 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Space Refinement for Deep Generative Models
Jun 01, 2021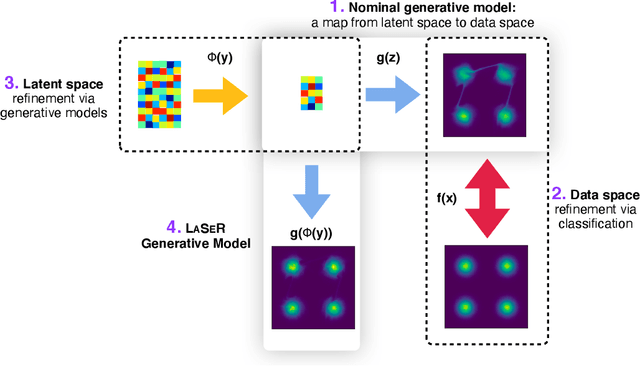


Deep generative models are becoming widely used across science and industry for a variety of purposes. A common challenge is achieving a precise implicit or explicit representation of the data probability density. Recent proposals have suggested using classifier weights to refine the learned density of deep generative models. We extend this idea to all types of generative models and show how latent space refinement via iterated generative modeling can circumvent topological obstructions and improve precision. This methodology also applies to cases were the target model is non-differentiable and has many internal latent dimensions which must be marginalized over before refinement. We demonstrate our Latent Space Refinement (LaSeR) protocol on a variety of examples, focusing on the combinations of Normalizing Flows and Generative Adversarial Networks.
Scaffolding Simulations with Deep Learning for High-dimensional Deconvolution
May 10, 2021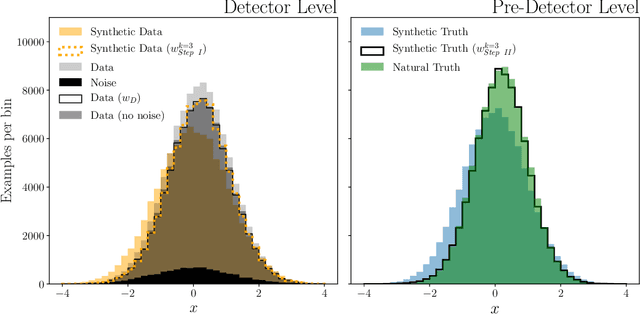
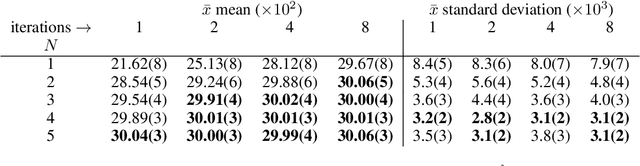
A common setting for scientific inference is the ability to sample from a high-fidelity forward model (simulation) without having an explicit probability density of the data. We propose a simulation-based maximum likelihood deconvolution approach in this setting called OmniFold. Deep learning enables this approach to be naturally unbinned and (variable-, and) high-dimensional. In contrast to model parameter estimation, the goal of deconvolution is to remove detector distortions in order to enable a variety of down-stream inference tasks. Our approach is the deep learning generalization of the common Richardson-Lucy approach that is also called Iterative Bayesian Unfolding in particle physics. We show how OmniFold can not only remove detector distortions, but it can also account for noise processes and acceptance effects.
* 6 pages, 1 figure, 1 table
Comparing Weak- and Unsupervised Methods for Resonant Anomaly Detection
Apr 05, 2021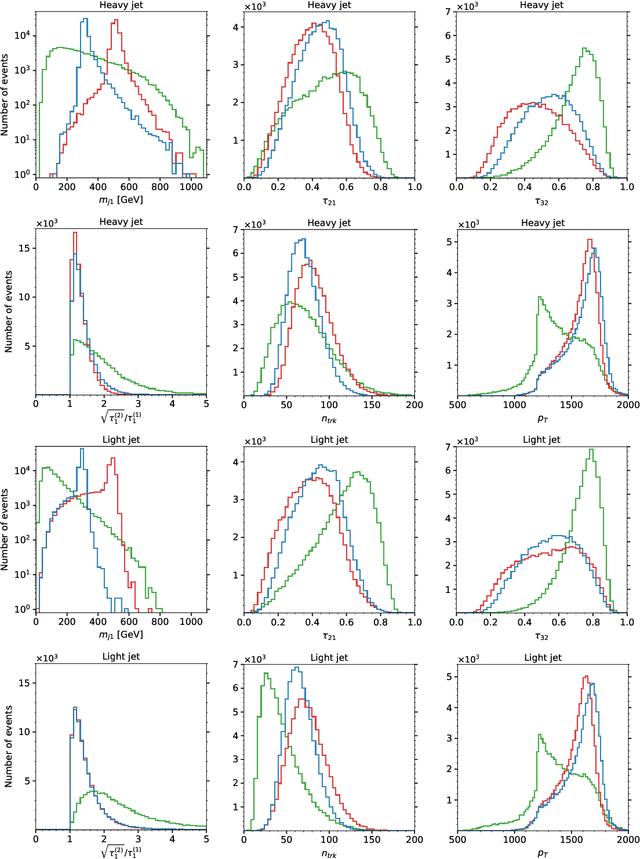
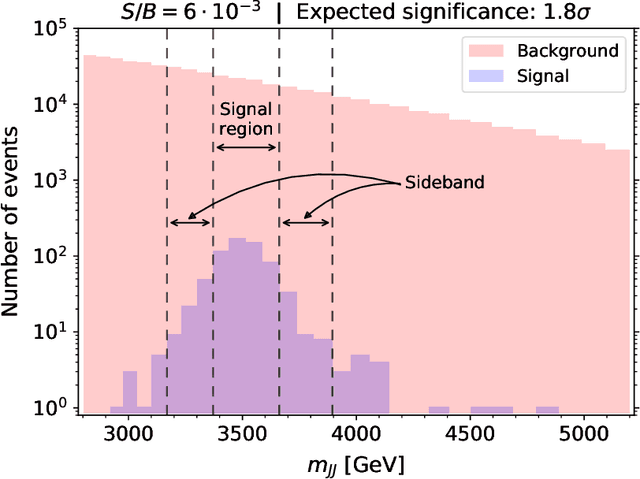
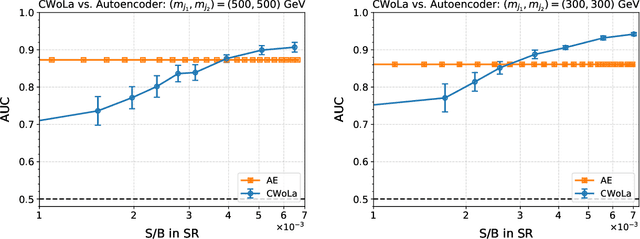
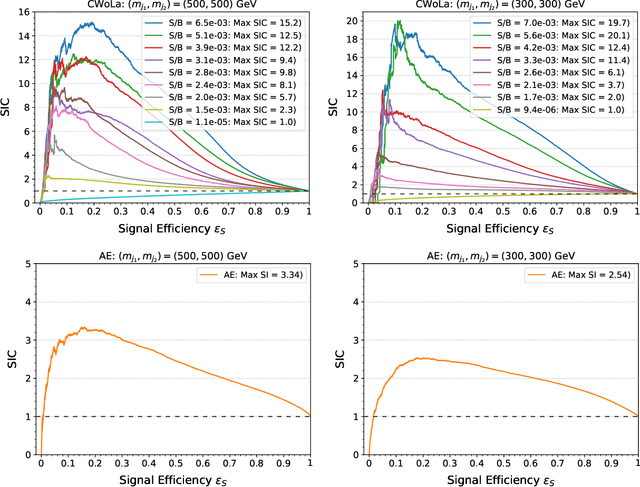
Anomaly detection techniques are growing in importance at the Large Hadron Collider (LHC), motivated by the increasing need to search for new physics in a model-agnostic way. In this work, we provide a detailed comparative study between a well-studied unsupervised method called the autoencoder (AE) and a weakly-supervised approach based on the Classification Without Labels (CWoLa) technique. We examine the ability of the two methods to identify a new physics signal at different cross sections in a fully hadronic resonance search. By construction, the AE classification performance is independent of the amount of injected signal. In contrast, the CWoLa performance improves with increasing signal abundance. When integrating these approaches with a complete background estimate, we find that the two methods have complementary sensitivity. In particular, CWoLa is effective at finding diverse and moderately rare signals while the AE can provide sensitivity to very rare signals, but only with certain topologies. We therefore demonstrate that both techniques are complementary and can be used together for anomaly detection at the LHC.
E Pluribus Unum Ex Machina: Learning from Many Collider Events at Once
Feb 07, 2021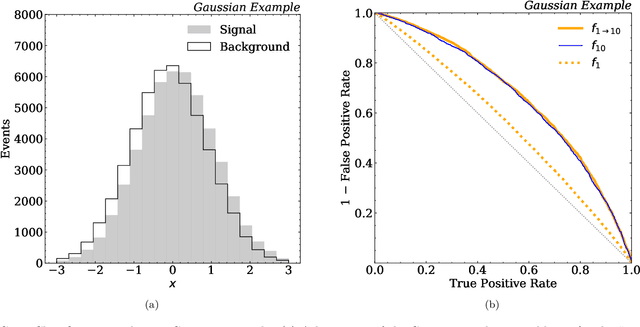
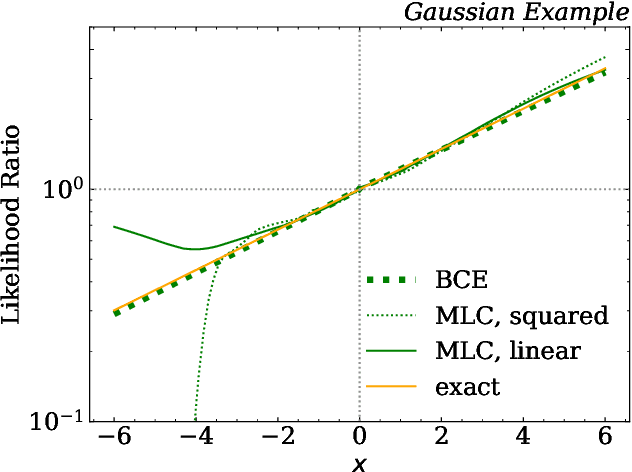
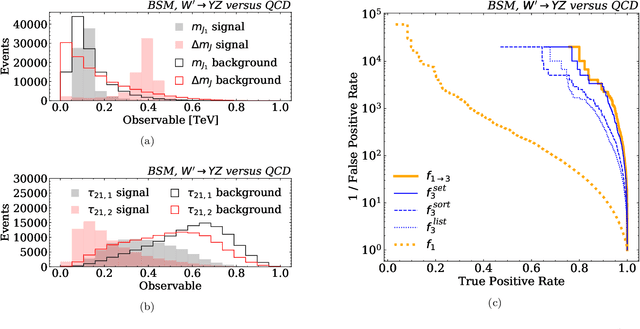
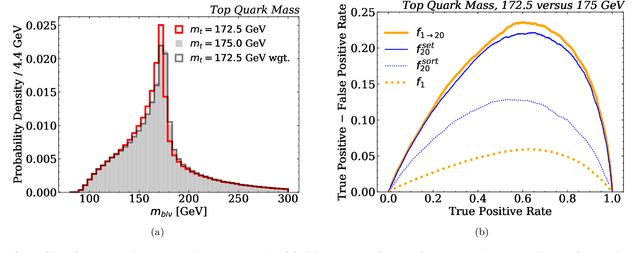
There have been a number of recent proposals to enhance the performance of machine learning strategies for collider physics by combining many distinct events into a single ensemble feature. To evaluate the efficacy of these proposals, we study the connection between single-event classifiers and multi-event classifiers under the assumption that collider events are independent and identically distributed (IID). We show how one can build optimal multi-event classifiers from single-event classifiers, and we also show how to construct multi-event classifiers such that they produce optimal single-event classifiers. This is illustrated for a Gaussian example as well as for classification tasks relevant for searches and measurements at the Large Hadron Collider. We extend our discussion to regression tasks by showing how they can be phrased in terms of parametrized classifiers. Empirically, we find that training a single-event (per-instance) classifier is more effective than training a multi-event (per-ensemble) classifier, as least for the cases we studied, and we relate this fact to properties of the loss function gradient in the two cases. While we did not identify a clear benefit from using multi-event classifiers in the collider context, we speculate on the potential value of these methods in cases involving only approximate independence, as relevant for jet substructure studies.
A Living Review of Machine Learning for Particle Physics
Feb 02, 2021


Modern machine learning techniques, including deep learning, are rapidly being applied, adapted, and developed for high energy physics. Given the fast pace of this research, we have created a living review with the goal of providing a nearly comprehensive list of citations for those developing and applying these approaches to experimental, phenomenological, or theoretical analyses. As a living document, it will be updated as often as possible to incorporate the latest developments. A list of proper (unchanging) reviews can be found within. Papers are grouped into a small set of topics to be as useful as possible. Suggestions and contributions are most welcome, and we provide instructions for participating.
Beyond 4D Tracking: Using Cluster Shapes for Track Seeding
Dec 08, 2020



Tracking is one of the most time consuming aspects of event reconstruction at the Large Hadron Collider (LHC) and its high-luminosity upgrade (HL-LHC). Innovative detector technologies extend tracking to four-dimensions by including timing in the pattern recognition and parameter estimation. However, present and future hardware already have additional information that is largely unused by existing track seeding algorithms. The shape of clusters provides an additional dimension for track seeding that can significantly reduce the combinatorial challenge of track finding. We use neural networks to show that cluster shapes can reduce significantly the rate of fake combinatorical backgrounds while preserving a high efficiency. We demonstrate this using the information in cluster singlets, doublets and triplets. Numerical results are presented with simulations from the TrackML challenge.
Parameter Estimation using Neural Networks in the Presence of Detector Effects
Oct 22, 2020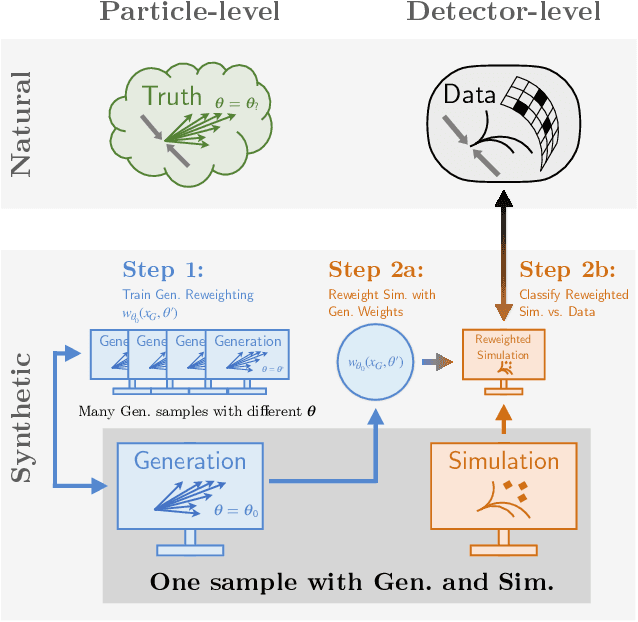
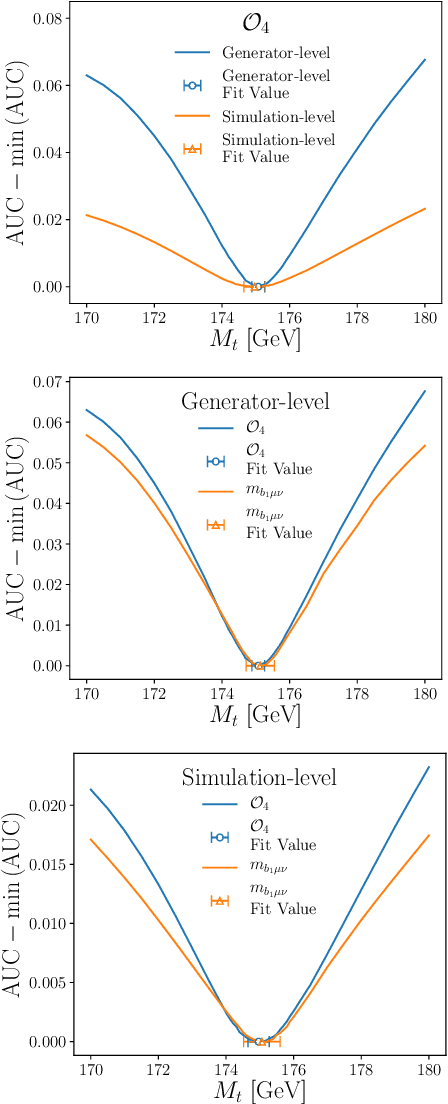
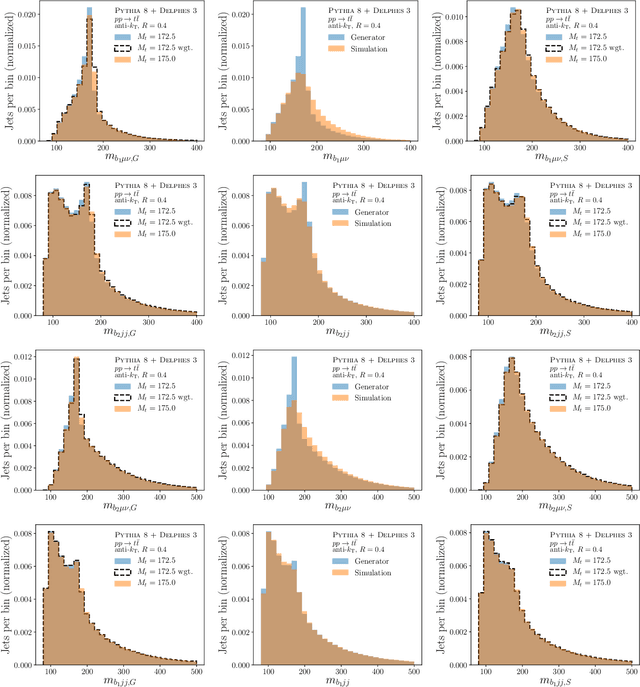
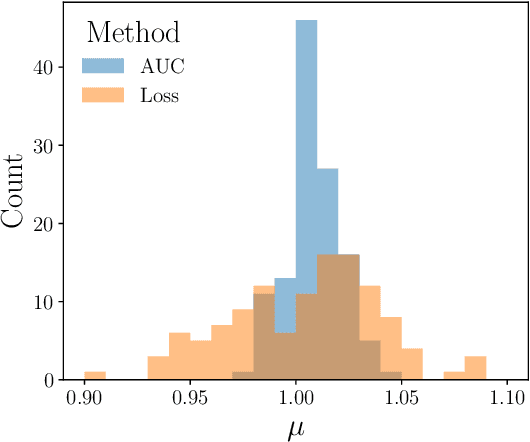
Histogram-based template fits are the main technique used for estimating parameters of high energy physics Monte Carlo generators. Parameterized neural network reweighting can be used to extend this fitting procedure to many dimensions and does not require binning. If the fit is to be performed using reconstructed data, then expensive detector simulations must be used for training the neural networks. We introduce a new two-level fitting approach that only requires one dataset with detector simulation and then a set of additional generation-level datasets without detector effects included. This Simulation-level fit based on Reweighting Generator-level events with Neural networks (SRGN) is demonstrated using simulated datasets for a variety of examples including a simple Gaussian random variable, parton shower tuning, and the top quark mass extraction.
GANplifying Event Samples
Sep 16, 2020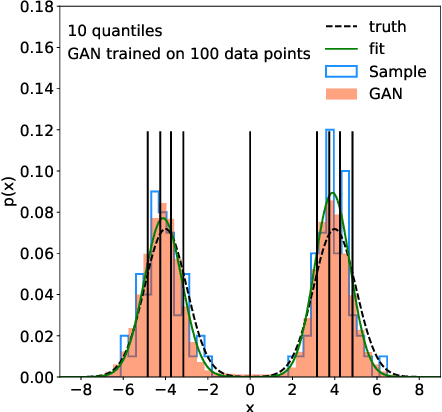
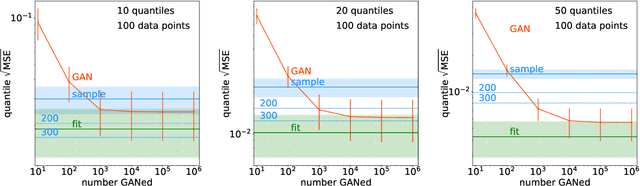
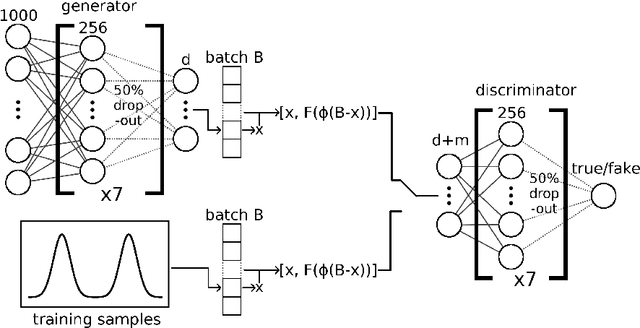
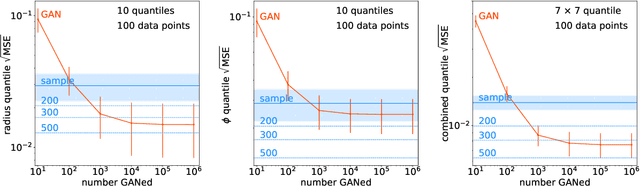
A critical question concerning generative networks applied to event generation in particle physics is if the generated events add statistical precision beyond the training sample. We show for a simple example with increasing dimensionality how generative networks indeed amplify the training statistics. We quantify their impact through an amplification factor or equivalent numbers of sampled events.
Simulation-Assisted Decorrelation for Resonant Anomaly Detection
Sep 04, 2020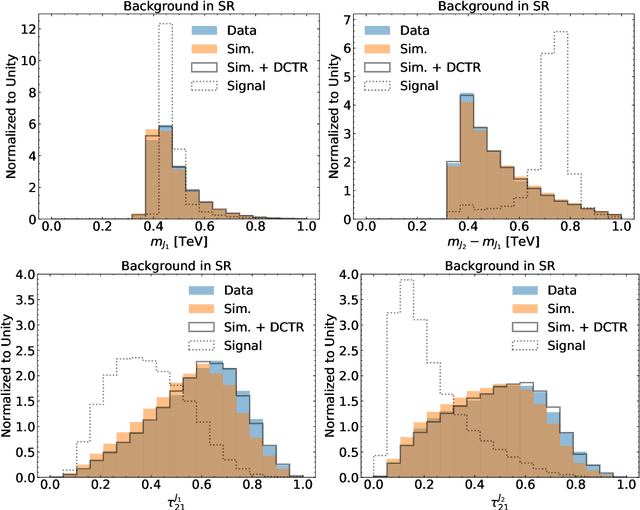
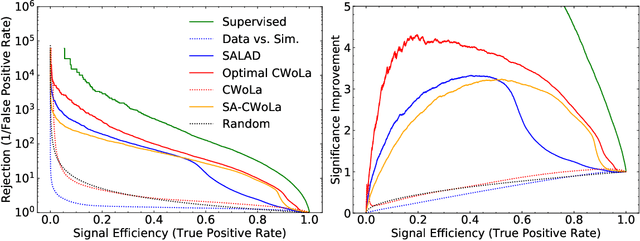
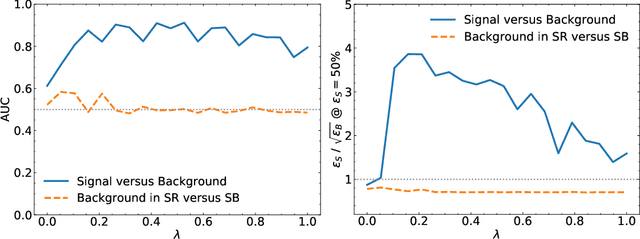
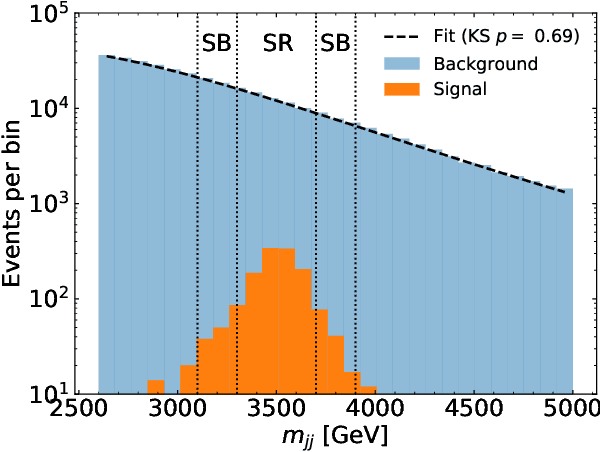
A growing number of weak- and unsupervised machine learning approaches to anomaly detection are being proposed to significantly extend the search program at the Large Hadron Collider and elsewhere. One of the prototypical examples for these methods is the search for resonant new physics, where a bump hunt can be performed in an invariant mass spectrum. A significant challenge to methods that rely entirely on data is that they are susceptible to sculpting artificial bumps from the dependence of the machine learning classifier on the invariant mass. We explore two solutions to this challenge by minimally incorporating simulation into the learning. In particular, we study the robustness of Simulation Assisted Likelihood-free Anomaly Detection (SALAD) to correlations between the classifier and the invariant mass. Next, we propose a new approach that only uses the simulation for decorrelation but the Classification without Labels (CWoLa) approach for achieving signal sensitivity. Both methods are compared using a full background fit analysis on simulated data from the LHC Olympics and are robust to correlations in the data.
DCTRGAN: Improving the Precision of Generative Models with Reweighting
Sep 03, 2020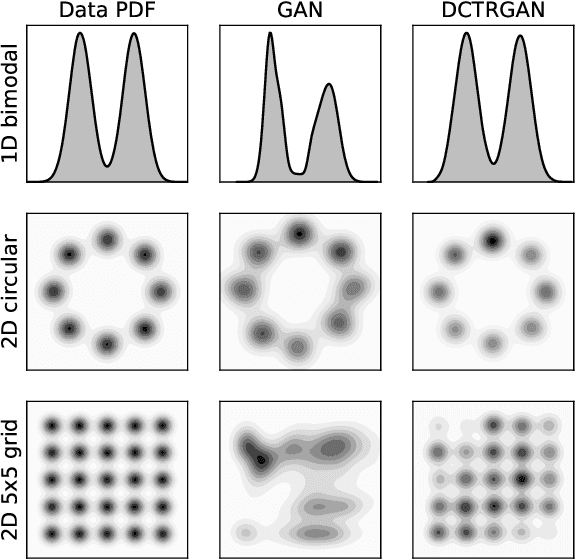
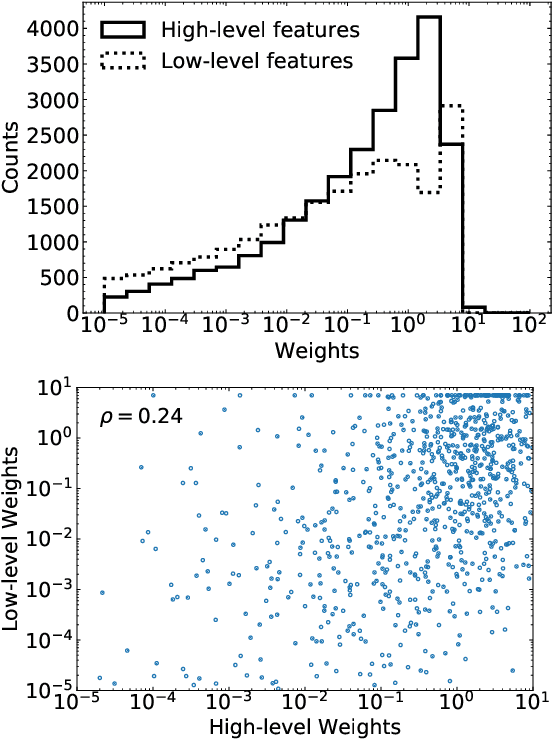
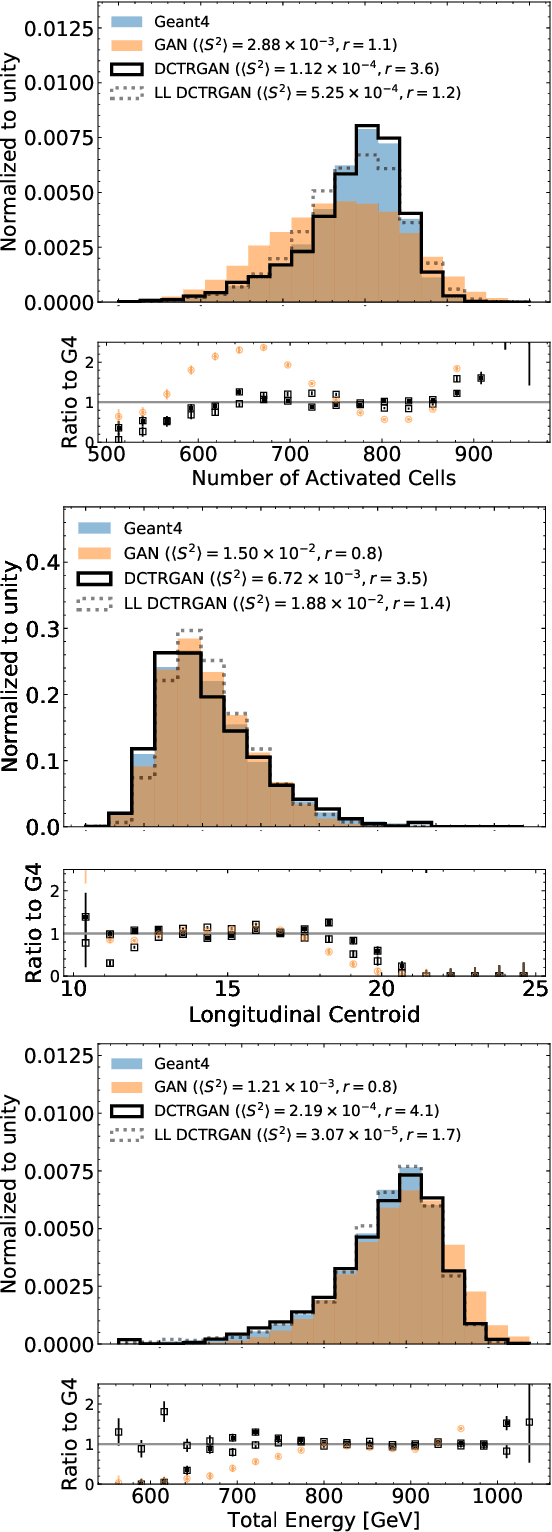
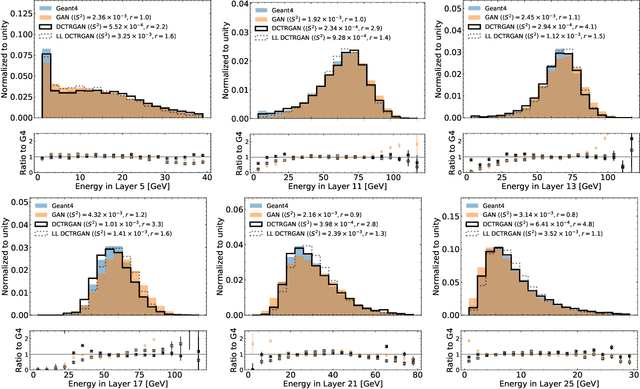
Significant advances in deep learning have led to more widely used and precise neural network-based generative models such as Generative Adversarial Networks (GANs). We introduce a post-hoc correction to deep generative models to further improve their fidelity, based on the Deep neural networks using the Classification for Tuning and Reweighting (DCTR) protocol. The correction takes the form of a reweighting function that can be applied to generated examples when making predictions from the simulation. We illustrate this approach using GANs trained on standard multimodal probability densities as well as calorimeter simulations from high energy physics. We show that the weighted GAN examples significantly improve the accuracy of the generated samples without a large loss in statistical power. This approach could be applied to any generative model and is a promising refinement method for high energy physics applications and beyond.