 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteerable Pluralism: Pluralistic Alignment via Few-Shot Comparative Regression
Aug 11, 2025Large language models (LLMs) are currently aligned using techniques such as reinforcement learning from human feedback (RLHF). However, these methods use scalar rewards that can only reflect user preferences on average. Pluralistic alignment instead seeks to capture diverse user preferences across a set of attributes, moving beyond just helpfulness and harmlessness. Toward this end, we propose a steerable pluralistic model based on few-shot comparative regression that can adapt to individual user preferences. Our approach leverages in-context learning and reasoning, grounded in a set of fine-grained attributes, to compare response options and make aligned choices. To evaluate our algorithm, we also propose two new steerable pluralistic benchmarks by adapting the Moral Integrity Corpus (MIC) and the HelpSteer2 datasets, demonstrating the applicability of our approach to value-aligned decision-making and reward modeling, respectively. Our few-shot comparative regression approach is interpretable and compatible with different attributes and LLMs, while outperforming multiple baseline and state-of-the-art methods. Our work provides new insights and research directions in pluralistic alignment, enabling a more fair and representative use of LLMs and advancing the state-of-the-art in ethical AI.
LEARN: A Unified Framework for Multi-Task Domain Adapt Few-Shot Learning
Dec 20, 2024



Both few-shot learning and domain adaptation sub-fields in Computer Vision have seen significant recent progress in terms of the availability of state-of-the-art algorithms and datasets. Frameworks have been developed for each sub-field; however, building a common system or framework that combines both is something that has not been explored. As part of our research, we present the first unified framework that combines domain adaptation for the few-shot learning setting across 3 different tasks - image classification, object detection and video classification. Our framework is highly modular with the capability to support few-shot learning with/without the inclusion of domain adaptation depending on the algorithm. Furthermore, the most important configurable feature of our framework is the on-the-fly setup for incremental $n$-shot tasks with the optional capability to configure the system to scale to a traditional many-shot task. With more focus on Self-Supervised Learning (SSL) for current few-shot learning approaches, our system also supports multiple SSL pre-training configurations. To test our framework's capabilities, we provide benchmarks on a wide range of algorithms and datasets across different task and problem settings. The code is open source has been made publicly available here: https://gitlab.kitware.com/darpa_learn/learn
From Kinematics To Dynamics: Estimating Center of Pressure and Base of Support from Video Frames of Human Motion
Jan 02, 2020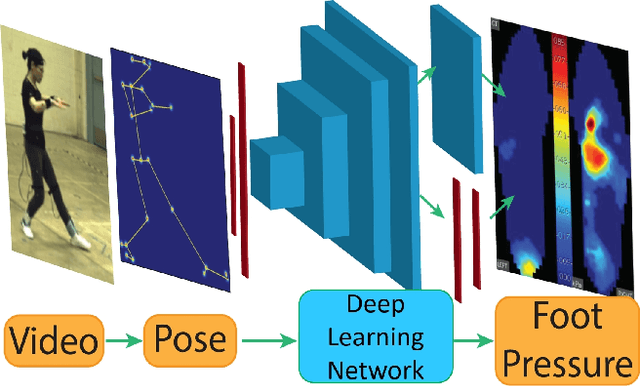
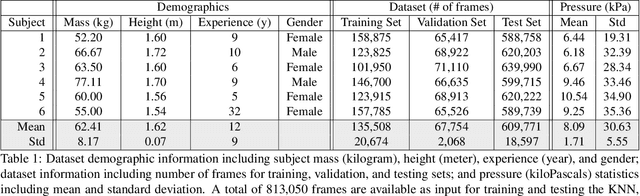
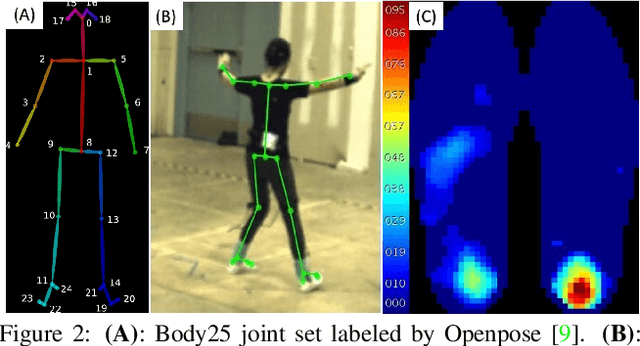
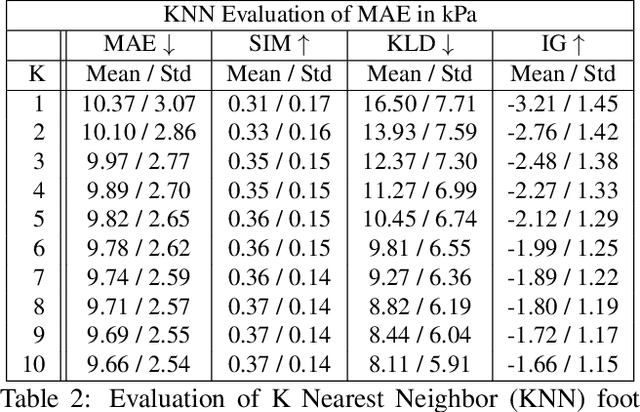
To gain an understanding of the relation between a given human pose image and the corresponding physical foot pressure of the human subject, we propose and validate two end-to-end deep learning architectures, PressNet and PressNet-Simple, to regress foot pressure heatmaps (dynamics) from 2D human pose (kinematics) derived from a video frame. A unique video and foot pressure data set of 813,050 synchronized pairs, composed of 5-minute long choreographed Taiji movement sequences of 6 subjects, is collected and used for leaving-one-subject-out cross validation. Our initial experimental results demonstrate reliable and repeatable foot pressure prediction from a single image, setting the first baseline for such a complex cross modality mapping problem in computer vision. Furthermore, we compute and quantitatively validate the Center of Pressure (CoP) and Base of Support (BoS) from predicted foot pressure distribution, obtaining key components in pose stability analysis from images with potential applications in kinesiology, medicine, sports and robotics.