 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Free Spatial Attention Network for Person Re-Identification
Nov 29, 2018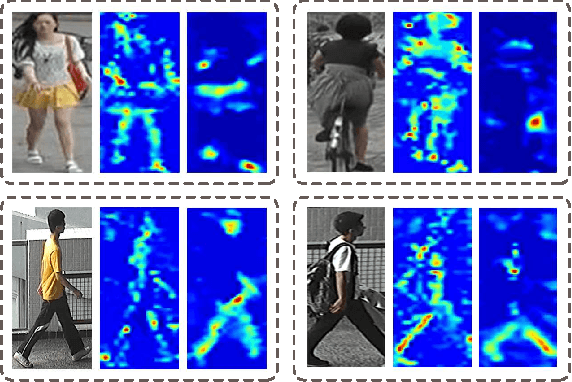
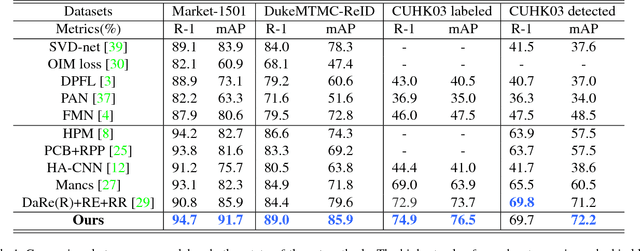
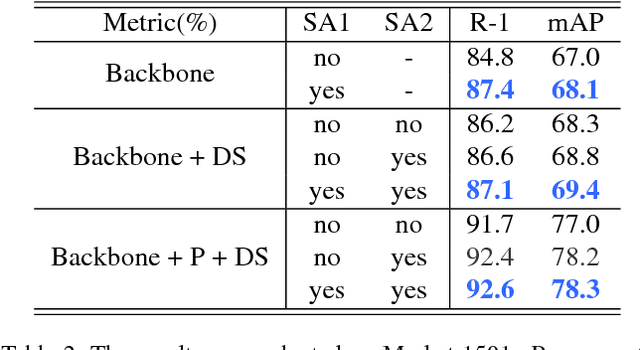
Global average pooling (GAP) allows to localize discriminative information for recognition [40]. While GAP helps the convolution neural network to attend to the most discriminative features of an object, it may suffer if that information is missing e.g. due to camera viewpoint changes. To circumvent this issue, we argue that it is advantageous to attend to the global configuration of the object by modeling spatial relations among high-level features. We propose a novel architecture for Person Re-Identification, based on a novel parameter-free spatial attention layer introducing spatial relations among the feature map activations back to the model. Our spatial attention layer consistently improves the performance over the model without it. Results on four benchmarks demonstrate a superiority of our model over the state-of-the-art achieving rank-1 accuracy of 94.7% on Market-1501, 89.0% on DukeMTMC-ReID, 74.9% on CUHK03-labeled and 69.7% on CUHK03-detected.
Person Recognition in Personal Photo Collections
Oct 20, 2018



People nowadays share large parts of their personal lives through social media. Being able to automatically recognise people in personal photos may greatly enhance user convenience by easing photo album organisation. For human identification task, however, traditional focus of computer vision has been face recognition and pedestrian re-identification. Person recognition in social media photos sets new challenges for computer vision, including non-cooperative subjects (e.g. backward viewpoints, unusual poses) and great changes in appearance. To tackle this problem, we build a simple person recognition framework that leverages convnet features from multiple image regions (head, body, etc.). We propose new recognition scenarios that focus on the time and appearance gap between training and testing samples. We present an in-depth analysis of the importance of different features according to time and viewpoint generalisability. In the process, we verify that our simple approach achieves the state of the art result on the PIPA benchmark, arguably the largest social media based benchmark for person recognition to date with diverse poses, viewpoints, social groups, and events. Compared the conference version of the paper, this paper additionally presents (1) analysis of a face recogniser (DeepID2+), (2) new method naeil2 that combines the conference version method naeil and DeepID2+ to achieve state of the art results even compared to post-conference works, (3) discussion of related work since the conference version, (4) additional analysis including the head viewpoint-wise breakdown of performance, and (5) results on the open-world setup.
Accurate and Diverse Sampling of Sequences based on a "Best of Many" Sample Objective
Oct 15, 2018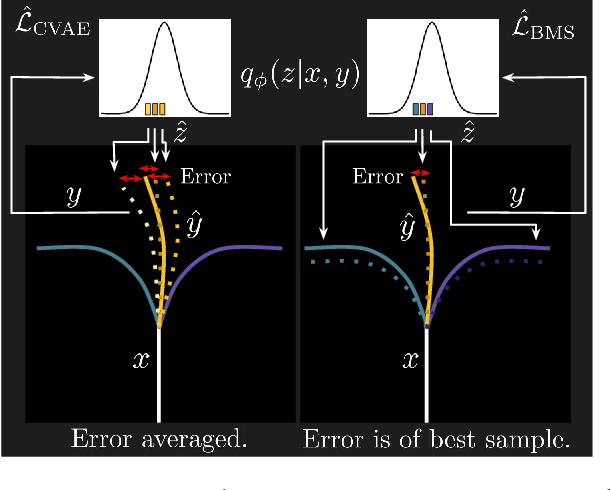


For autonomous agents to successfully operate in the real world, anticipation of future events and states of their environment is a key competence. This problem has been formalized as a sequence extrapolation problem, where a number of observations are used to predict the sequence into the future. Real-world scenarios demand a model of uncertainty of such predictions, as predictions become increasingly uncertain -- in particular on long time horizons. While impressive results have been shown on point estimates, scenarios that induce multi-modal distributions over future sequences remain challenging. Our work addresses these challenges in a Gaussian Latent Variable model for sequence prediction. Our core contribution is a "Best of Many" sample objective that leads to more accurate and more diverse predictions that better capture the true variations in real-world sequence data. Beyond our analysis of improved model fit, our models also empirically outperform prior work on three diverse tasks ranging from traffic scenes to weather data.
Bayesian Prediction of Future Street Scenes using Synthetic Likelihoods
Oct 02, 2018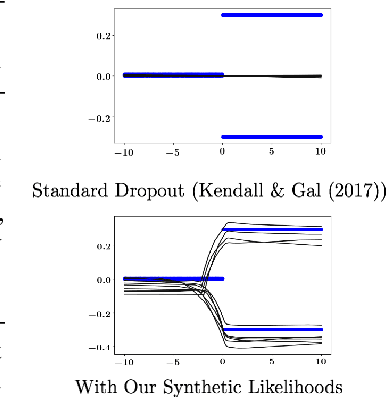

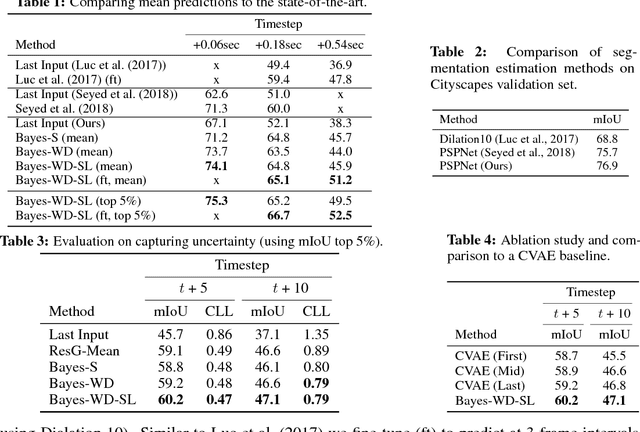
For autonomous agents to successfully operate in the real world, the ability to anticipate future scene states is a key competence. In real-world scenarios, future states become increasingly uncertain and multi-modal, particularly on long time horizons. Dropout based Bayesian inference provides a computationally tractable, theoretically well grounded approach to learn likely hypotheses/models to deal with uncertain futures and make predictions that correspond well to observations -- are well calibrated. However, it turns out that such approaches fall short to capture complex real-world scenes, even falling behind in accuracy when compared to the plain deterministic approaches. This is because the used log-likelihood estimate discourages diversity. In this work, we propose a novel Bayesian formulation for anticipating future scene states which leverages synthetic likelihoods that encourage the learning of diverse models to accurately capture the multi-modal nature of future scene states. We show that our approach achieves accurate state-of-the-art predictions and calibrated probabilities through extensive experiments for scene anticipation on Cityscapes dataset. Moreover, we show that our approach generalizes across diverse tasks such as digit generation and precipitation forecasting.
Bayesian Prediction of Future Street Scenes through Importance Sampling based Optimization
Sep 28, 2018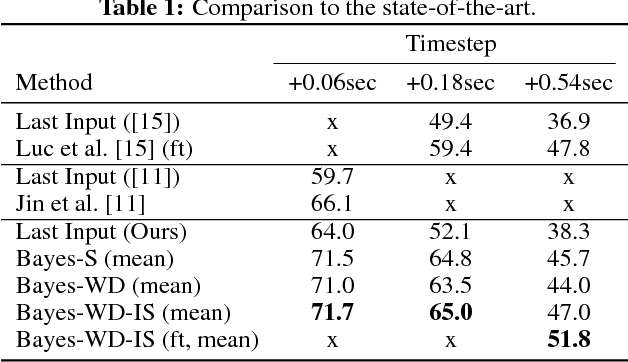
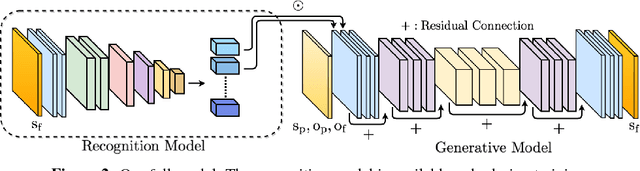
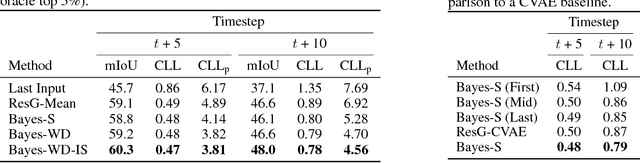
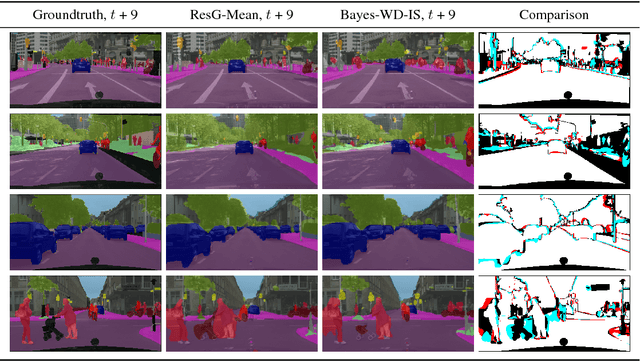
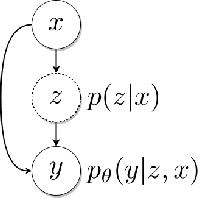
For autonomous agents to successfully operate in the real world, anticipation of future events and states of their environment is a key competence. This problem can be formalized as a sequence prediction problem, where a number of observations are used to predict the sequence into the future. However, real-world scenarios demand a model of uncertainty of such predictions, as future states become increasingly uncertain and multi-modal -- in particular on long time horizons. This makes modelling and learning challenging. We cast state of the art semantic segmentation and future prediction models based on deep learning into a Bayesian formulation that in turn allows for a full Bayesian treatment of the prediction problem. We present a new sampling scheme for this model that draws from the success of variational autoencoders by incorporating a recognition network. In the experiments we show that our model outperforms prior work in accuracy of the predicted segmentation and provides calibrated probabilities that also better capture the multi-modal aspects of possible future states of street scenes.
Neural Body Fitting: Unifying Deep Learning and Model-Based Human Pose and Shape Estimation
Aug 17, 2018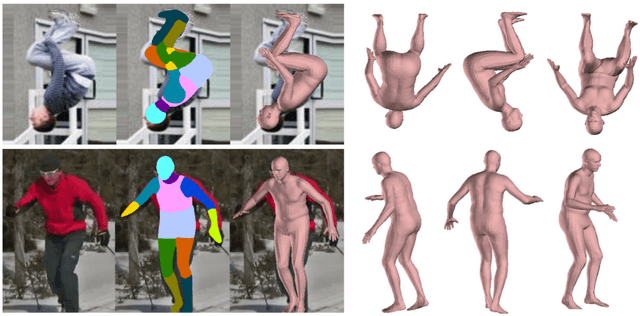
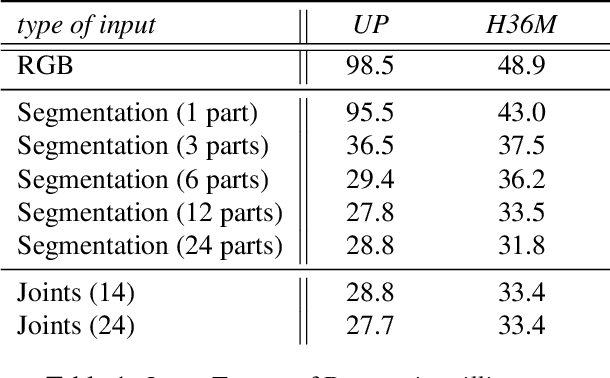
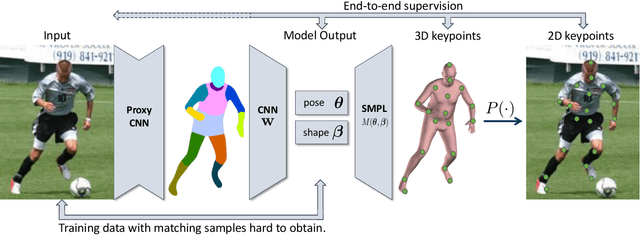
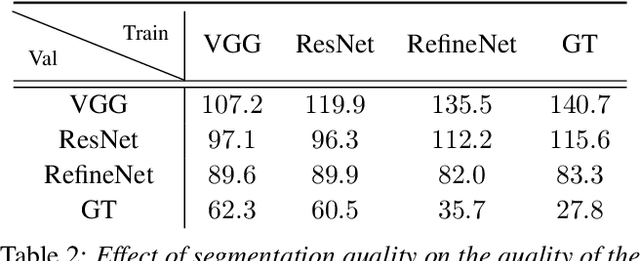
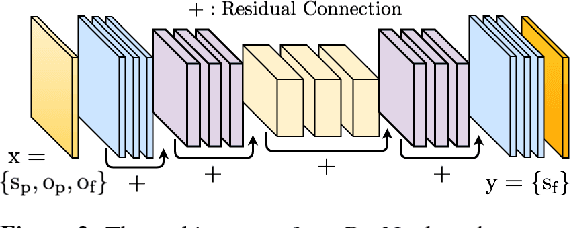
Direct prediction of 3D body pose and shape remains a challenge even for highly parameterized deep learning models. Mapping from the 2D image space to the prediction space is difficult: perspective ambiguities make the loss function noisy and training data is scarce. In this paper, we propose a novel approach (Neural Body Fitting (NBF)). It integrates a statistical body model within a CNN, leveraging reliable bottom-up semantic body part segmentation and robust top-down body model constraints. NBF is fully differentiable and can be trained using 2D and 3D annotations. In detailed experiments, we analyze how the components of our model affect performance, especially the use of part segmentations as an explicit intermediate representation, and present a robust, efficiently trainable framework for 3D human pose estimation from 2D images with competitive results on standard benchmarks. Code will be made available at http://github.com/mohomran/neural_body_fitting
Zero-Shot Learning - A Comprehensive Evaluation of the Good, the Bad and the Ugly
Aug 09, 2018
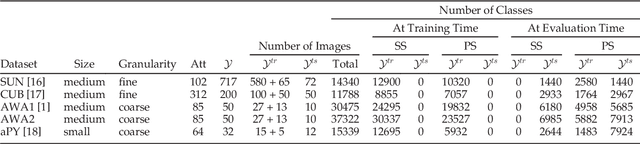
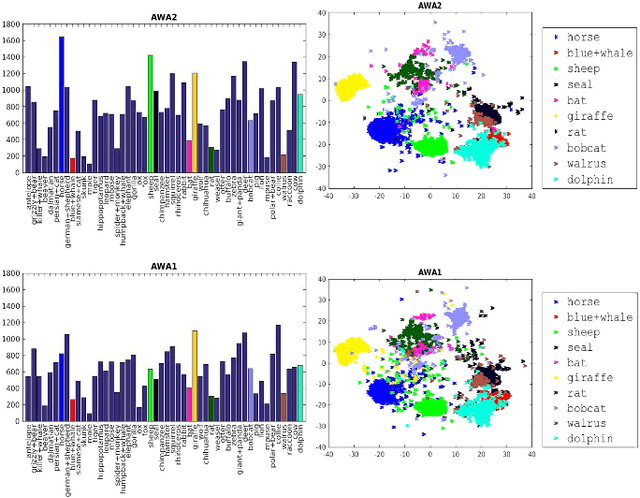
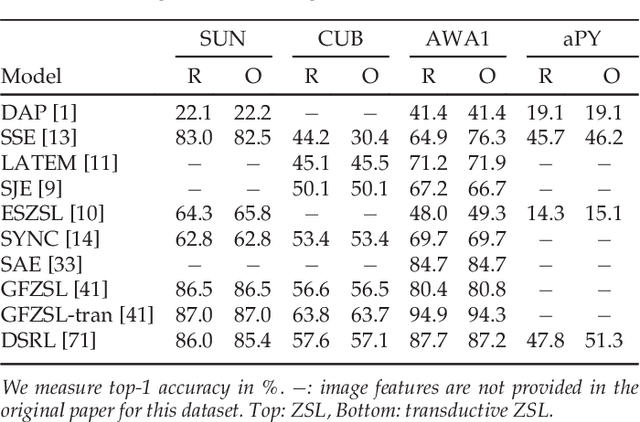
Due to the importance of zero-shot learning, i.e. classifying images where there is a lack of labeled training data, the number of proposed approaches has recently increased steadily. We argue that it is time to take a step back and to analyze the status quo of the area. The purpose of this paper is three-fold. First, given the fact that there is no agreed upon zero-shot learning benchmark, we first define a new benchmark by unifying both the evaluation protocols and data splits of publicly available datasets used for this task. This is an important contribution as published results are often not comparable and sometimes even flawed due to, e.g. pre-training on zero-shot test classes. Moreover, we propose a new zero-shot learning dataset, the Animals with Attributes 2 (AWA2) dataset which we make publicly available both in terms of image features and the images themselves. Second, we compare and analyze a significant number of the state-of-the-art methods in depth, both in the classic zero-shot setting but also in the more realistic generalized zero-shot setting. Finally, we discuss in detail the limitations of the current status of the area which can be taken as a basis for advancing it.
Diverse Conditional Image Generation by Stochastic Regression with Latent Drop-Out Codes
Aug 03, 2018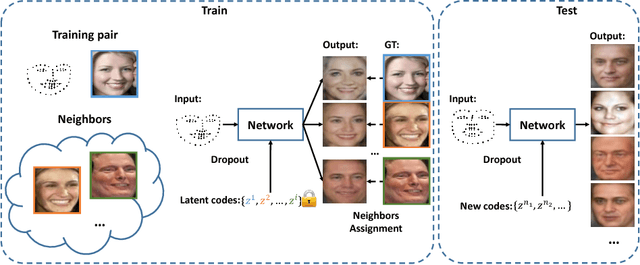
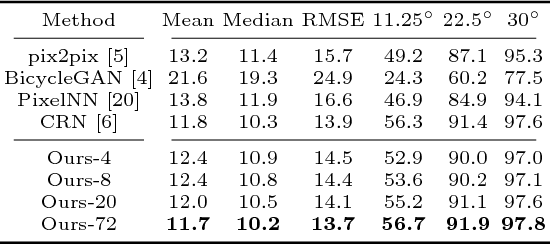
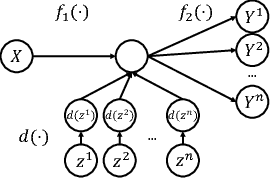
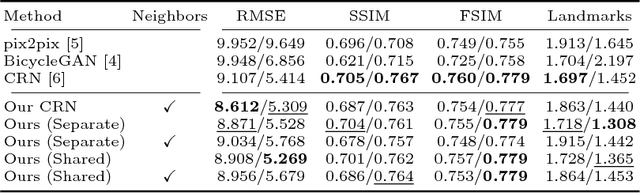
Recent advances in Deep Learning and probabilistic modeling have led to strong improvements in generative models for images. On the one hand, Generative Adversarial Networks (GANs) have contributed a highly effective adversarial learning procedure, but still suffer from stability issues. On the other hand, Conditional Variational Auto-Encoders (CVAE) models provide a sound way of conditional modeling but suffer from mode-mixing issues. Therefore, recent work has turned back to simple and stable regression models that are effective at generation but give up on the sampling mechanism and the latent code representation. We propose a novel and efficient stochastic regression approach with latent drop-out codes that combines the merits of both lines of research. In addition, a new training objective increases coverage of the training distribution leading to improvements over the state of the art in terms of accuracy as well as diversity.
A Hybrid Model for Identity Obfuscation by Face Replacement
Jul 24, 2018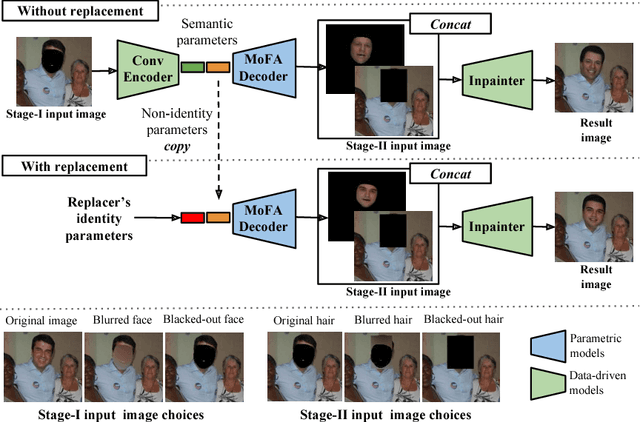
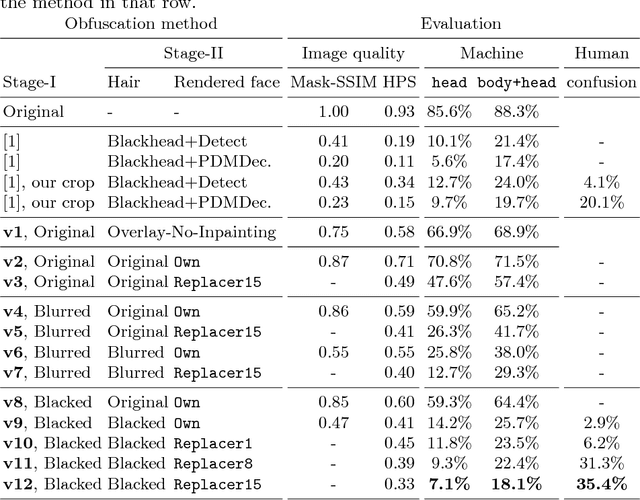
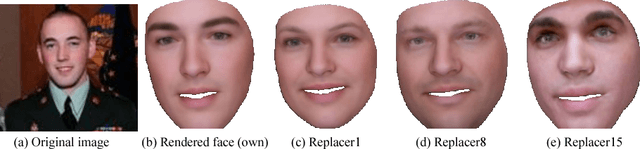
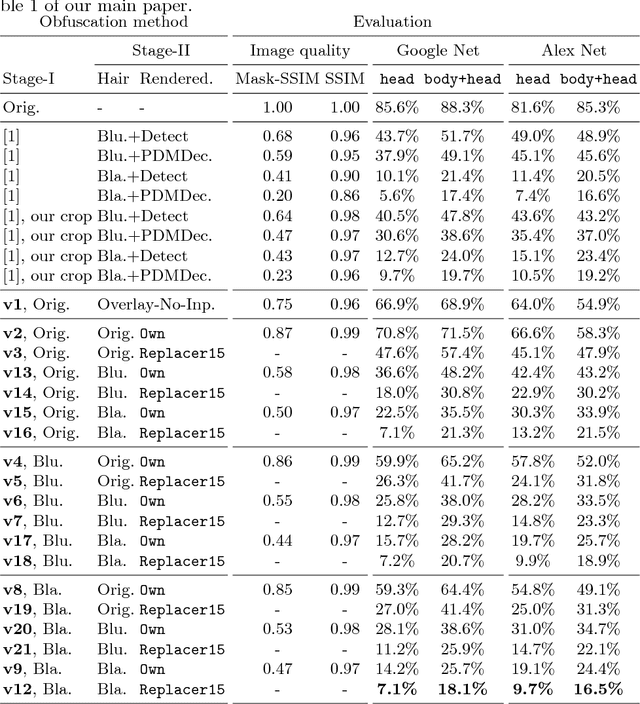
As more and more personal photos are shared and tagged in social media, avoiding privacy risks such as unintended recognition becomes increasingly challenging. We propose a new hybrid approach to obfuscate identities in photos by head replacement. Our approach combines state of the art parametric face synthesis with latest advances in Generative Adversarial Networks (GAN) for data-driven image synthesis. On the one hand, the parametric part of our method gives us control over the facial parameters and allows for explicit manipulation of the identity. On the other hand, the data-driven aspects allow for adding fine details and overall realism as well as seamless blending into the scene context. In our experiments, we show highly realistic output of our system that improves over the previous state of the art in obfuscation rate while preserving a higher similarity to the original image content.
Long-Term On-Board Prediction of People in Traffic Scenes under Uncertainty
Jun 20, 2018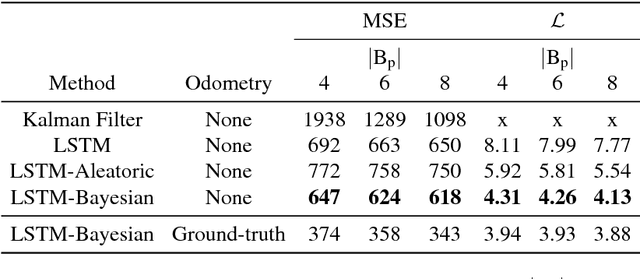
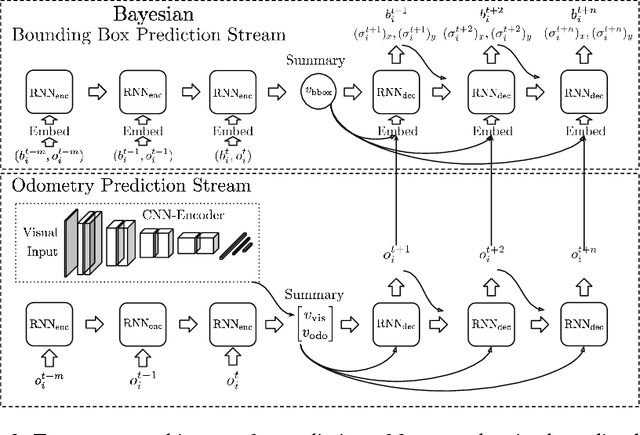

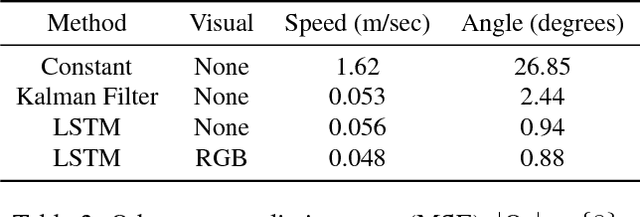
Progress towards advanced systems for assisted and autonomous driving is leveraging recent advances in recognition and segmentation methods. Yet, we are still facing challenges in bringing reliable driving to inner cities, as those are composed of highly dynamic scenes observed from a moving platform at considerable speeds. Anticipation becomes a key element in order to react timely and prevent accidents. In this paper we argue that it is necessary to predict at least 1 second and we thus propose a new model that jointly predicts ego motion and people trajectories over such large time horizons. We pay particular attention to modeling the uncertainty of our estimates arising from the non-deterministic nature of natural traffic scenes. Our experimental results show that it is indeed possible to predict people trajectories at the desired time horizons and that our uncertainty estimates are informative of the prediction error. We also show that both sequence modeling of trajectories as well as our novel method of long term odometry prediction are essential for best performance.