 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Does Monolingual Data Help Multilingual Translation: The Role of Domain and Model Scale
May 23, 2023Multilingual machine translation (MMT), trained on a mixture of parallel and monolingual data, is key for improving translation in low-resource language pairs. However, the literature offers conflicting results on the performance of different methods. To resolve this, we examine how denoising autoencoding (DAE) and backtranslation (BT) impact MMT under different data conditions and model scales. Unlike prior studies, we use a realistic dataset of 100 directions and consider many domain combinations of monolingual and test data. We find that monolingual data generally helps MMT, but models are surprisingly brittle to domain mismatches, especially at smaller model scales. BT is beneficial when the parallel, monolingual, and test data sources are similar but can be detrimental otherwise, while DAE is less effective than previously reported. Next, we analyze the impact of scale (from 90M to 1.6B parameters) and find it is important for both methods, particularly DAE. As scale increases, DAE transitions from underperforming the parallel-only baseline at 90M to converging with BT performance at 1.6B, and even surpassing it in low-resource. These results offer new insights into how to best use monolingual data in MMT.
SLTUNET: A Simple Unified Model for Sign Language Translation
May 02, 2023



Despite recent successes with neural models for sign language translation (SLT), translation quality still lags behind spoken languages because of the data scarcity and modality gap between sign video and text. To address both problems, we investigate strategies for cross-modality representation sharing for SLT. We propose SLTUNET, a simple unified neural model designed to support multiple SLTrelated tasks jointly, such as sign-to-gloss, gloss-to-text and sign-to-text translation. Jointly modeling different tasks endows SLTUNET with the capability to explore the cross-task relatedness that could help narrow the modality gap. In addition, this allows us to leverage the knowledge from external resources, such as abundant parallel data used for spoken-language machine translation (MT). We show in experiments that SLTUNET achieves competitive and even state-of-the-art performance on PHOENIX-2014T and CSL-Daily when augmented with MT data and equipped with a set of optimization techniques. We further use the DGS Corpus for end-to-end SLT for the first time. It covers broader domains with a significantly larger vocabulary, which is more challenging and which we consider to allow for a more realistic assessment of the current state of SLT than the former two. Still, SLTUNET obtains improved results on the DGS Corpus. Code is available at https://github.com/bzhangGo/sltunet.
MDP: A Generalized Framework for Text-Guided Image Editing by Manipulating the Diffusion Path
Mar 30, 2023Image generation using diffusion can be controlled in multiple ways. In this paper, we systematically analyze the equations of modern generative diffusion networks to propose a framework, called MDP, that explains the design space of suitable manipulations. We identify 5 different manipulations, including intermediate latent, conditional embedding, cross attention maps, guidance, and predicted noise. We analyze the corresponding parameters of these manipulations and the manipulation schedule. We show that some previous editing methods fit nicely into our framework. Particularly, we identified one specific configuration as a new type of control by manipulating the predicted noise, which can perform higher-quality edits than previous work for a variety of local and global edits.
Efficient CTC Regularization via Coarse Labels for End-to-End Speech Translation
Feb 21, 2023For end-to-end speech translation, regularizing the encoder with the Connectionist Temporal Classification (CTC) objective using the source transcript or target translation as labels can greatly improve quality metrics. However, CTC demands an extra prediction layer over the vocabulary space, bringing in nonnegligible model parameters and computational overheads, although this layer is typically not used for inference. In this paper, we re-examine the need for genuine vocabulary labels for CTC for regularization and explore strategies to reduce the CTC label space, targeting improved efficiency without quality degradation. We propose coarse labeling for CTC (CoLaCTC), which merges vocabulary labels via simple heuristic rules, such as using truncation, division or modulo (MOD) operations. Despite its simplicity, our experiments on 4 source and 8 target languages show that CoLaCTC with MOD particularly can compress the label space aggressively to 256 and even further, gaining training efficiency (1.18x ~ 1.77x speedup depending on the original vocabulary size) yet still delivering comparable or better performance than the CTC baseline. We also show that CoLaCTC successfully generalizes to CTC regularization regardless of using transcript or translation for labeling.
3DShape2VecSet: A 3D Shape Representation for Neural Fields and Generative Diffusion Models
Feb 01, 2023We introduce 3DShape2VecSet, a novel shape representation for neural fields designed for generative diffusion models. Our shape representation can encode 3D shapes given as surface models or point clouds, and represents them as neural fields. The concept of neural fields has previously been combined with a global latent vector, a regular grid of latent vectors, or an irregular grid of latent vectors. Our new representation encodes neural fields on top of a set of vectors. We draw from multiple concepts, such as the radial basis function representation and the cross attention and self-attention function, to design a learnable representation that is especially suitable for processing with transformers. Our results show improved performance in 3D shape encoding and 3D shape generative modeling tasks. We demonstrate a wide variety of generative applications: unconditioned generation, category-conditioned generation, text-conditioned generation, point-cloud completion, and image-conditioned generation.
Prompting Large Language Model for Machine Translation: A Case Study
Jan 18, 2023



Research on prompting has shown excellent performance with little or even no supervised training across many tasks. However, prompting for machine translation is still under-explored in the literature. We fill this gap by offering a systematic study on prompting strategies for translation, examining various factors for prompt template and demonstration example selection. We further explore the use of monolingual data and the feasibility of cross-lingual, cross-domain, and sentence-to-document transfer learning in prompting. Extensive experiments with GLM-130B (Zeng et al., 2022) as the testbed show that 1) the number and the quality of prompt examples matter, where using suboptimal examples degenerates translation; 2) several features of prompt examples, such as semantic similarity, show significant Spearman correlation with their prompting performance; yet, none of the correlations are strong enough; 3) using pseudo parallel prompt examples constructed from monolingual data via zero-shot prompting could improve translation; and 4) improved performance is achievable by transferring knowledge from prompt examples selected in other settings. We finally provide an analysis on the model outputs and discuss several problems that prompting still suffers from.
Investigating Neuron Disturbing in Fusing Heterogeneous Neural Networks
Oct 24, 2022



Fusing deep learning models trained on separately located clients into a global model in a one-shot communication round is a straightforward implementation of Federated Learning. Although current model fusion methods are shown experimentally valid in fusing neural networks with almost identical architectures, they are rarely theoretically analyzed. In this paper, we reveal the phenomenon of neuron disturbing, where neurons from heterogeneous local models interfere with each other mutually. We give detailed explanations from a Bayesian viewpoint combining the data heterogeneity among clients and properties of neural networks. Furthermore, to validate our findings, we propose an experimental method that excludes neuron disturbing and fuses neural networks via adaptively selecting a local model, called AMS, to execute the prediction according to the input. The experiments demonstrate that AMS is more robust in data heterogeneity than general model fusion and ensemble methods. This implies the necessity of considering neural disturbing in model fusion. Besides, AMS is available for fusing models with varying architectures as an experimental algorithm, and we also list several possible extensions of AMS for future work.
Monolith: Real Time Recommendation System With Collisionless Embedding Table
Sep 27, 2022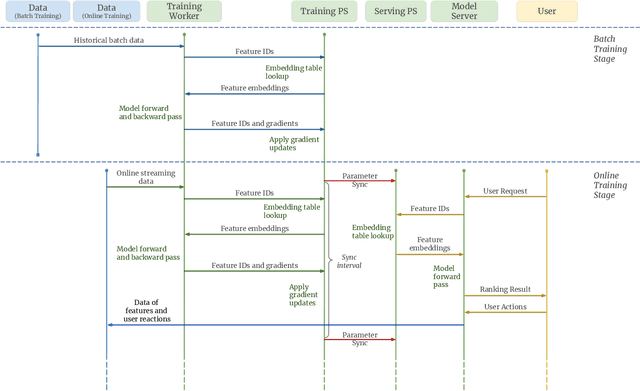

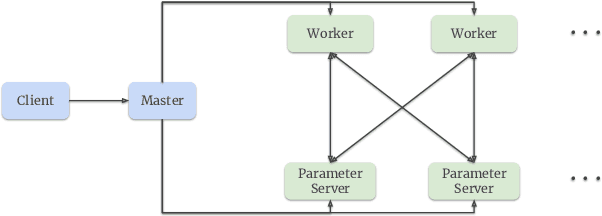
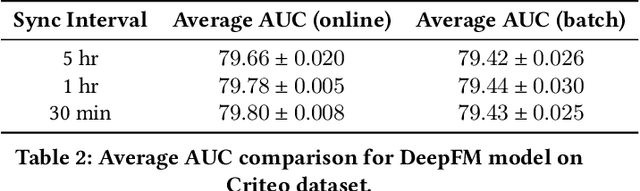
Building a scalable and real-time recommendation system is vital for many businesses driven by time-sensitive customer feedback, such as short-videos ranking or online ads. Despite the ubiquitous adoption of production-scale deep learning frameworks like TensorFlow or PyTorch, these general-purpose frameworks fall short of business demands in recommendation scenarios for various reasons: on one hand, tweaking systems based on static parameters and dense computations for recommendation with dynamic and sparse features is detrimental to model quality; on the other hand, such frameworks are designed with batch-training stage and serving stage completely separated, preventing the model from interacting with customer feedback in real-time. These issues led us to reexamine traditional approaches and explore radically different design choices. In this paper, we present Monolith, a system tailored for online training. Our design has been driven by observations of our application workloads and production environment that reflects a marked departure from other recommendations systems. Our contributions are manifold: first, we crafted a collisionless embedding table with optimizations such as expirable embeddings and frequency filtering to reduce its memory footprint; second, we provide an production-ready online training architecture with high fault-tolerance; finally, we proved that system reliability could be traded-off for real-time learning. Monolith has successfully landed in the BytePlus Recommend product.
Revisiting End-to-End Speech-to-Text Translation From Scratch
Jun 09, 2022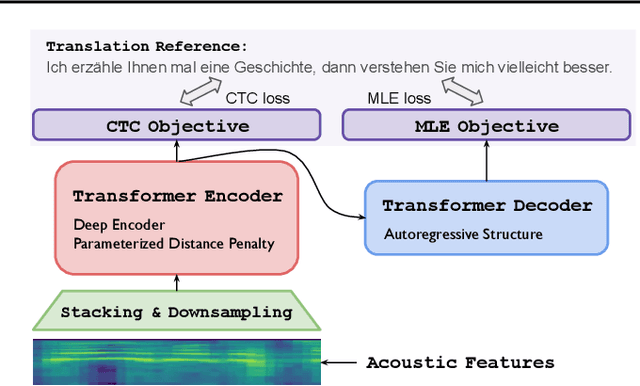
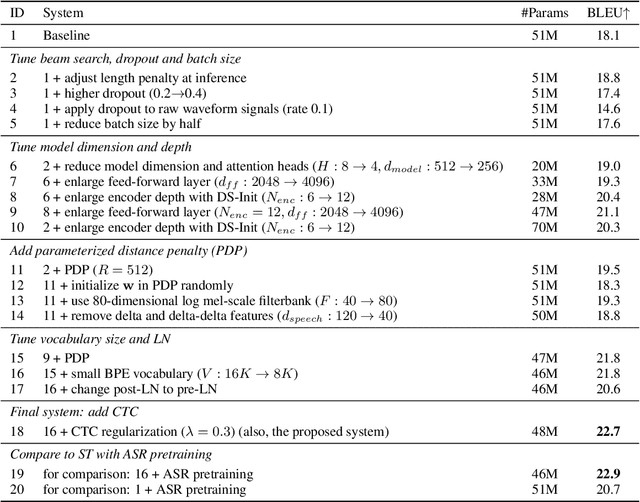
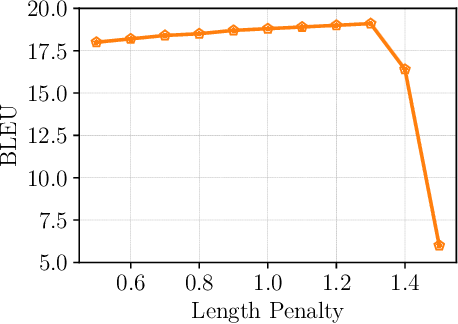
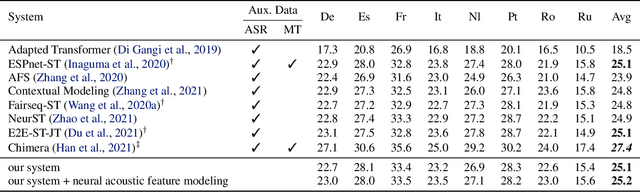
End-to-end (E2E) speech-to-text translation (ST) often depends on pretraining its encoder and/or decoder using source transcripts via speech recognition or text translation tasks, without which translation performance drops substantially. However, transcripts are not always available, and how significant such pretraining is for E2E ST has rarely been studied in the literature. In this paper, we revisit this question and explore the extent to which the quality of E2E ST trained on speech-translation pairs alone can be improved. We reexamine several techniques proven beneficial to ST previously, and offer a set of best practices that biases a Transformer-based E2E ST system toward training from scratch. Besides, we propose parameterized distance penalty to facilitate the modeling of locality in the self-attention model for speech. On four benchmarks covering 23 languages, our experiments show that, without using any transcripts or pretraining, the proposed system reaches and even outperforms previous studies adopting pretraining, although the gap remains in (extremely) low-resource settings. Finally, we discuss neural acoustic feature modeling, where a neural model is designed to extract acoustic features from raw speech signals directly, with the goal to simplify inductive biases and add freedom to the model in describing speech. For the first time, we demonstrate its feasibility and show encouraging results on ST tasks.
3DILG: Irregular Latent Grids for 3D Generative Modeling
May 27, 2022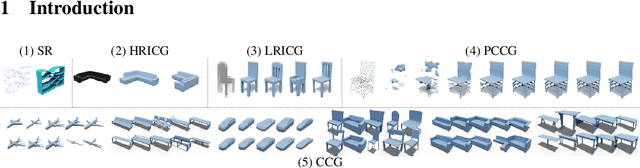

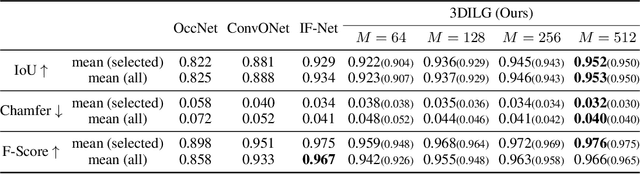
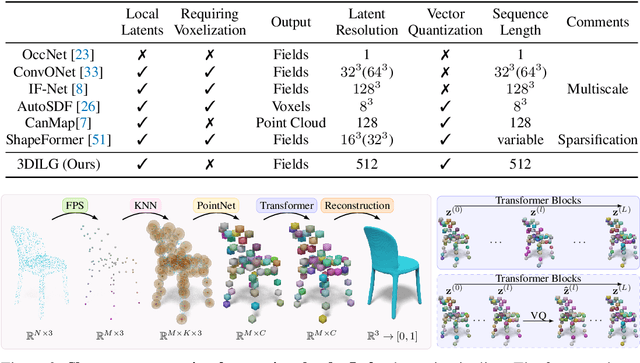
We propose a new representation for encoding 3D shapes as neural fields. The representation is designed to be compatible with the transformer architecture and to benefit both shape reconstruction and shape generation. Existing works on neural fields are grid-based representations with latents defined on a regular grid. In contrast, we define latents on irregular grids, enabling our representation to be sparse and adaptive. In the context of shape reconstruction from point clouds, our shape representation built on irregular grids improves upon grid-based methods in terms of reconstruction accuracy. For shape generation, our representation promotes high-quality shape generation using auto-regressive probabilistic models. We show different applications that improve over the current state of the art. First, we show results for probabilistic shape reconstruction from a single higher resolution image. Second, we train a probabilistic model conditioned on very low resolution images. Third, we apply our model to category-conditioned generation. All probabilistic experiments confirm that we are able to generate detailed and high quality shapes to yield the new state of the art in generative 3D shape modeling.