 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTR-A: 1st Place Solution for 2022 Waymo Open Dataset Challenge -- Motion Prediction
Sep 20, 2022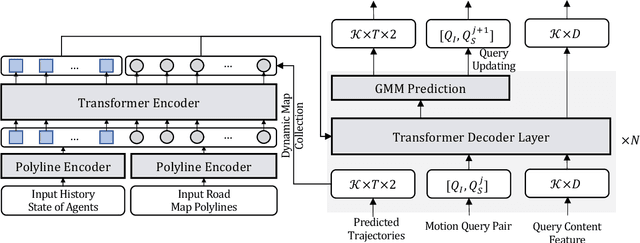
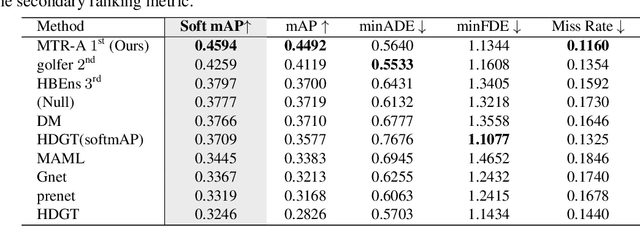
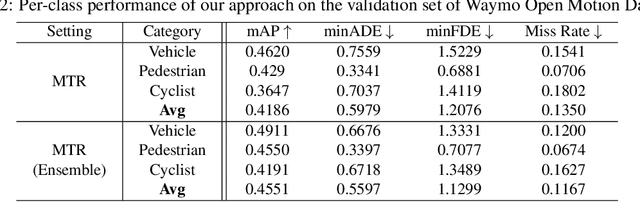
In this report, we present the 1st place solution for motion prediction track in 2022 Waymo Open Dataset Challenges. We propose a novel Motion Transformer framework for multimodal motion prediction, which introduces a small set of novel motion query pairs for generating better multimodal future trajectories by jointly performing the intention localization and iterative motion refinement. A simple model ensemble strategy with non-maximum-suppression is adopted to further boost the final performance. Our approach achieves the 1st place on the motion prediction leaderboard of 2022 Waymo Open Dataset Challenges, outperforming other methods with remarkable margins. Code will be available at https://github.com/sshaoshuai/MTR.
ComplETR: Reducing the cost of annotations for object detection in dense scenes with vision transformers
Sep 13, 2022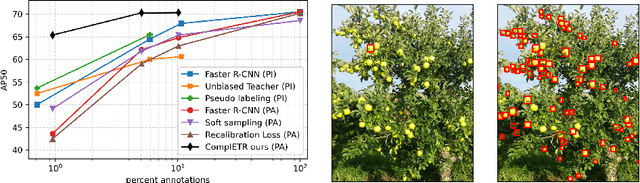
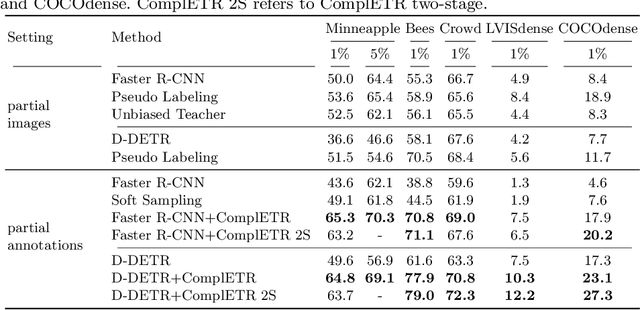
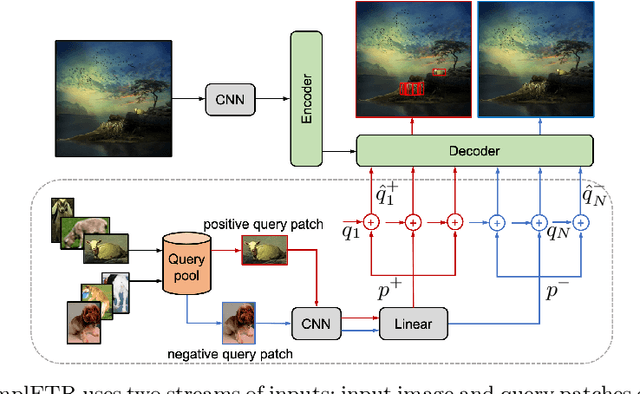
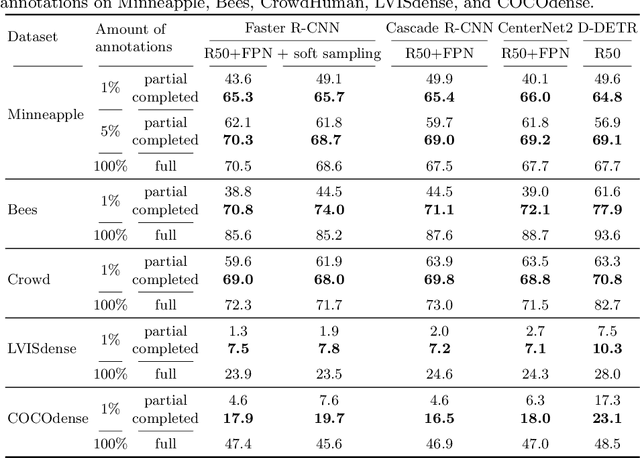
Annotating bounding boxes for object detection is expensive, time-consuming, and error-prone. In this work, we propose a DETR based framework called ComplETR that is designed to explicitly complete missing annotations in partially annotated dense scene datasets. This reduces the need to annotate every object instance in the scene thereby reducing annotation cost. ComplETR augments object queries in DETR decoder with patch information of objects in the image. Combined with a matching loss, it can effectively find objects that are similar to the input patch and complete the missing annotations. We show that our framework outperforms the state-of-the-art methods such as Soft Sampling and Unbiased Teacher by itself, while at the same time can be used in conjunction with these methods to further improve their performance. Our framework is also agnostic to the choice of the downstream object detectors; we show performance improvement for several popular detectors such as Faster R-CNN, Cascade R-CNN, CenterNet2, and Deformable DETR on multiple dense scene datasets.
MoCapDeform: Monocular 3D Human Motion Capture in Deformable Scenes
Aug 17, 2022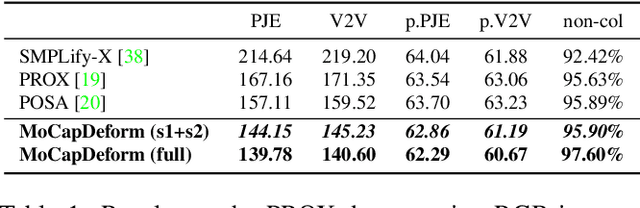
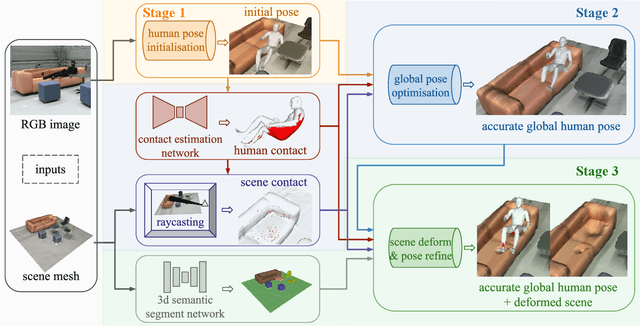
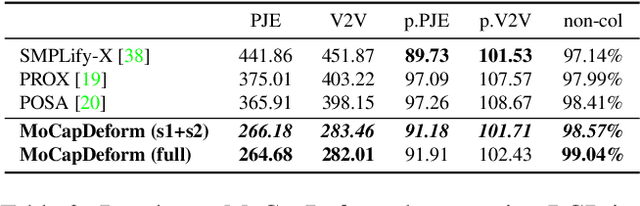
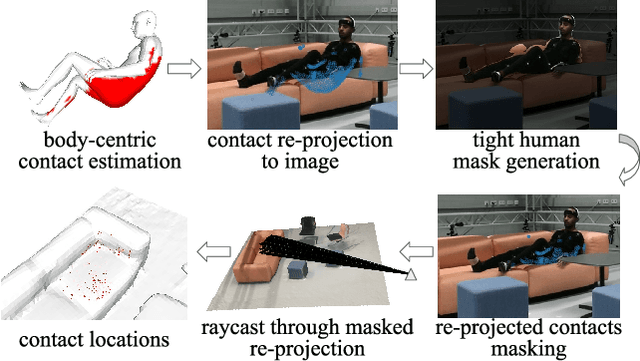
3D human motion capture from monocular RGB images respecting interactions of a subject with complex and possibly deformable environments is a very challenging, ill-posed and under-explored problem. Existing methods address it only weakly and do not model possible surface deformations often occurring when humans interact with scene surfaces. In contrast, this paper proposes MoCapDeform, i.e., a new framework for monocular 3D human motion capture that is the first to explicitly model non-rigid deformations of a 3D scene for improved 3D human pose estimation and deformable environment reconstruction. MoCapDeform accepts a monocular RGB video and a 3D scene mesh aligned in the camera space. It first localises a subject in the input monocular video along with dense contact labels using a new raycasting based strategy. Next, our human-environment interaction constraints are leveraged to jointly optimise global 3D human poses and non-rigid surface deformations. MoCapDeform achieves superior accuracy than competing methods on several datasets, including our newly recorded one with deforming background scenes.
* 11 pages, 8 figures, 3 tables; project page: https://4dqv.mpi-inf.mpg.de/MoCapDeform/
USB: A Unified Semi-supervised Learning Benchmark
Aug 12, 2022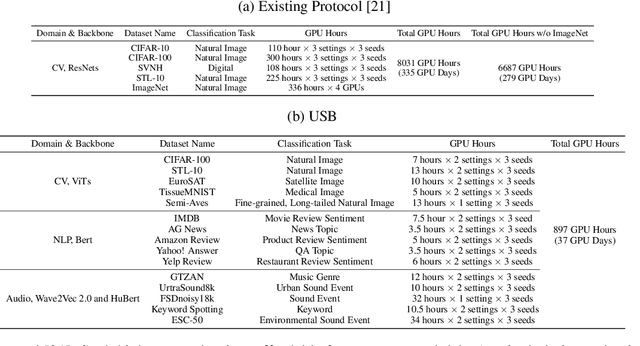
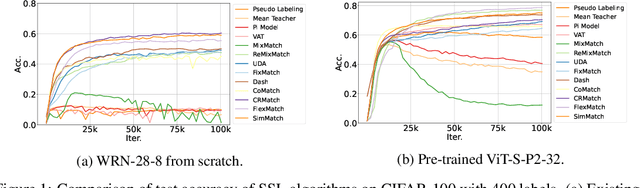
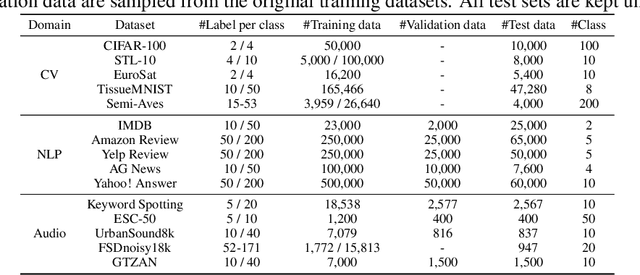
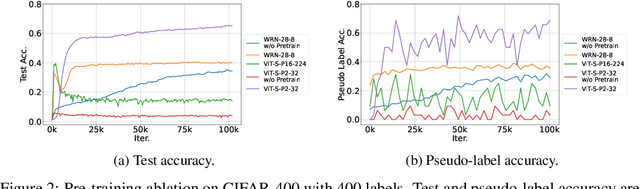
Semi-supervised learning (SSL) improves model generalization by leveraging massive unlabeled data to augment limited labeled samples. However, currently, popular SSL evaluation protocols are often constrained to computer vision (CV) tasks. In addition, previous work typically trains deep neural networks from scratch, which is time-consuming and environmentally unfriendly. To address the above issues, we construct a Unified SSL Benchmark (USB) by selecting 15 diverse, challenging, and comprehensive tasks from CV, natural language processing (NLP), and audio processing (Audio), on which we systematically evaluate dominant SSL methods, and also open-source a modular and extensible codebase for fair evaluation on these SSL methods. We further provide pre-trained versions of the state-of-the-art neural models for CV tasks to make the cost affordable for further tuning. USB enables the evaluation of a single SSL algorithm on more tasks from multiple domains but with less cost. Specifically, on a single NVIDIA V100, only 37 GPU days are required to evaluate FixMatch on 15 tasks in USB while 335 GPU days (279 GPU days on 4 CV datasets except for ImageNet) are needed on 5 CV tasks with the typical protocol.
Assaying Out-Of-Distribution Generalization in Transfer Learning
Jul 19, 2022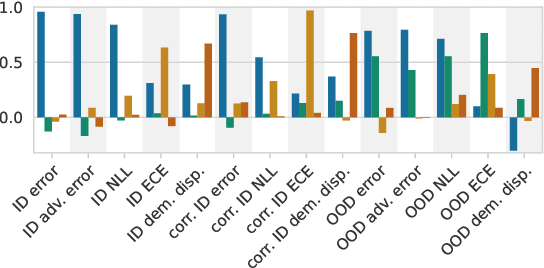
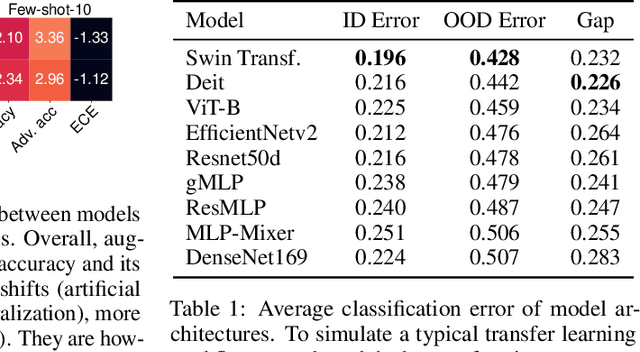
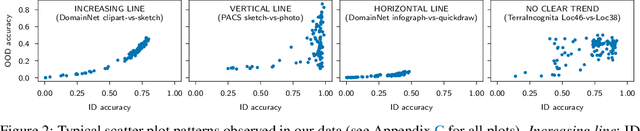
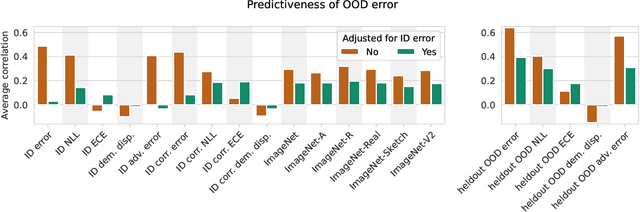
Since out-of-distribution generalization is a generally ill-posed problem, various proxy targets (e.g., calibration, adversarial robustness, algorithmic corruptions, invariance across shifts) were studied across different research programs resulting in different recommendations. While sharing the same aspirational goal, these approaches have never been tested under the same experimental conditions on real data. In this paper, we take a unified view of previous work, highlighting message discrepancies that we address empirically, and providing recommendations on how to measure the robustness of a model and how to improve it. To this end, we collect 172 publicly available dataset pairs for training and out-of-distribution evaluation of accuracy, calibration error, adversarial attacks, environment invariance, and synthetic corruptions. We fine-tune over 31k networks, from nine different architectures in the many- and few-shot setting. Our findings confirm that in- and out-of-distribution accuracies tend to increase jointly, but show that their relation is largely dataset-dependent, and in general more nuanced and more complex than posited by previous, smaller scale studies.
SHIFT: A Synthetic Driving Dataset for Continuous Multi-Task Domain Adaptation
Jun 16, 2022
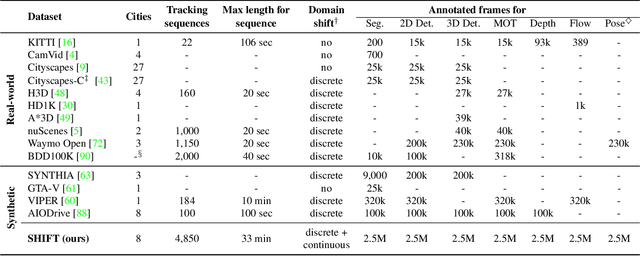
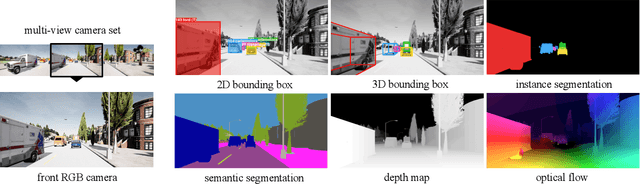

Adapting to a continuously evolving environment is a safety-critical challenge inevitably faced by all autonomous driving systems. Existing image and video driving datasets, however, fall short of capturing the mutable nature of the real world. In this paper, we introduce the largest multi-task synthetic dataset for autonomous driving, SHIFT. It presents discrete and continuous shifts in cloudiness, rain and fog intensity, time of day, and vehicle and pedestrian density. Featuring a comprehensive sensor suite and annotations for several mainstream perception tasks, SHIFT allows investigating the degradation of a perception system performance at increasing levels of domain shift, fostering the development of continuous adaptation strategies to mitigate this problem and assess model robustness and generality. Our dataset and benchmark toolkit are publicly available at www.vis.xyz/shift.
Towards Better Understanding Attribution Methods
May 20, 2022
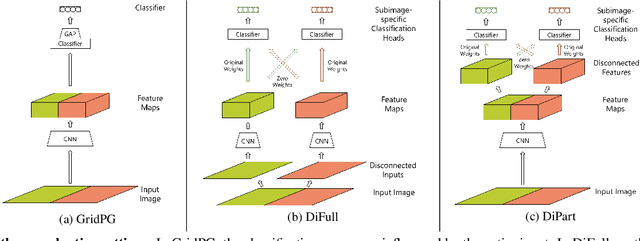

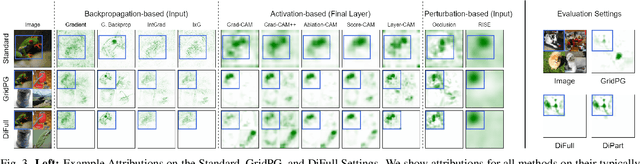
Deep neural networks are very successful on many vision tasks, but hard to interpret due to their black box nature. To overcome this, various post-hoc attribution methods have been proposed to identify image regions most influential to the models' decisions. Evaluating such methods is challenging since no ground truth attributions exist. We thus propose three novel evaluation schemes to more reliably measure the faithfulness of those methods, to make comparisons between them more fair, and to make visual inspection more systematic. To address faithfulness, we propose a novel evaluation setting (DiFull) in which we carefully control which parts of the input can influence the output in order to distinguish possible from impossible attributions. To address fairness, we note that different methods are applied at different layers, which skews any comparison, and so evaluate all methods on the same layers (ML-Att) and discuss how this impacts their performance on quantitative metrics. For more systematic visualizations, we propose a scheme (AggAtt) to qualitatively evaluate the methods on complete datasets. We use these evaluation schemes to study strengths and shortcomings of some widely used attribution methods. Finally, we propose a post-processing smoothing step that significantly improves the performance of some attribution methods, and discuss its applicability.
B-cos Networks: Alignment is All We Need for Interpretability
May 20, 2022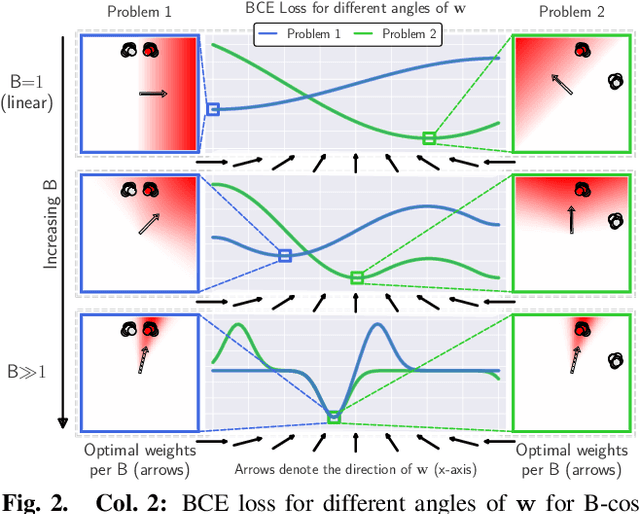
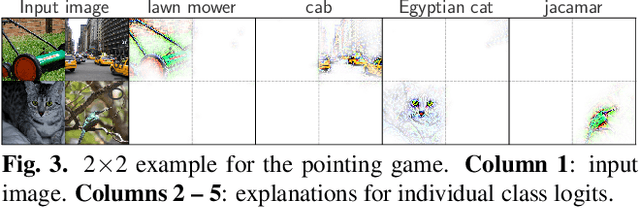
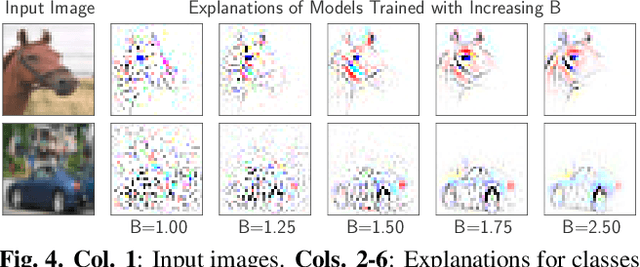
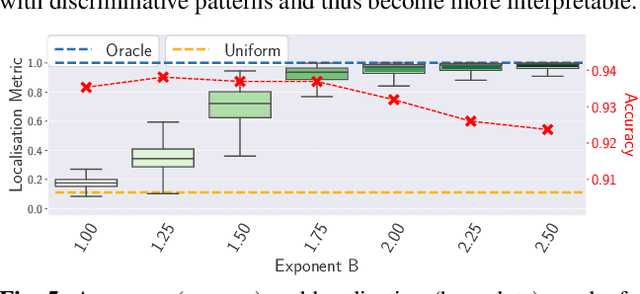
We present a new direction for increasing the interpretability of deep neural networks (DNNs) by promoting weight-input alignment during training. For this, we propose to replace the linear transforms in DNNs by our B-cos transform. As we show, a sequence (network) of such transforms induces a single linear transform that faithfully summarises the full model computations. Moreover, the B-cos transform introduces alignment pressure on the weights during optimisation. As a result, those induced linear transforms become highly interpretable and align with task-relevant features. Importantly, the B-cos transform is designed to be compatible with existing architectures and we show that it can easily be integrated into common models such as VGGs, ResNets, InceptionNets, and DenseNets, whilst maintaining similar performance on ImageNet. The resulting explanations are of high visual quality and perform well under quantitative metrics for interpretability. Code available at https://www.github.com/moboehle/B-cos.
ELODI: Ensemble Logit Difference Inhibition for Positive-Congruent Training
May 13, 2022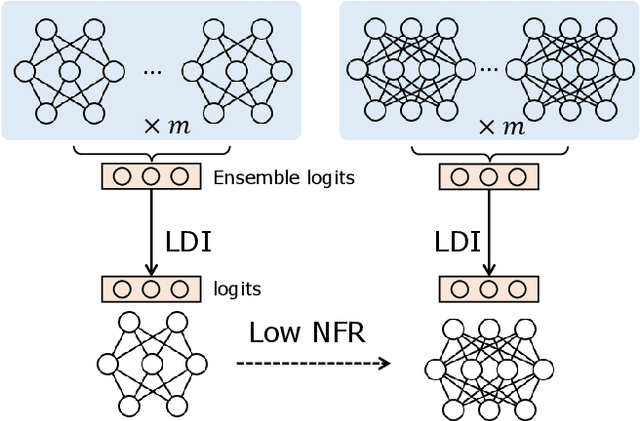
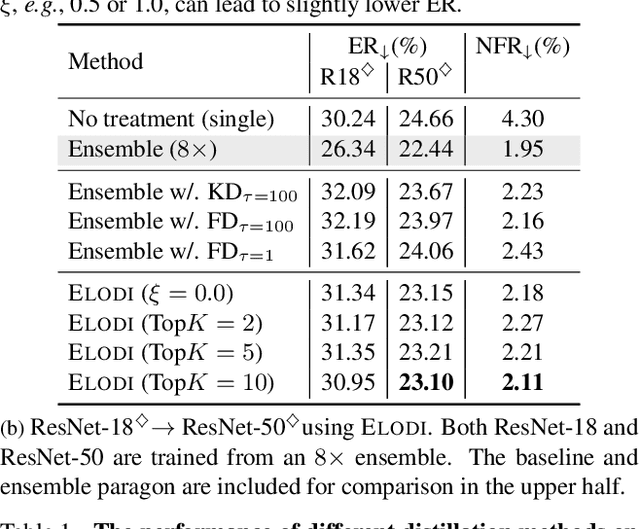
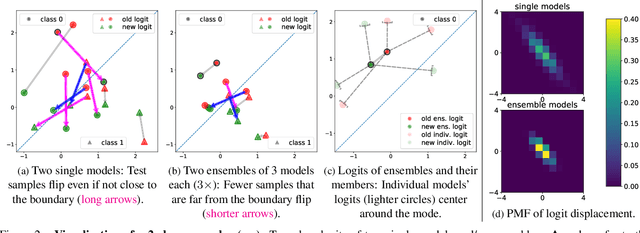
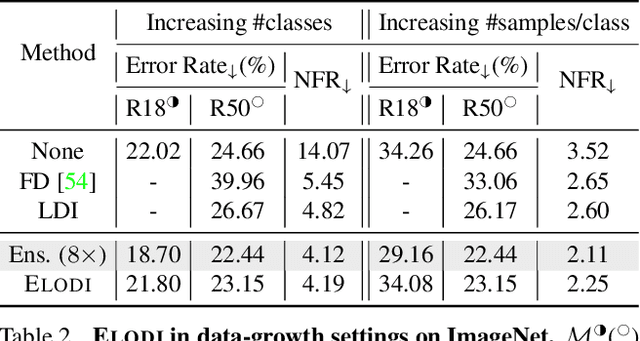
Negative flips are errors introduced in a classification system when a legacy model is replaced with a new one. Existing methods to reduce the negative flip rate (NFR) either do so at the expense of overall accuracy using model distillation, or use ensembles, which multiply inference cost prohibitively. We present a method to train a classification system that achieves paragon performance in both error rate and NFR, at the inference cost of a single model. Our method introduces a generalized distillation objective, Logit Difference Inhibition (LDI), that penalizes changes in the logits between the new and old model, without forcing them to coincide as in ordinary distillation. LDI affords the model flexibility to reduce error rate along with NFR. The method uses a homogeneous ensemble as the reference model for LDI, hence the name Ensemble LDI, or ELODI. The reference model can then be substituted with a single model at inference time. The method leverages the observation that negative flips are typically not close to the decision boundary, but often exhibit large deviations in the distance among their logits, which are reduced by ELODI.
Bi-level Alignment for Cross-Domain Crowd Counting
May 12, 2022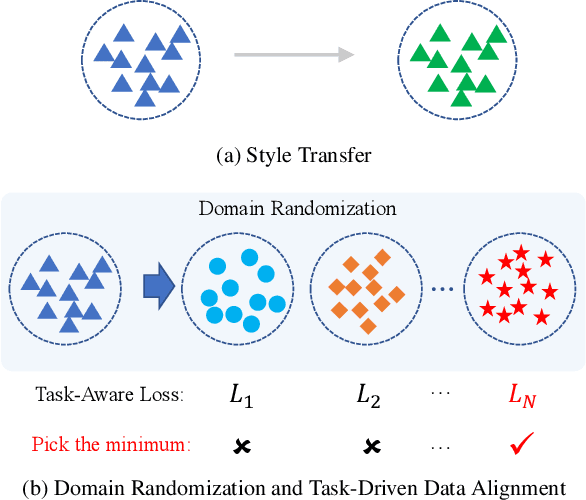

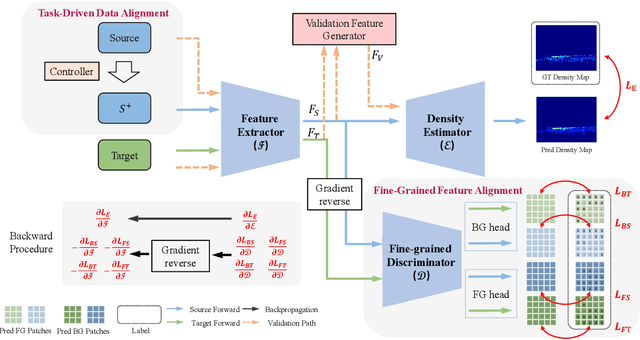
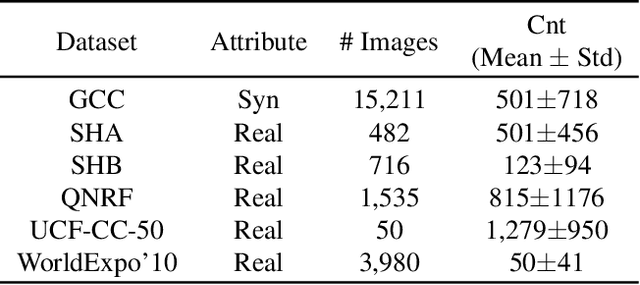
Recently, crowd density estimation has received increasing attention. The main challenge for this task is to achieve high-quality manual annotations on a large amount of training data. To avoid reliance on such annotations, previous works apply unsupervised domain adaptation (UDA) techniques by transferring knowledge learned from easily accessible synthetic data to real-world datasets. However, current state-of-the-art methods either rely on external data for training an auxiliary task or apply an expensive coarse-to-fine estimation. In this work, we aim to develop a new adversarial learning based method, which is simple and efficient to apply. To reduce the domain gap between the synthetic and real data, we design a bi-level alignment framework (BLA) consisting of (1) task-driven data alignment and (2) fine-grained feature alignment. In contrast to previous domain augmentation methods, we introduce AutoML to search for an optimal transform on source, which well serves for the downstream task. On the other hand, we do fine-grained alignment for foreground and background separately to alleviate the alignment difficulty. We evaluate our approach on five real-world crowd counting benchmarks, where we outperform existing approaches by a large margin. Also, our approach is simple, easy to implement and efficient to apply. The code is publicly available at https://github.com/Yankeegsj/BLA.