 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Uneven Impact of Post-Training Quantization in Machine Translation
Aug 28, 2025Quantization is essential for deploying large language models (LLMs) on resource-constrained hardware, but its implications for multilingual tasks remain underexplored. We conduct the first large-scale evaluation of post-training quantization (PTQ) on machine translation across 55 languages using five LLMs ranging from 1.7B to 70B parameters. Our analysis reveals that while 4-bit quantization often preserves translation quality for high-resource languages and large models, significant degradation occurs for low-resource and typologically diverse languages, particularly in 2-bit settings. We compare four quantization techniques (AWQ, BitsAndBytes, GGUF, and AutoRound), showing that algorithm choice and model size jointly determine robustness. GGUF variants provide the most consistent performance, even at 2-bit precision. Additionally, we quantify the interactions between quantization, decoding hyperparameters, and calibration languages, finding that language-matched calibration offers benefits primarily in low-bit scenarios. Our findings offer actionable insights for deploying multilingual LLMs for machine translation under quantization constraints, especially in low-resource settings.
Preliminary WMT24 Ranking of General MT Systems and LLMs
Jul 29, 2024



This is the preliminary ranking of WMT24 General MT systems based on automatic metrics. The official ranking will be a human evaluation, which is superior to the automatic ranking and supersedes it. The purpose of this report is not to interpret any findings but only provide preliminary results to the participants of the General MT task that may be useful during the writing of the system submission.
An Automatic Evaluation of the WMT22 General Machine Translation Task
Sep 28, 2022
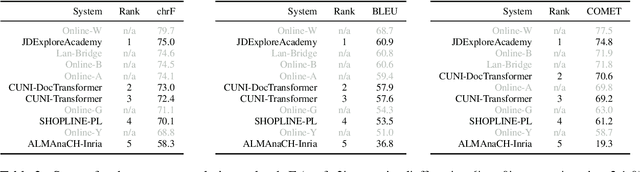
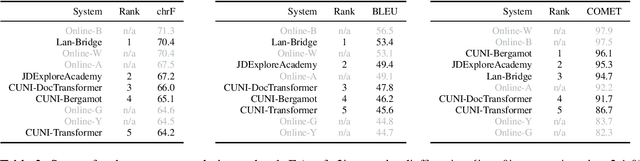
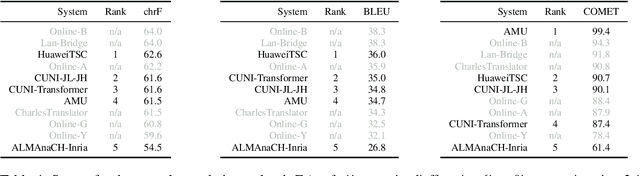
This report presents an automatic evaluation of the general machine translation task of the Seventh Conference on Machine Translation (WMT22). It evaluates a total of 185 systems for 21 translation directions including high-resource to low-resource language pairs and from closely related to distant languages. This large-scale automatic evaluation highlights some of the current limits of state-of-the-art machine translation systems. It also shows how automatic metrics, namely chrF, BLEU, and COMET, can complement themselves to mitigate their own limits in terms of interpretability and accuracy.
Scientific Credibility of Machine Translation Research: A Meta-Evaluation of 769 Papers
Jun 29, 2021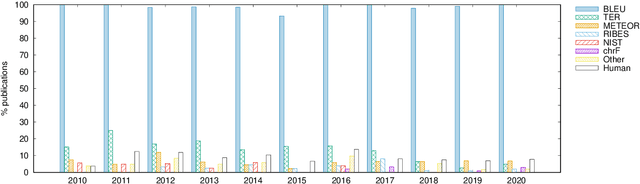

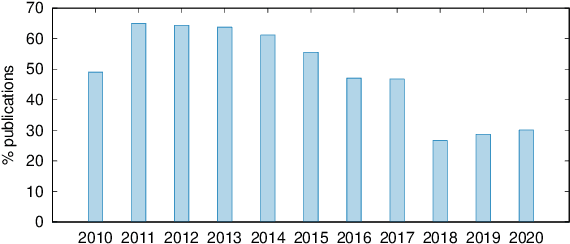
This paper presents the first large-scale meta-evaluation of machine translation (MT). We annotated MT evaluations conducted in 769 research papers published from 2010 to 2020. Our study shows that practices for automatic MT evaluation have dramatically changed during the past decade and follow concerning trends. An increasing number of MT evaluations exclusively rely on differences between BLEU scores to draw conclusions, without performing any kind of statistical significance testing nor human evaluation, while at least 108 metrics claiming to be better than BLEU have been proposed. MT evaluations in recent papers tend to copy and compare automatic metric scores from previous work to claim the superiority of a method or an algorithm without confirming neither exactly the same training, validating, and testing data have been used nor the metric scores are comparable. Furthermore, tools for reporting standardized metric scores are still far from being widely adopted by the MT community. After showing how the accumulation of these pitfalls leads to dubious evaluation, we propose a guideline to encourage better automatic MT evaluation along with a simple meta-evaluation scoring method to assess its credibility.
Synthesizing Monolingual Data for Neural Machine Translation
Jan 29, 2021
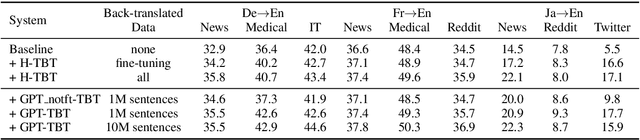
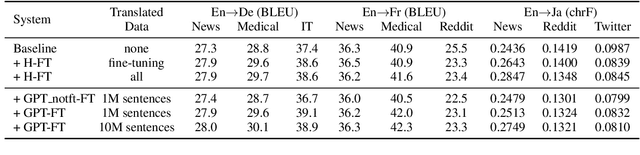
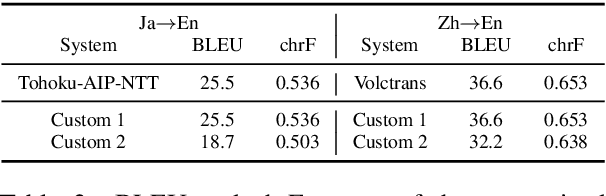
In neural machine translation (NMT), monolingual data in the target language are usually exploited through a method so-called "back-translation" to synthesize additional training parallel data. The synthetic data have been shown helpful to train better NMT, especially for low-resource language pairs and domains. Nonetheless, large monolingual data in the target domains or languages are not always available to generate large synthetic parallel data. In this work, we propose a new method to generate large synthetic parallel data leveraging very small monolingual data in a specific domain. We fine-tune a pre-trained GPT-2 model on such small in-domain monolingual data and use the resulting model to generate a large amount of synthetic in-domain monolingual data. Then, we perform back-translation, or forward translation, to generate synthetic in-domain parallel data. Our preliminary experiments on three language pairs and five domains show the effectiveness of our method to generate fully synthetic but useful in-domain parallel data for improving NMT in all configurations. We also show promising results in extreme adaptation for personalized NMT.
Unsupervised Neural Machine Translation Initialized by Unsupervised Statistical Machine Translation
Oct 30, 2018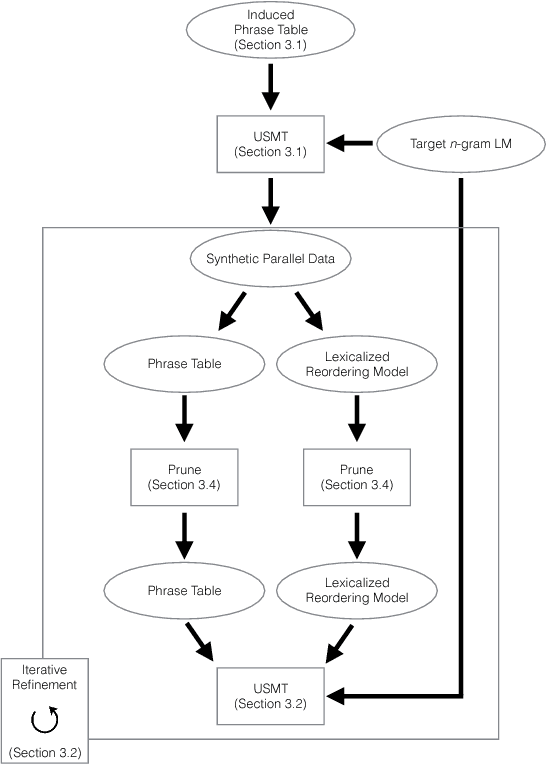
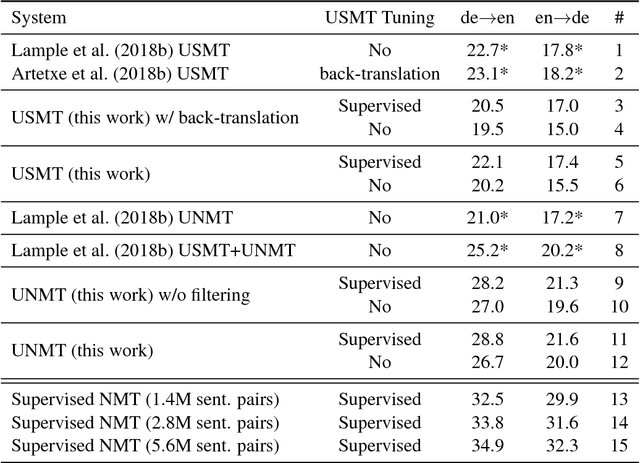
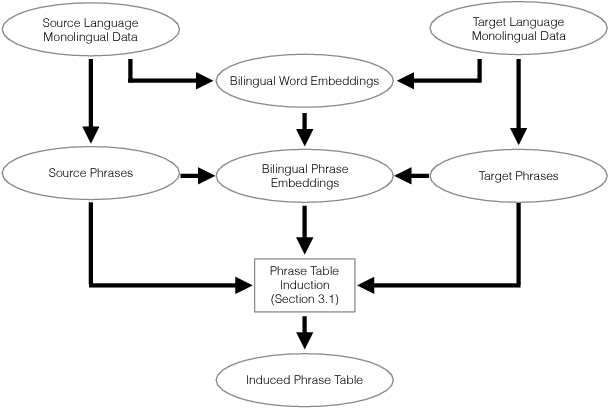
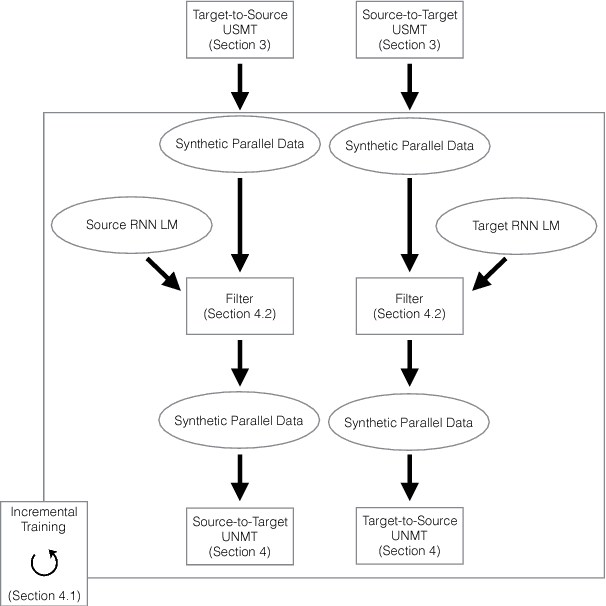
Recent work achieved remarkable results in training neural machine translation (NMT) systems in a fully unsupervised way, with new and dedicated architectures that rely on monolingual corpora only. In this work, we propose to define unsupervised NMT (UNMT) as NMT trained with the supervision of synthetic bilingual data. Our approach straightforwardly enables the use of state-of-the-art architectures proposed for supervised NMT by replacing human-made bilingual data with synthetic bilingual data for training. We propose to initialize the training of UNMT with synthetic bilingual data generated by unsupervised statistical machine translation (USMT). The UNMT system is then incrementally improved using back-translation. Our preliminary experiments show that our approach achieves a new state-of-the-art for unsupervised machine translation on the WMT16 German--English news translation task, for both translation directions.
NICT's Corpus Filtering Systems for the WMT18 Parallel Corpus Filtering Task
Oct 12, 2018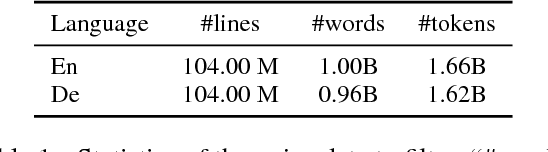

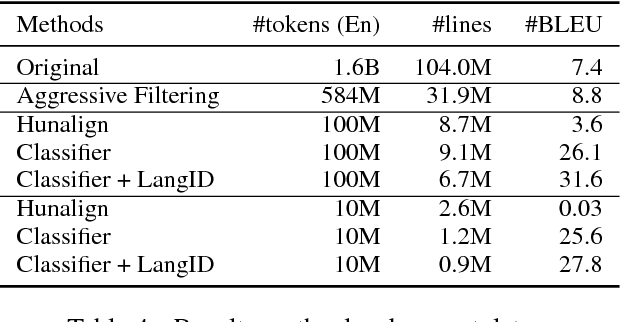
This paper presents the NICT's participation in the WMT18 shared parallel corpus filtering task. The organizers provided 1 billion words German-English corpus crawled from the web as part of the Paracrawl project. This corpus is too noisy to build an acceptable neural machine translation (NMT) system. Using the clean data of the WMT18 shared news translation task, we designed several features and trained a classifier to score each sentence pairs in the noisy data. Finally, we sampled 100 million and 10 million words and built corresponding NMT systems. Empirical results show that our NMT systems trained on sampled data achieve promising performance.
NICT's Neural and Statistical Machine Translation Systems for the WMT18 News Translation Task
Oct 12, 2018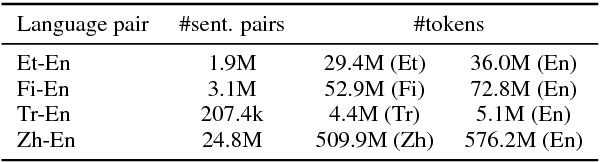
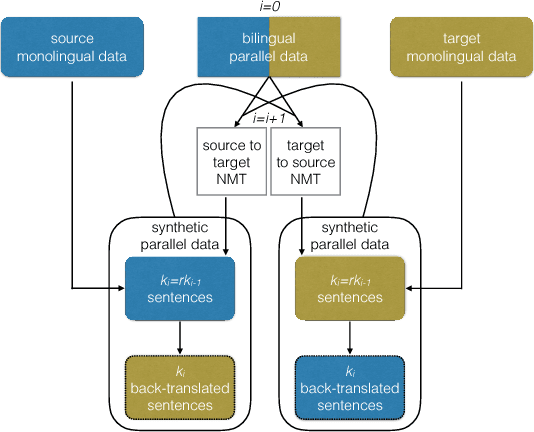
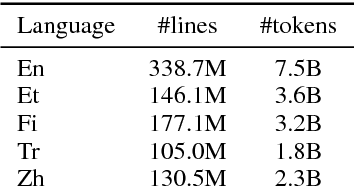

This paper presents the NICT's participation to the WMT18 shared news translation task. We participated in the eight translation directions of four language pairs: Estonian-English, Finnish-English, Turkish-English and Chinese-English. For each translation direction, we prepared state-of-the-art statistical (SMT) and neural (NMT) machine translation systems. Our NMT systems were trained with the transformer architecture using the provided parallel data enlarged with a large quantity of back-translated monolingual data that we generated with a new incremental training framework. Our primary submissions to the task are the result of a simple combination of our SMT and NMT systems. Our systems are ranked first for the Estonian-English and Finnish-English language pairs (constraint) according to BLEU-cased.