 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Sparse Reinforcement Learning
Nov 08, 2020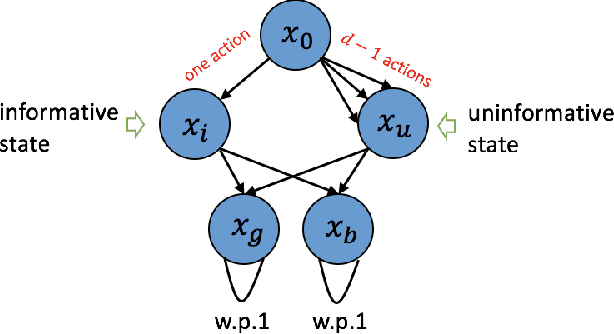
We investigate the hardness of online reinforcement learning in sparse linear Markov decision process (MDP), with a special focus on the high-dimensional regime where the ambient dimension is larger than the number of episodes. Our contribution is two-fold. First, we provide a lower bound showing that linear regret is generally unavoidable, even if there exists a policy that collects well-conditioned data. Second, we show that if the learner has oracle access to a policy that collects well-conditioned data, then a variant of Lasso fitted Q-iteration enjoys a regret of $\tilde{O}(N^{2/3})$ where $N$ is the number of episodes.
Low-rank Tensor Bandits
Jul 31, 2020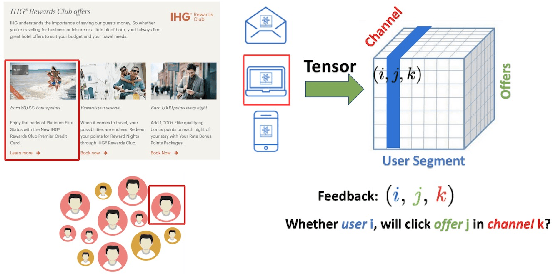
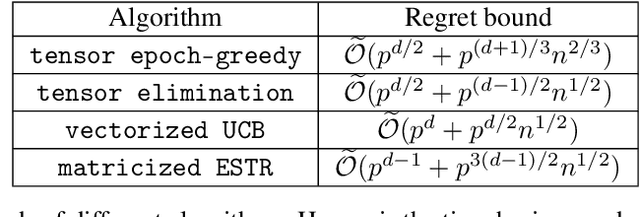
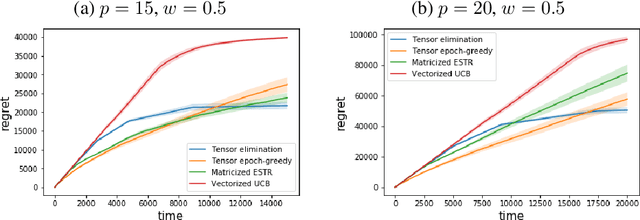
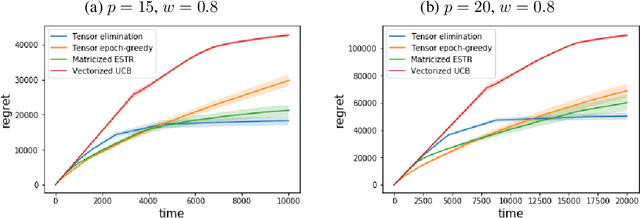
In recent years, multi-dimensional online decision making has been playing a crucial role in many practical applications such as online recommendation and digital marketing. To solve it, we introduce stochastic low-rank tensor bandits, a class of bandits whose mean rewards can be represented as a low-rank tensor. We propose two learning algorithms, tensor epoch-greedy and tensor elimination, and develop finite-time regret bounds for them. We observe that tensor elimination has an optimal dependency on the time horizon, while tensor epoch-greedy has a sharper dependency on tensor dimensions. Numerical experiments further back up these theoretical findings and show that our algorithms outperform various state-of-the-art approaches that ignore the tensor low-rank structure.
Provably Efficient Adaptive Approximate Policy Iteration
Mar 15, 2020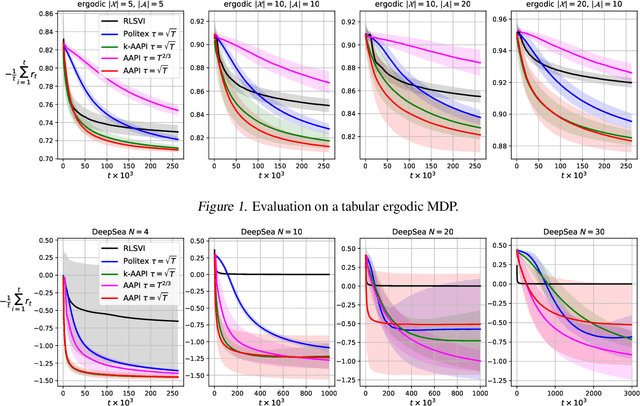
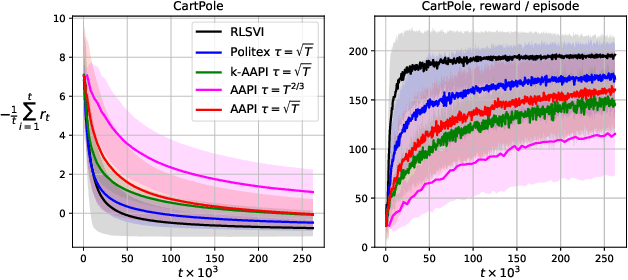
Model-free reinforcement learning algorithms combined with value function approximation have recently achieved impressive performance in a variety of application domains, including games and robotics. However, the theoretical understanding of such algorithms is limited, and existing results are largely focused on episodic or discounted Markov decision processes (MDPs). In this work, we present adaptive approximate policy iteration (AAPI), a learning scheme which enjoys a O(T^{2/3}) regret bound for undiscounted, continuing learning in uniformly ergodic MDPs. This is an improvement over the best existing bound of O(T^{3/4}) for the average-reward case with function approximation. Our algorithm and analysis rely on adversarial online learning techniques, where value functions are treated as losses. The main technical novelty is the use of a data-dependent adaptive learning rate coupled with a so-called optimistic prediction of upcoming losses. In addition to theoretical guarantees, we demonstrate the advantages of our approach empirically on several environments.
Residual Bootstrap Exploration for Bandit Algorithms
Feb 19, 2020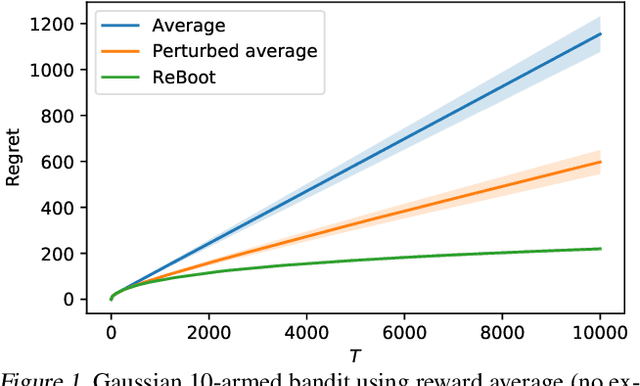
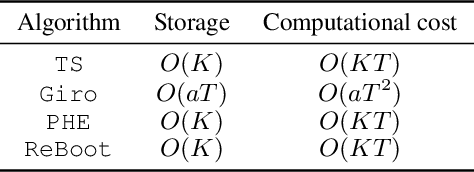
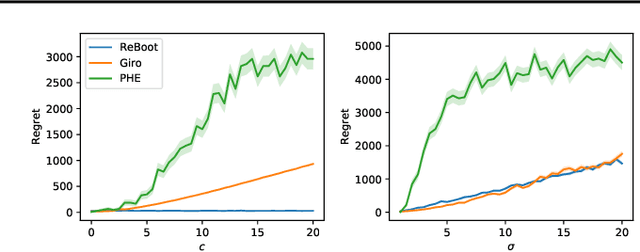
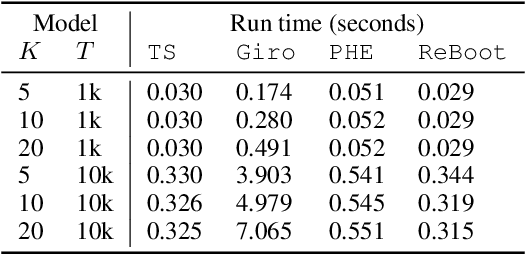
In this paper, we propose a novel perturbation-based exploration method in bandit algorithms with bounded or unbounded rewards, called residual bootstrap exploration (\texttt{ReBoot}). The \texttt{ReBoot} enforces exploration by injecting data-driven randomness through a residual-based perturbation mechanism. This novel mechanism captures the underlying distributional properties of fitting errors, and more importantly boosts exploration to escape from suboptimal solutions (for small sample sizes) by inflating variance level in an \textit{unconventional} way. In theory, with appropriate variance inflation level, \texttt{ReBoot} provably secures instance-dependent logarithmic regret in Gaussian multi-armed bandits. We evaluate the \texttt{ReBoot} in different synthetic multi-armed bandits problems and observe that the \texttt{ReBoot} performs better for unbounded rewards and more robustly than \texttt{Giro} \cite{kveton2018garbage} and \texttt{PHE} \cite{kveton2019perturbed}, with comparable computational efficiency to the Thompson sampling method.
Adaptive Exploration in Linear Contextual Bandit
Oct 15, 2019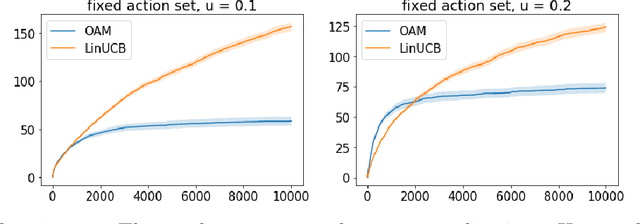
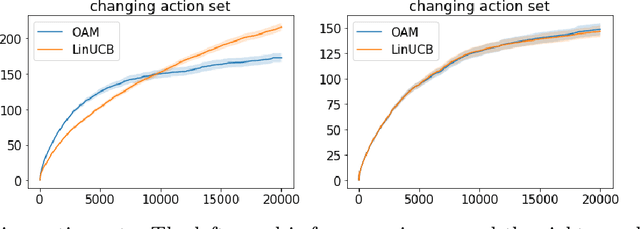
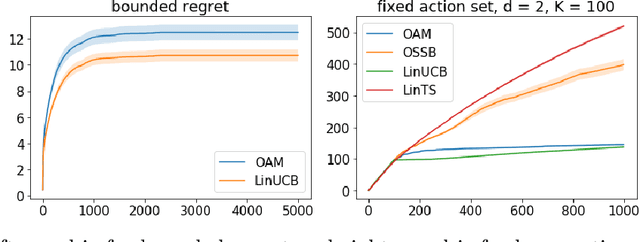
Contextual bandits serve as a fundamental model for many sequential decision making tasks. The most popular theoretically justified approaches are based on the optimism principle. While these algorithms can be practical, they are known to be suboptimal asymptotically (Lattimore and Szepesvari, 2017). On the other hand, existing asymptotically optimal algorithms for this problem do not exploit the linear structure in an optimal way and suffer from lower-order terms that dominate the regret in all practically interesting regimes. We start to bridge the gap by designing an algorithm that is asymptotically optimal and has good finite-time empirical performance. At the same time, we make connections to the recent literature on when exploration-free methods are effective. Indeed, if the distribution of contexts is well behaved, then our algorithm acts mostly greedily and enjoys sub-logarithmic regret. Furthermore, our approach is adaptive in the sense that it automatically detects the nice case. Numerical results demonstrate significant regret reductions by our method relative to several baselines.
Bootstrapping Upper Confidence Bound
Jul 23, 2019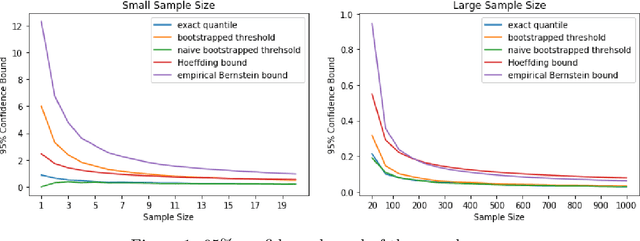
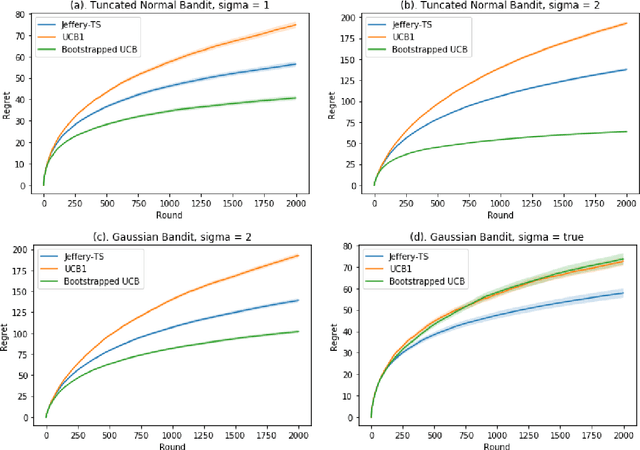
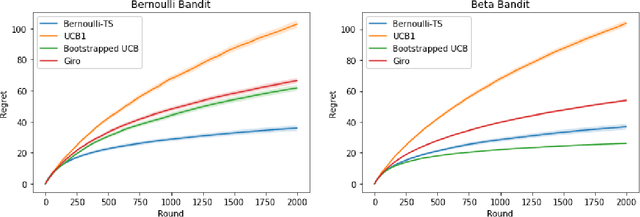
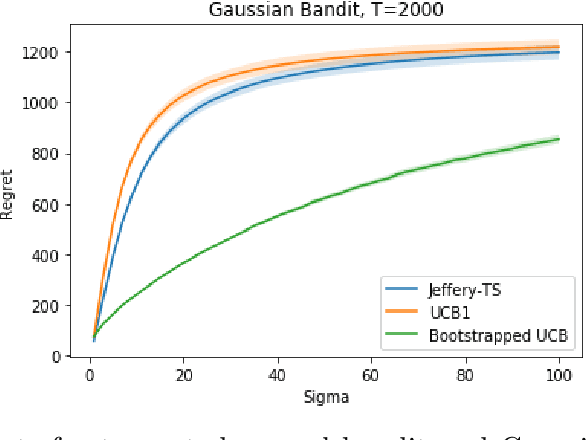
Upper Confidence Bound (UCB) method is arguably the most celebrated one used in online decision making with partial information feedback. Existing techniques for constructing confidence bounds are typically built upon various concentration inequalities, which thus lead to over-exploration. In this paper, we propose a non-parametric and data-dependent UCB algorithm based on the multiplier bootstrap. To improve its finite sample performance, we further incorporate second-order correction into the above construction. In theory, we derive both problem-dependent and problem-independent regret bounds for multi-armed bandits under a much weaker tail assumption than the standard sub-Gaussianity. Numerical results demonstrate significant regret reductions by our method, in comparison with several baselines in a range of multi-armed and linear bandit problems.
Sparse Tensor Additive Regression
Mar 31, 2019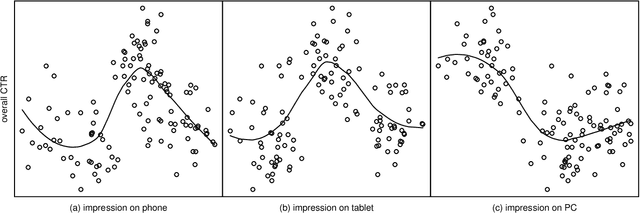
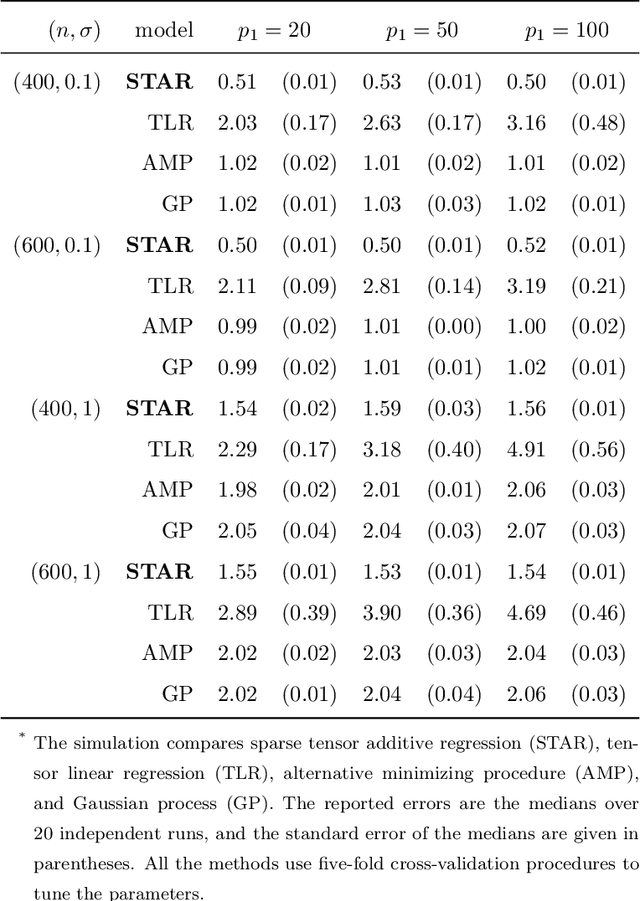
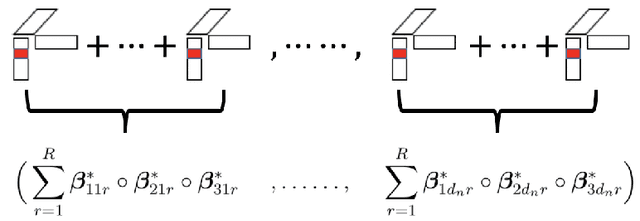
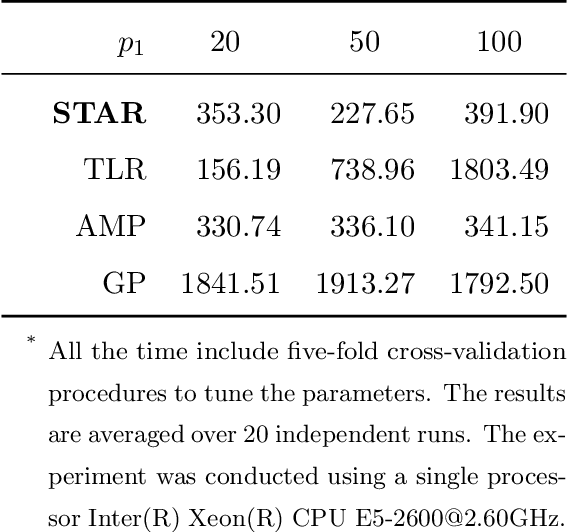
Tensors are becoming prevalent in modern applications such as medical imaging and digital marketing. In this paper, we propose a sparse tensor additive regression (STAR) that models a scalar response as a flexible nonparametric function of tensor covariates. The proposed model effectively exploits the sparse and low-rank structures in the tensor additive regression. We formulate the parameter estimation as a non-convex optimization problem, and propose an efficient penalized alternating minimization algorithm. We establish a non-asymptotic error bound for the estimator obtained from each iteration of the proposed algorithm, which reveals an interplay between the optimization error and the statistical rate of convergence. We demonstrate the efficacy of STAR through extensive comparative simulation studies, and an application to the click-through-rate prediction in online advertising.
Sparse and Low-rank Tensor Estimation via Cubic Sketchings
Jan 29, 2018
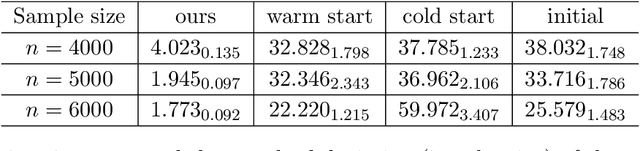
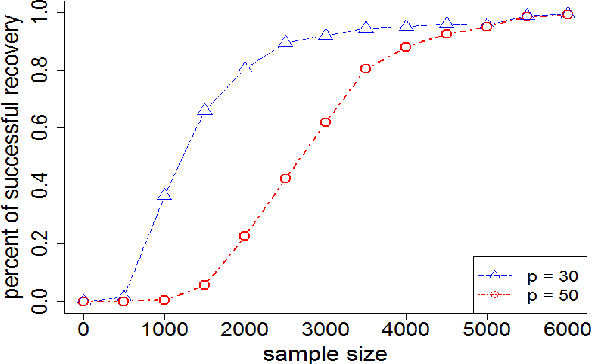
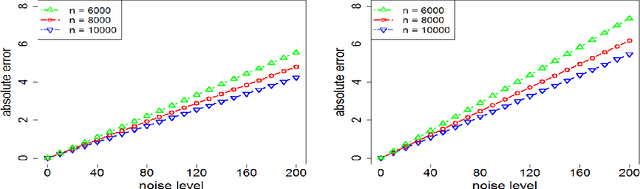
In this paper, we propose a general framework for sparse and low-rank tensor estimation from cubic sketchings. A two-stage non-convex implementation is developed based on sparse tensor decomposition and thresholded gradient descent, which ensures exact recovery in the noiseless case and stable recovery in the noisy case with high probability. The non-asymptotic analysis sheds light on an interplay between optimization error and statistical error. The proposed procedure is shown to be rate-optimal under certain conditions. As a technical by-product, novel high-order concentration inequalities are derived for studying high-moment sub-Gaussian tensors. An interesting tensor formulation illustrates the potential application to high-order interaction pursuit in high-dimensional linear regression.
Simultaneous Clustering and Estimation of Heterogeneous Graphical Models
Jan 12, 2018
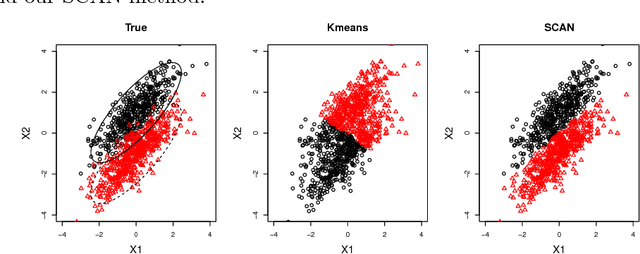
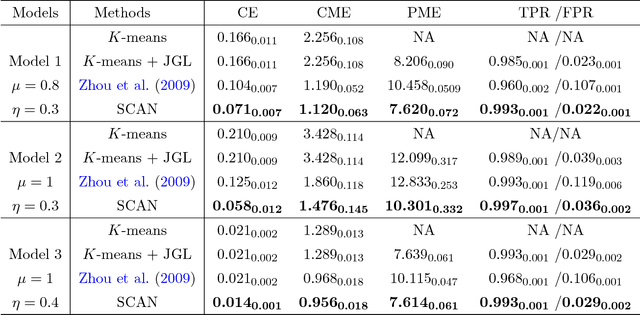
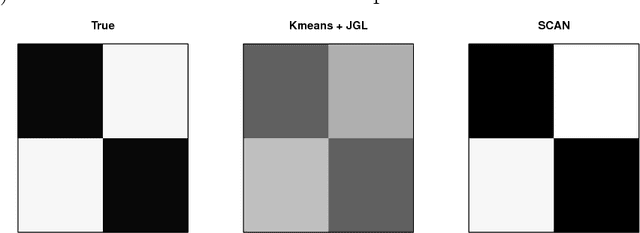
We consider joint estimation of multiple graphical models arising from heterogeneous and high-dimensional observations. Unlike most previous approaches which assume that the cluster structure is given in advance, an appealing feature of our method is to learn cluster structure while estimating heterogeneous graphical models. This is achieved via a high dimensional version of Expectation Conditional Maximization (ECM) algorithm (Meng and Rubin, 1993). A joint graphical lasso penalty is imposed on the conditional maximization step to extract both homogeneity and heterogeneity components across all clusters. Our algorithm is computationally efficient due to fast sparse learning routines and can be implemented without unsupervised learning knowledge. The superior performance of our method is demonstrated by extensive experiments and its application to a Glioblastoma cancer dataset reveals some new insights in understanding the Glioblastoma cancer. In theory, a non-asymptotic error bound is established for the output directly from our high dimensional ECM algorithm, and it consists of two quantities: statistical error (statistical accuracy) and optimization error (computational complexity). Such a result gives a theoretical guideline in terminating our ECM iterations.