that fails under heterogeneous user trust. Moreover, noise-only differential privacy preserves geometric structure, which inference attacks exploit, causing privacy leakage. We propose TADP-RME (Trust-Adaptive Differential Privacy with Reverse Manifold Embedding), a framework that enhances reliability under varying levels of user trust. It introduces an inverse trust score in the range [0,1] to adaptively modulate the privacy budget, enabling smooth transitions between utility and privacy. Additionally, Reverse Manifold Embedding applies a nonlinear transformation to disrupt local geometric relationships while preserving formal differential privacy guarantees through post-processing. Theoretical and empirical results demonstrate improved privacy-utility trade-offs, reducing attack success rates by up to 3.1 percent without significant utility degradation. The framework consistently outperforms existing methods against inference attacks, providing a unified approach for reliable learning in adversarial environments.
Integrating Unsupervised Clustering and Label-specific Oversampling to Tackle Imbalanced Multi-label Data
Sep 25, 2021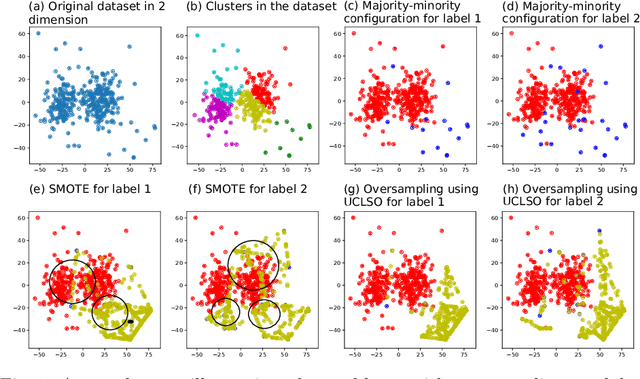
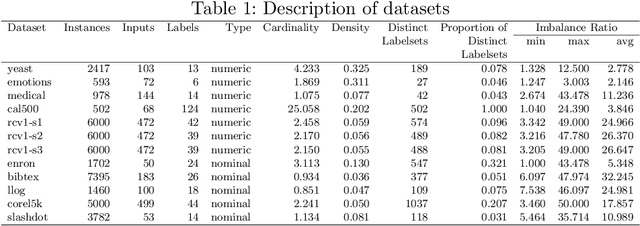
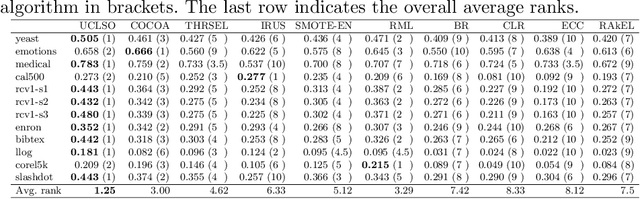
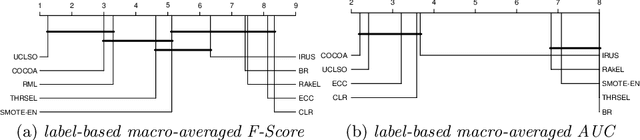
There is often a mixture of very frequent labels and very infrequent labels in multi-label datatsets. This variation in label frequency, a type class imbalance, creates a significant challenge for building efficient multi-label classification algorithms. In this paper, we tackle this problem by proposing a minority class oversampling scheme, UCLSO, which integrates Unsupervised Clustering and Label-Specific data Oversampling. Clustering is performed to find out the key distinct and locally connected regions of a multi-label dataset (irrespective of the label information). Next, for each label, we explore the distributions of minority points in the cluster sets. Only the minority points within a cluster are used to generate the synthetic minority points that are used for oversampling. Even though the cluster set is the same across all labels, the distributions of the synthetic minority points will vary across the labels. The training dataset is augmented with the set of label-specific synthetic minority points, and classifiers are trained to predict the relevance of each label independently. Experiments using 12 multi-label datasets and several multi-label algorithms show that the proposed method performed very well compared to the other competing algorithms.