 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvariant feature extraction from event based stimuli
Jun 21, 2016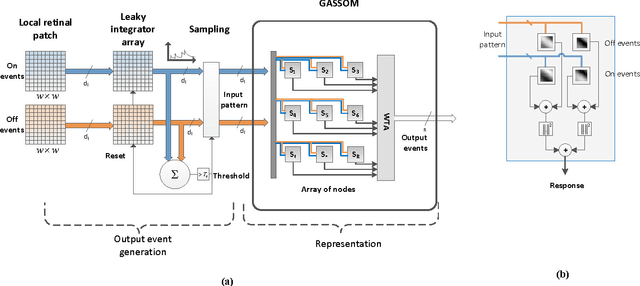
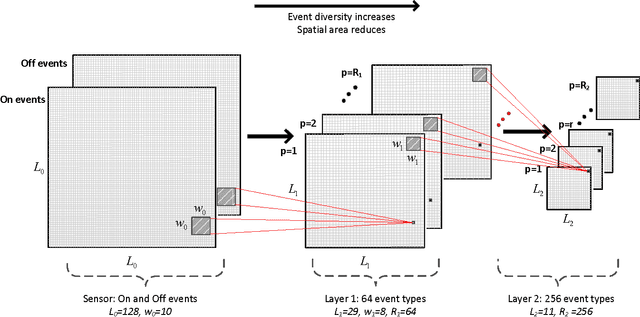

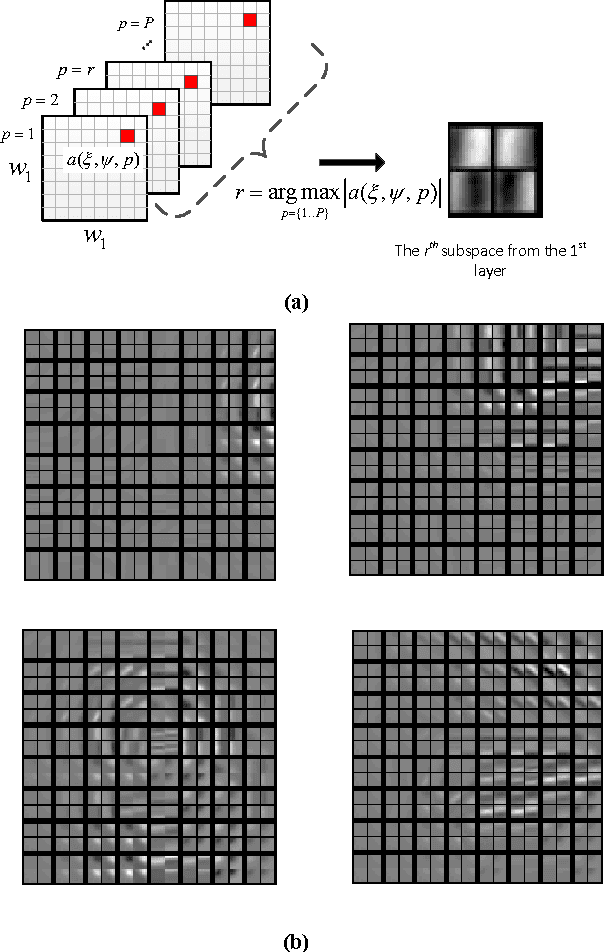
We propose a novel architecture, the event-based GASSOM for learning and extracting invariant representations from event streams originating from neuromorphic vision sensors. The framework is inspired by feed-forward cortical models for visual processing. The model, which is based on the concepts of sparsity and temporal slowness, is able to learn feature extractors that resemble neurons in the primary visual cortex. Layers of units in the proposed model can be cascaded to learn feature extractors with different levels of complexity and selectivity. We explore the applicability of the framework on real world tasks by using the learned network for object recognition. The proposed model achieve higher classification accuracy compared to other state-of-the-art event based processing methods. Our results also demonstrate the generality and robustness of the method, as the recognizers for different data sets and different tasks all used the same set of learned feature detectors, which were trained on data collected independently of the testing data.
Human Action Recognition using Factorized Spatio-Temporal Convolutional Networks
Oct 02, 2015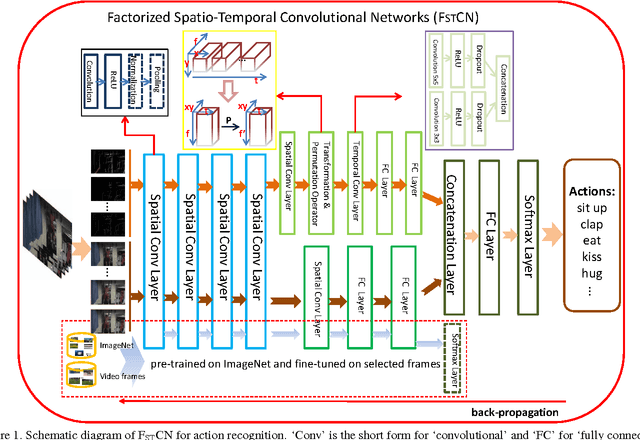

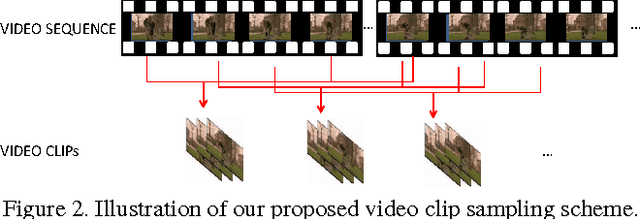
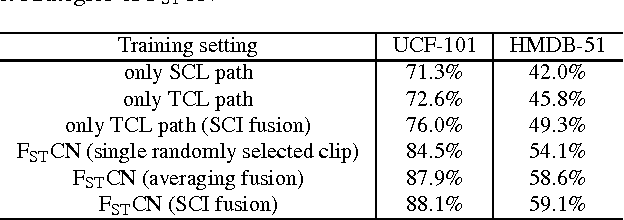
Human actions in video sequences are three-dimensional (3D) spatio-temporal signals characterizing both the visual appearance and motion dynamics of the involved humans and objects. Inspired by the success of convolutional neural networks (CNN) for image classification, recent attempts have been made to learn 3D CNNs for recognizing human actions in videos. However, partly due to the high complexity of training 3D convolution kernels and the need for large quantities of training videos, only limited success has been reported. This has triggered us to investigate in this paper a new deep architecture which can handle 3D signals more effectively. Specifically, we propose factorized spatio-temporal convolutional networks (FstCN) that factorize the original 3D convolution kernel learning as a sequential process of learning 2D spatial kernels in the lower layers (called spatial convolutional layers), followed by learning 1D temporal kernels in the upper layers (called temporal convolutional layers). We introduce a novel transformation and permutation operator to make factorization in FstCN possible. Moreover, to address the issue of sequence alignment, we propose an effective training and inference strategy based on sampling multiple video clips from a given action video sequence. We have tested FstCN on two commonly used benchmark datasets (UCF-101 and HMDB-51). Without using auxiliary training videos to boost the performance, FstCN outperforms existing CNN based methods and achieves comparable performance with a recent method that benefits from using auxiliary training videos.
Intrinsically Motivated Learning of Visual Motion Perception and Smooth Pursuit
Feb 25, 2014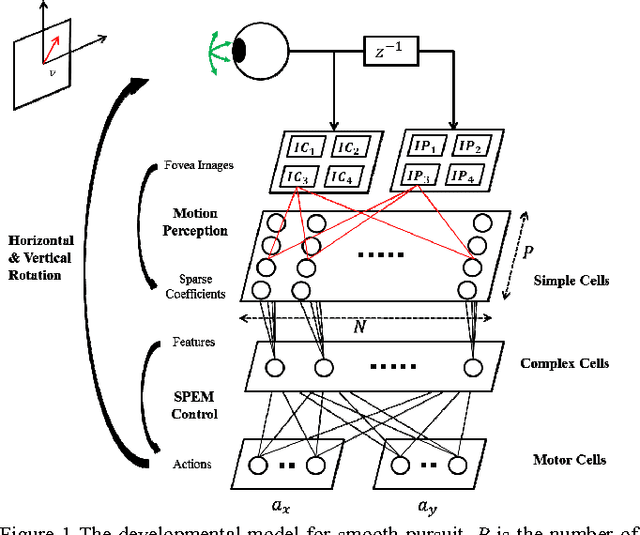
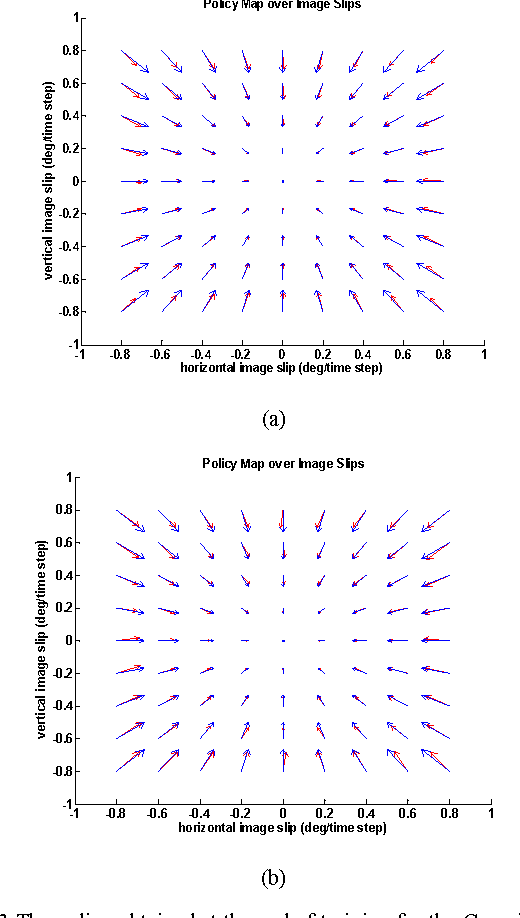
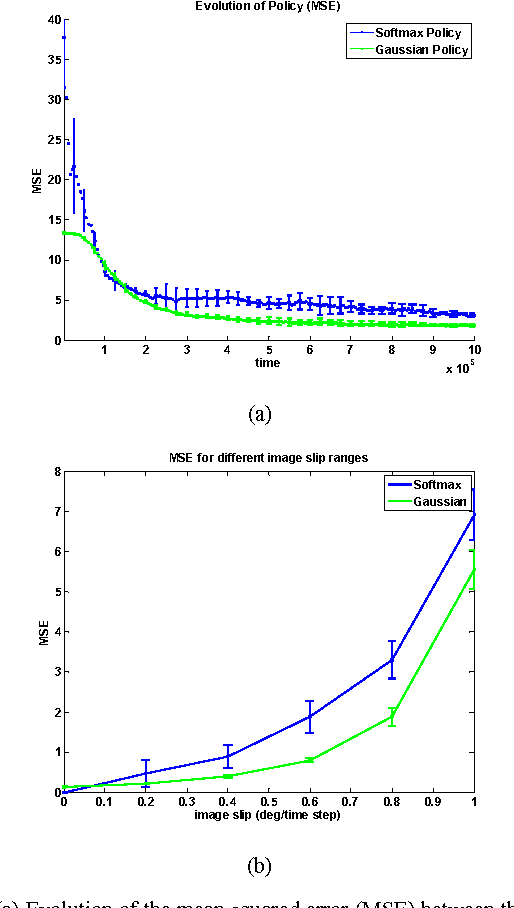
We extend the framework of efficient coding, which has been used to model the development of sensory processing in isolation, to model the development of the perception/action cycle. Our extension combines sparse coding and reinforcement learning so that sensory processing and behavior co-develop to optimize a shared intrinsic motivational signal: the fidelity of the neural encoding of the sensory input under resource constraints. Applying this framework to a model system consisting of an active eye behaving in a time varying environment, we find that this generic principle leads to the simultaneous development of both smooth pursuit behavior and model neurons whose properties are similar to those of primary visual cortical neurons selective for different directions of visual motion. We suggest that this general principle may form the basis for a unified and integrated explanation of many perception/action loops.