 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWoosh: A Sound Effects Foundation Model
Apr 02, 2026The audio research community depends on open generative models as foundational tools for building novel approaches and establishing baselines. In this report, we present Woosh, Sony AI's publicly released sound effect foundation model, detailing its architecture, training process, and an evaluation against other popular open models. Being optimized for sound effects, we provide (1) a high-quality audio encoder/decoder model and (2) a text-audio alignment model for conditioning, together with (3) text-to-audio and (4) video-to-audio generative models. Distilled text-to-audio and video-to-audio models are also included in the release, allowing for low-resource operation and fast inference. Our evaluation on both public and private data shows competitive or better performance for each module when compared to existing open alternatives like StableAudio-Open and TangoFlux. Inference code and model weights are available at https://github.com/SonyResearch/Woosh. Demo samples can be found at https://sonyresearch.github.io/Woosh/.
Unsupervised Cross-Domain Speech-to-Speech Conversion with Time-Frequency Consistency
May 19, 2020
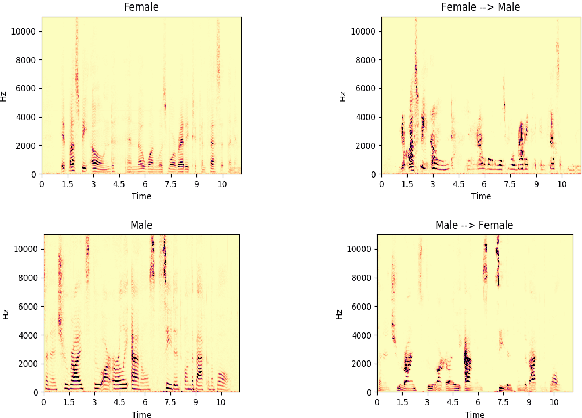
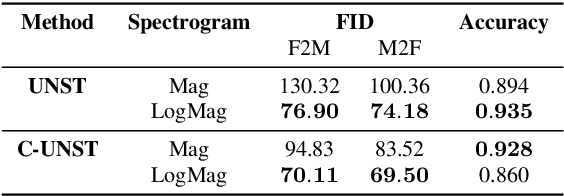
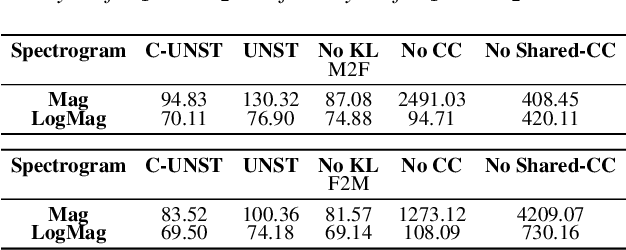
In recent years generative adversarial network (GAN) based models have been successfully applied for unsupervised speech-to-speech conversion.The rich compact harmonic view of the magnitude spectrogram is considered a suitable choice for training these models with audio data. To reconstruct the speech signal first a magnitude spectrogram is generated by the neural network, which is then utilized by methods like the Griffin-Lim algorithm to reconstruct a phase spectrogram. This procedure bears the problem that the generated magnitude spectrogram may not be consistent, which is required for finding a phase such that the full spectrogram has a natural-sounding speech waveform. In this work, we approach this problem by proposing a condition encouraging spectrogram consistency during the adversarial training procedure. We demonstrate our approach on the task of translating the voice of a male speaker to that of a female speaker, and vice versa. Our experimental results on the Librispeech corpus show that the model trained with the TF consistency provides a perceptually better quality of speech-to-speech conversion.