 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Effect Bandits
Jun 23, 2021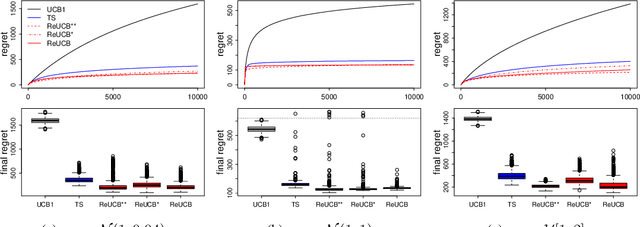
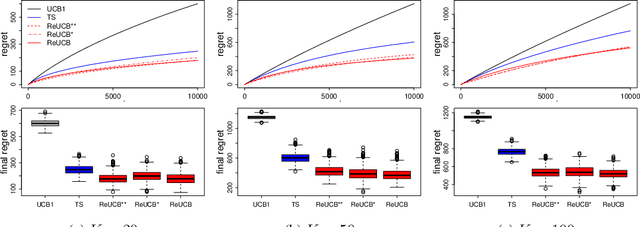
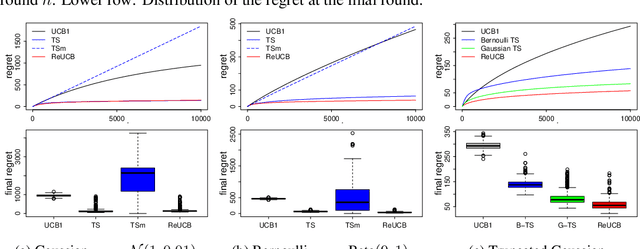
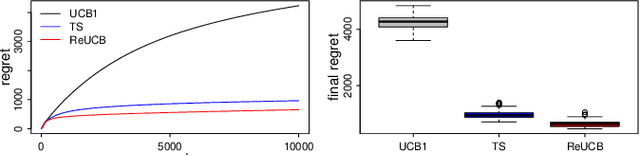
This paper studies regret minimization in multi-armed bandits, a classical online learning problem. To develop more statistically-efficient algorithms, we propose to use the assumption of a random-effect model. In this model, the mean rewards of arms are drawn independently from an unknown distribution, whose parameters we estimate. We provide an estimator of the arm means in this model and also analyze its uncertainty. Based on these results, we design a UCB algorithm, which we call ReUCB. We analyze ReUCB and prove a Bayes regret bound on its $n$-round regret, which matches an existing lower bound. Our experiments show that ReUCB can outperform Thompson sampling in various scenarios, without assuming that the prior distribution of arm means is known.
Fixed-Budget Best-Arm Identification in Contextual Bandits: A Static-Adaptive Algorithm
Jun 22, 2021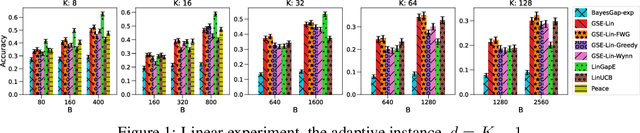
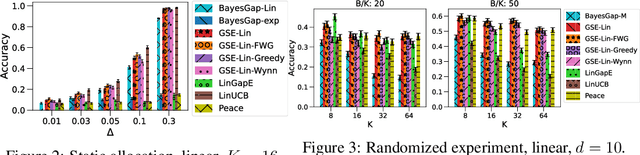
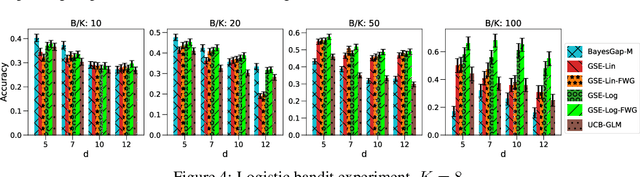
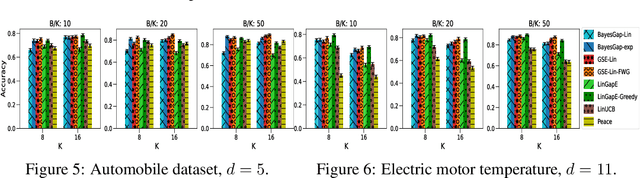
We study the problem of best-arm identification (BAI) in contextual bandits in the fixed-budget setting. We propose a general successive elimination algorithm that proceeds in stages and eliminates a fixed fraction of suboptimal arms in each stage. This design takes advantage of the strengths of static and adaptive allocations. We analyze the algorithm in linear models and obtain a better error bound than prior work. We also apply it to generalized linear models (GLMs) and bound its error. This is the first BAI algorithm for GLMs in the fixed-budget setting. Our extensive numerical experiments show that our algorithm outperforms the state of art.
Thompson Sampling with a Mixture Prior
Jun 10, 2021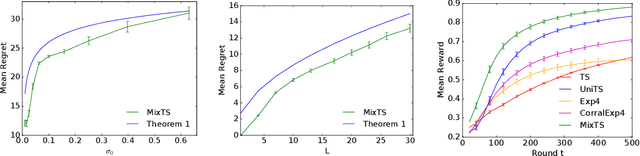
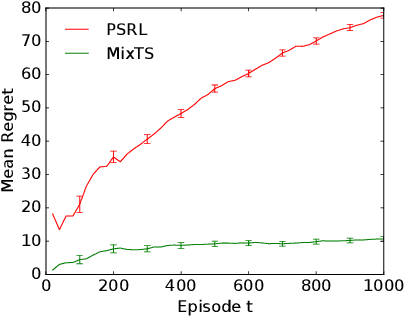
We study Thompson sampling (TS) in online decision-making problems where the uncertain environment is sampled from a mixture distribution. This is relevant to multi-task settings, where a learning agent is faced with different classes of problems. We incorporate this structure in a natural way by initializing TS with a mixture prior -- dubbed MixTS -- and develop a novel, general technique for analyzing the regret of TS with such priors. We apply this technique to derive Bayes regret bounds for MixTS in both linear bandits and tabular Markov decision processes (MDPs). Our regret bounds reflect the structure of the problem and depend on the number of components and confidence width of each component of the prior. Finally, we demonstrate the empirical effectiveness of MixTS in both synthetic and real-world experiments.
CORe: Capitalizing On Rewards in Bandit Exploration
Mar 07, 2021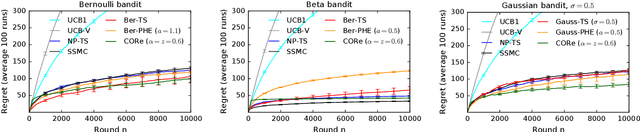
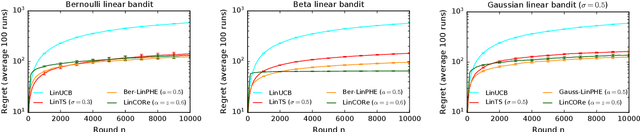
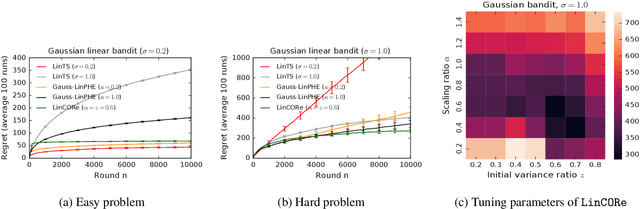
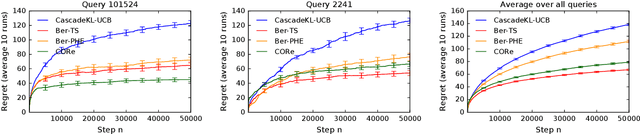
We propose a bandit algorithm that explores purely by randomizing its past observations. In particular, the sufficient optimism in the mean reward estimates is achieved by exploiting the variance in the past observed rewards. We name the algorithm Capitalizing On Rewards (CORe). The algorithm is general and can be easily applied to different bandit settings. The main benefit of CORe is that its exploration is fully data-dependent. It does not rely on any external noise and adapts to different problems without parameter tuning. We derive a $\tilde O(d\sqrt{n\log K})$ gap-free bound on the $n$-round regret of CORe in a stochastic linear bandit, where $d$ is the number of features and $K$ is the number of arms. Extensive empirical evaluation on multiple synthetic and real-world problems demonstrates the effectiveness of CORe.
Meta-Thompson Sampling
Feb 11, 2021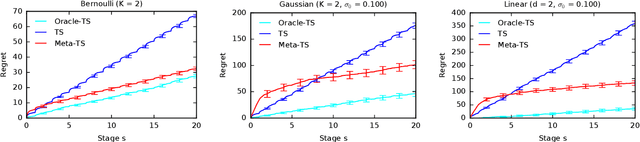
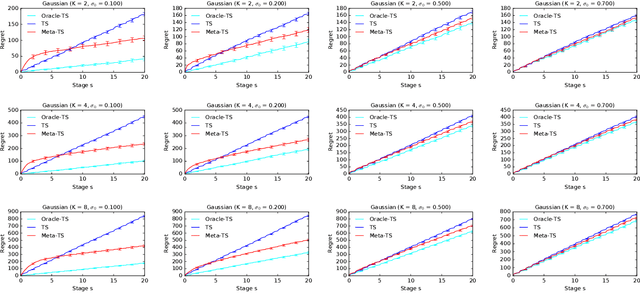
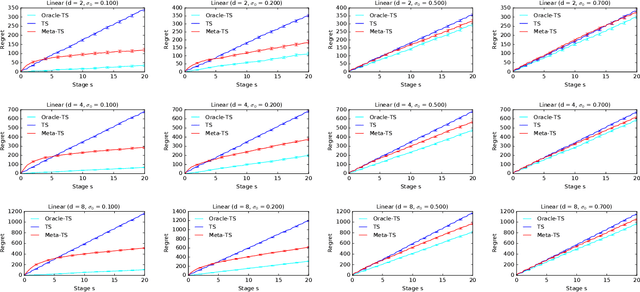
Efficient exploration in multi-armed bandits is a fundamental online learning problem. In this work, we propose a variant of Thompson sampling that learns to explore better as it interacts with problem instances drawn from an unknown prior distribution. Our algorithm meta-learns the prior and thus we call it Meta-TS. We propose efficient implementations of Meta-TS and analyze it in Gaussian bandits. Our analysis shows the benefit of meta-learning the prior and is of a broader interest, because we derive the first prior-dependent upper bound on the Bayes regret of Thompson sampling. This result is complemented by empirical evaluation, which shows that Meta-TS quickly adapts to the unknown prior.
Non-Stationary Latent Bandits
Dec 01, 2020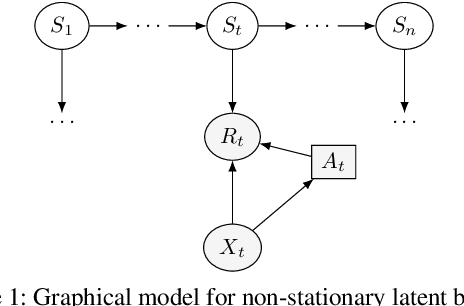
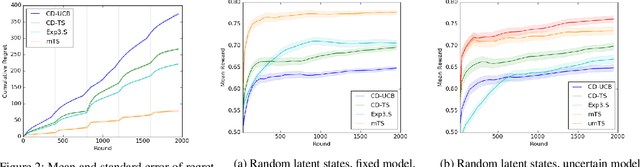
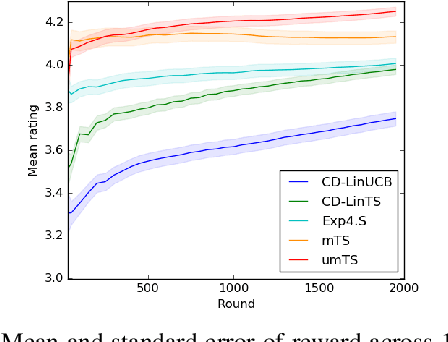
Users of recommender systems often behave in a non-stationary fashion, due to their evolving preferences and tastes over time. In this work, we propose a practical approach for fast personalization to non-stationary users. The key idea is to frame this problem as a latent bandit, where the prototypical models of user behavior are learned offline and the latent state of the user is inferred online from its interactions with the models. We call this problem a non-stationary latent bandit. We propose Thompson sampling algorithms for regret minimization in non-stationary latent bandits, analyze them, and evaluate them on a real-world dataset. The main strength of our approach is that it can be combined with rich offline-learned models, which can be misspecified, and are subsequently fine-tuned online using posterior sampling. In this way, we naturally combine the strengths of offline and online learning.
Influence Diagram Bandits: Variational Thompson Sampling for Structured Bandit Problems
Jul 09, 2020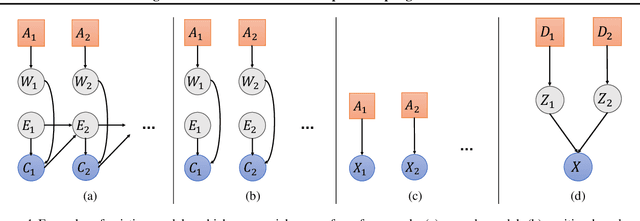
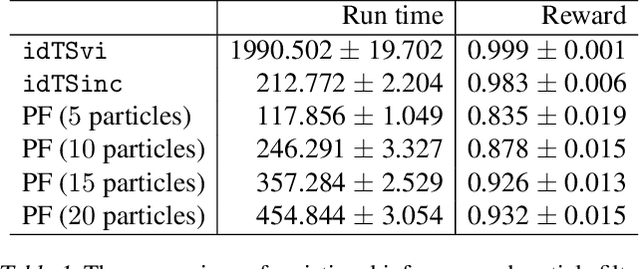
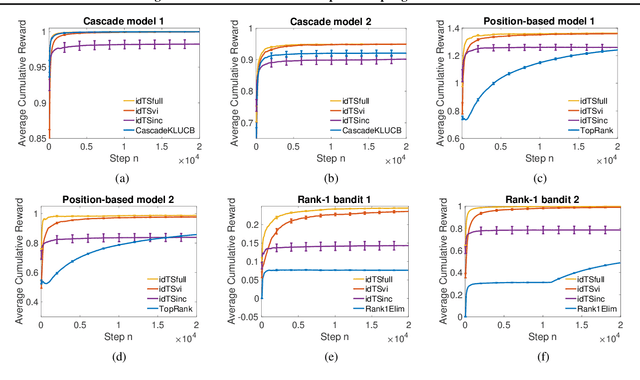
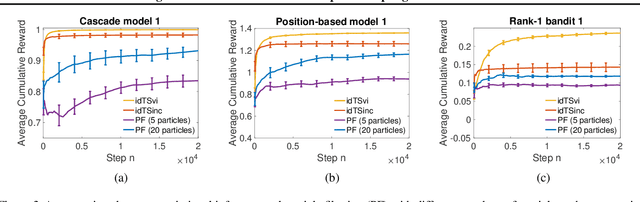
We propose a novel framework for structured bandits, which we call an influence diagram bandit. Our framework captures complex statistical dependencies between actions, latent variables, and observations; and thus unifies and extends many existing models, such as combinatorial semi-bandits, cascading bandits, and low-rank bandits. We develop novel online learning algorithms that learn to act efficiently in our models. The key idea is to track a structured posterior distribution of model parameters, either exactly or approximately. To act, we sample model parameters from their posterior and then use the structure of the influence diagram to find the most optimistic action under the sampled parameters. We empirically evaluate our algorithms in three structured bandit problems, and show that they perform as well as or better than problem-specific state-of-the-art baselines.
Latent Bandits Revisited
Jun 15, 2020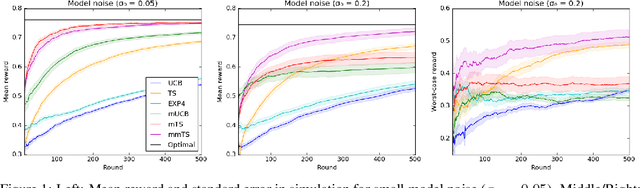
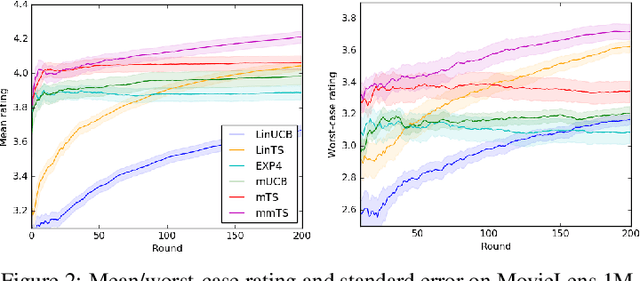
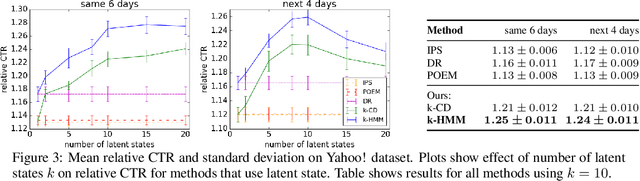
A latent bandit problem is one in which the learning agent knows the arm reward distributions conditioned on an unknown discrete latent state. The primary goal of the agent is to identify the latent state, after which it can act optimally. This setting is a natural midpoint between online and offline learning---complex models can be learned offline with the agent identifying latent state online---of practical relevance in, say, recommender systems. In this work, we propose general algorithms for this setting, based on both upper confidence bounds (UCBs) and Thompson sampling. Our methods are contextual and aware of model uncertainty and misspecification. We provide a unified theoretical analysis of our algorithms, which have lower regret than classic bandit policies when the number of latent states is smaller than actions. A comprehensive empirical study showcases the advantages of our approach.
Piecewise-Stationary Off-Policy Optimization
Jun 15, 2020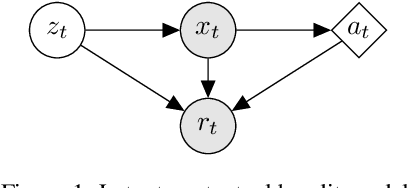
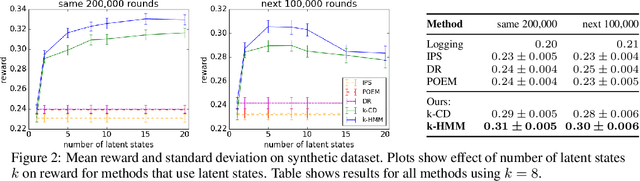
Off-policy learning is a framework for evaluating and optimizing policies without deploying them, from data collected by another policy. Real-world environments are typically non-stationary and the offline learned policies should adapt to these changes. To address this challenge, we study the novel problem of off-policy optimization in piecewise-stationary contextual bandits. Our proposed solution has two phases. In the offline learning phase, we partition logged data into categorical latent states and learn a near-optimal sub-policy for each state. In the online deployment phase, we adaptively switch between the learned sub-policies based on their performance. This approach is practical and analyzable, and we provide guarantees on both the quality of off-policy optimization and the regret during online deployment. To show the effectiveness of our approach, we compare it to state-of-the-art baselines on both synthetic and real-world datasets. Our approach outperforms methods that act only on observed context.
Differentiable Meta-Learning in Contextual Bandits
Jun 09, 2020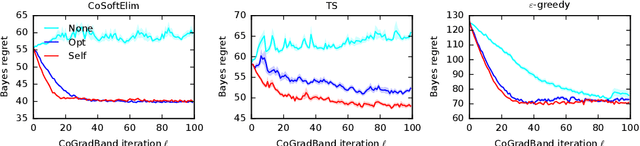
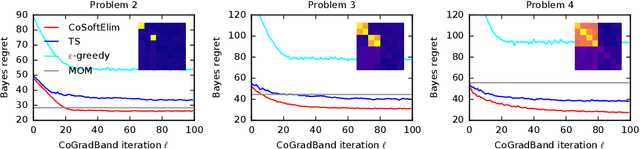
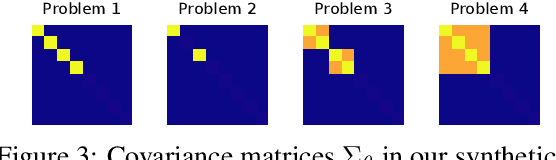
We study a contextual bandit setting where the learning agent has access to sampled bandit instances from an unknown prior distribution $\mathcal{P}$. The goal of the agent is to achieve high reward on average over the instances drawn from $\mathcal{P}$. This setting is of a particular importance because it formalizes the offline optimization of bandit policies, to perform well on average over anticipated bandit instances. The main idea in our work is to optimize differentiable bandit policies by policy gradients. We derive reward gradients that reflect the structure of our problem, and propose contextual policies that are parameterized in a differentiable way and have low regret. Our algorithmic and theoretical contributions are supported by extensive experiments that show the importance of baseline subtraction, learned biases, and the practicality of our approach on a range of classification tasks.