 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWoosh: A Sound Effects Foundation Model
Apr 02, 2026The audio research community depends on open generative models as foundational tools for building novel approaches and establishing baselines. In this report, we present Woosh, Sony AI's publicly released sound effect foundation model, detailing its architecture, training process, and an evaluation against other popular open models. Being optimized for sound effects, we provide (1) a high-quality audio encoder/decoder model and (2) a text-audio alignment model for conditioning, together with (3) text-to-audio and (4) video-to-audio generative models. Distilled text-to-audio and video-to-audio models are also included in the release, allowing for low-resource operation and fast inference. Our evaluation on both public and private data shows competitive or better performance for each module when compared to existing open alternatives like StableAudio-Open and TangoFlux. Inference code and model weights are available at https://github.com/SonyResearch/Woosh. Demo samples can be found at https://sonyresearch.github.io/Woosh/.
HumMusQA: A Human-written Music Understanding QA Benchmark Dataset
Mar 29, 2026The evaluation of music understanding in Large Audio-Language Models (LALMs) requires a rigorously defined benchmark that truly tests whether models can perceive and interpret music, a standard that current data methodologies frequently fail to meet. This paper introduces a meticulously structured approach to music evaluation, proposing a new dataset of 320 hand-written questions curated and validated by experts with musical training, arguing that such focused, manual curation is superior for probing complex audio comprehension. To demonstrate the use of the dataset, we benchmark six state-of-the-art LALMs and additionally test their robustness to uni-modal shortcuts.
* Dataset available at https://doi.org/10.5281/zenodo.18462523
CrossMuSim: A Cross-Modal Framework for Music Similarity Retrieval with LLM-Powered Text Description Sourcing and Mining
Mar 29, 2025Music similarity retrieval is fundamental for managing and exploring relevant content from large collections in streaming platforms. This paper presents a novel cross-modal contrastive learning framework that leverages the open-ended nature of text descriptions to guide music similarity modeling, addressing the limitations of traditional uni-modal approaches in capturing complex musical relationships. To overcome the scarcity of high-quality text-music paired data, this paper introduces a dual-source data acquisition approach combining online scraping and LLM-based prompting, where carefully designed prompts leverage LLMs' comprehensive music knowledge to generate contextually rich descriptions. Exten1sive experiments demonstrate that the proposed framework achieves significant performance improvements over existing benchmarks through objective metrics, subjective evaluations, and real-world A/B testing on the Huawei Music streaming platform.
The language of sound search: Examining User Queries in Audio Search Engines
Oct 10, 2024



This study examines textual, user-written search queries within the context of sound search engines, encompassing various applications such as foley, sound effects, and general audio retrieval. Current research inadequately addresses real-world user needs and behaviours in designing text-based audio retrieval systems. To bridge this gap, we analysed search queries from two sources: a custom survey and Freesound website query logs. The survey was designed to collect queries for an unrestricted, hypothetical sound search engine, resulting in a dataset that captures user intentions without the constraints of existing systems. This dataset is also made available for sharing with the research community. In contrast, the Freesound query logs encompass approximately 9 million search requests, providing a comprehensive view of real-world usage patterns. Our findings indicate that survey queries are generally longer than Freesound queries, suggesting users prefer detailed queries when not limited by system constraints. Both datasets predominantly feature keyword-based queries, with few survey participants using full sentences. Key factors influencing survey queries include the primary sound source, intended usage, perceived location, and the number of sound sources. These insights are crucial for developing user-centred, effective text-based audio retrieval systems, enhancing our understanding of user behaviour in sound search contexts.
The Role of Large Language Models in Musicology: Are We Ready to Trust the Machines?
Sep 03, 2024



In this work, we explore the use and reliability of Large Language Models (LLMs) in musicology. From a discussion with experts and students, we assess the current acceptance and concerns regarding this, nowadays ubiquitous, technology. We aim to go one step further, proposing a semi-automatic method to create an initial benchmark using retrieval-augmented generation models and multiple-choice question generation, validated by human experts. Our evaluation on 400 human-validated questions shows that current vanilla LLMs are less reliable than retrieval augmented generation from music dictionaries. This paper suggests that the potential of LLMs in musicology requires musicology driven research that can specialized LLMs by including accurate and reliable domain knowledge.
MuChoMusic: Evaluating Music Understanding in Multimodal Audio-Language Models
Aug 02, 2024



Multimodal models that jointly process audio and language hold great promise in audio understanding and are increasingly being adopted in the music domain. By allowing users to query via text and obtain information about a given audio input, these models have the potential to enable a variety of music understanding tasks via language-based interfaces. However, their evaluation poses considerable challenges, and it remains unclear how to effectively assess their ability to correctly interpret music-related inputs with current methods. Motivated by this, we introduce MuChoMusic, a benchmark for evaluating music understanding in multimodal language models focused on audio. MuChoMusic comprises 1,187 multiple-choice questions, all validated by human annotators, on 644 music tracks sourced from two publicly available music datasets, and covering a wide variety of genres. Questions in the benchmark are crafted to assess knowledge and reasoning abilities across several dimensions that cover fundamental musical concepts and their relation to cultural and functional contexts. Through the holistic analysis afforded by the benchmark, we evaluate five open-source models and identify several pitfalls, including an over-reliance on the language modality, pointing to a need for better multimodal integration. Data and code are open-sourced.
WikiMuTe: A web-sourced dataset of semantic descriptions for music audio
Dec 14, 2023Multi-modal deep learning techniques for matching free-form text with music have shown promising results in the field of Music Information Retrieval (MIR). Prior work is often based on large proprietary data while publicly available datasets are few and small in size. In this study, we present WikiMuTe, a new and open dataset containing rich semantic descriptions of music. The data is sourced from Wikipedia's rich catalogue of articles covering musical works. Using a dedicated text-mining pipeline, we extract both long and short-form descriptions covering a wide range of topics related to music content such as genre, style, mood, instrumentation, and tempo. To show the use of this data, we train a model that jointly learns text and audio representations and performs cross-modal retrieval. The model is evaluated on two tasks: tag-based music retrieval and music auto-tagging. The results show that while our approach has state-of-the-art performance on multiple tasks, but still observe a difference in performance depending on the data used for training.
The Song Describer Dataset: a Corpus of Audio Captions for Music-and-Language Evaluation
Nov 22, 2023



We introduce the Song Describer dataset (SDD), a new crowdsourced corpus of high-quality audio-caption pairs, designed for the evaluation of music-and-language models. The dataset consists of 1.1k human-written natural language descriptions of 706 music recordings, all publicly accessible and released under Creative Common licenses. To showcase the use of our dataset, we benchmark popular models on three key music-and-language tasks (music captioning, text-to-music generation and music-language retrieval). Our experiments highlight the importance of cross-dataset evaluation and offer insights into how researchers can use SDD to gain a broader understanding of model performance.
Data leakage in cross-modal retrieval training: A case study
Feb 23, 2023


The recent progress in text-based audio retrieval was largely propelled by the release of suitable datasets. Since the manual creation of such datasets is a laborious task, obtaining data from online resources can be a cheap solution to create large-scale datasets. We study the recently proposed SoundDesc benchmark dataset, which was automatically sourced from the BBC Sound Effects web page. In our analysis, we find that SoundDesc contains several duplicates that cause leakage of training data to the evaluation data. This data leakage ultimately leads to overly optimistic retrieval performance estimates in previous benchmarks. We propose new training, validation, and testing splits for the dataset that we make available online. To avoid weak contamination of the test data, we pool audio files that share similar recording setups. In our experiments, we find that the new splits serve as a more challenging benchmark.
Matching Text and Audio Embeddings: Exploring Transfer-learning Strategies for Language-based Audio Retrieval
Oct 06, 2022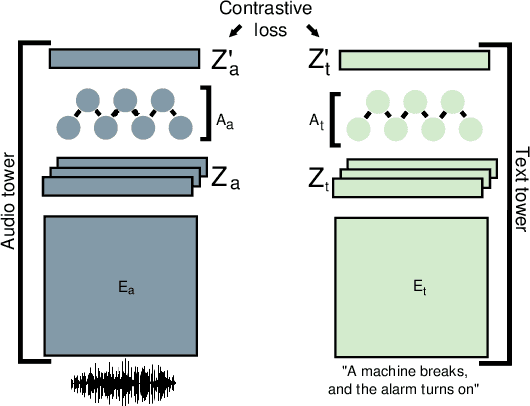

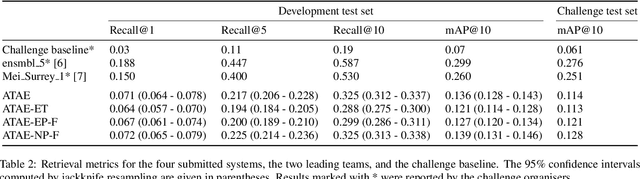
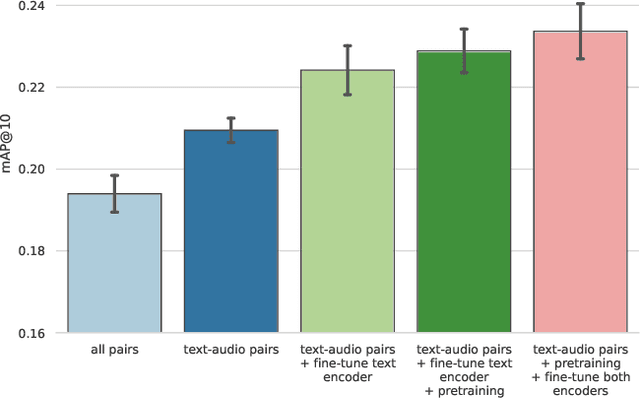
We present an analysis of large-scale pretrained deep learning models used for cross-modal (text-to-audio) retrieval. We use embeddings extracted by these models in a metric learning framework to connect matching pairs of audio and text. Shallow neural networks map the embeddings to a common dimensionality. Our system, which is an extension of our submission to the Language-based Audio Retrieval Task of the DCASE Challenge 2022, employs the RoBERTa foundation model as the text embedding extractor. A pretrained PANNs model extracts the audio embeddings. To improve the generalisation of our model, we investigate how pretraining with audio and associated noisy text collected from the online platform Freesound improves the performance of our method. Furthermore, our ablation study reveals that the proper choice of the loss function and fine-tuning the pretrained models are essential in training a competitive retrieval system.