 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Similarity Bootstrapping for Self-Distillation
Mar 23, 2023



Most self-supervised methods for representation learning leverage a cross-view consistency objective i.e. they maximize the representation similarity of a given image's augmented views. Recent work NNCLR goes beyond the cross-view paradigm and uses positive pairs from different images obtained via nearest neighbor bootstrapping in a contrastive setting. We empirically show that as opposed to the contrastive learning setting which relies on negative samples, incorporating nearest neighbor bootstrapping in a self-distillation scheme can lead to a performance drop or even collapse. We scrutinize the reason for this unexpected behavior and provide a solution. We propose to adaptively bootstrap neighbors based on the estimated quality of the latent space. We report consistent improvements compared to the naive bootstrapping approach and the original baselines. Our approach leads to performance improvements for various self-distillation method/backbone combinations and standard downstream tasks. Our code will be released upon acceptance.
TeSLA: Test-Time Self-Learning With Automatic Adversarial Augmentation
Mar 17, 2023Most recent test-time adaptation methods focus on only classification tasks, use specialized network architectures, destroy model calibration or rely on lightweight information from the source domain. To tackle these issues, this paper proposes a novel Test-time Self-Learning method with automatic Adversarial augmentation dubbed TeSLA for adapting a pre-trained source model to the unlabeled streaming test data. In contrast to conventional self-learning methods based on cross-entropy, we introduce a new test-time loss function through an implicitly tight connection with the mutual information and online knowledge distillation. Furthermore, we propose a learnable efficient adversarial augmentation module that further enhances online knowledge distillation by simulating high entropy augmented images. Our method achieves state-of-the-art classification and segmentation results on several benchmarks and types of domain shifts, particularly on challenging measurement shifts of medical images. TeSLA also benefits from several desirable properties compared to competing methods in terms of calibration, uncertainty metrics, insensitivity to model architectures, and source training strategies, all supported by extensive ablations. Our code and models are available on GitHub.
Self-Supervised Learning-Based Cervical Cytology Diagnostics in Low-Data Regime and Low-Resource Setting
Feb 10, 2023



Screening Papanicolaou test samples effectively reduces cervical cancer-related mortality, but the lack of trained cytopathologists prevents its widespread adoption in low-resource settings. Developing AI algorithms, e.g., deep learning to analyze the digitized cytology images suited to resource-constrained countries is appealing. Albeit successful, it comes at the price of collecting large annotated training datasets, which is both costly and time-consuming. Our study shows that the large number of unlabeled images that can be sampled from digitized cytology slides make for a ripe ground where self-supervised learning methods can thrive and even outperform off-the-shelf deep learning models on various downstream tasks. Along the same line, we report improved performance and data efficiency using modern augmentation strategies.
Weakly Supervised Joint Whole-Slide Segmentation and Classification in Prostate Cancer
Jan 07, 2023The segmentation and automatic identification of histological regions of diagnostic interest offer a valuable aid to pathologists. However, segmentation methods are hampered by the difficulty of obtaining pixel-level annotations, which are tedious and expensive to obtain for Whole-Slide images (WSI). To remedy this, weakly supervised methods have been developed to exploit the annotations directly available at the image level. However, to our knowledge, none of these techniques is adapted to deal with WSIs. In this paper, we propose WholeSIGHT, a weakly-supervised method, to simultaneously segment and classify WSIs of arbitrary shapes and sizes. Formally, WholeSIGHT first constructs a tissue-graph representation of the WSI, where the nodes and edges depict tissue regions and their interactions, respectively. During training, a graph classification head classifies the WSI and produces node-level pseudo labels via post-hoc feature attribution. These pseudo labels are then used to train a node classification head for WSI segmentation. During testing, both heads simultaneously render class prediction and segmentation for an input WSI. We evaluated WholeSIGHT on three public prostate cancer WSI datasets. Our method achieved state-of-the-art weakly-supervised segmentation performance on all datasets while resulting in better or comparable classification with respect to state-of-the-art weakly-supervised WSI classification methods. Additionally, we quantify the generalization capability of our method in terms of segmentation and classification performance, uncertainty estimation, and model calibration.
ScoreNet: Learning Non-Uniform Attention and Augmentation for Transformer-Based Histopathological Image Classification
Mar 14, 2022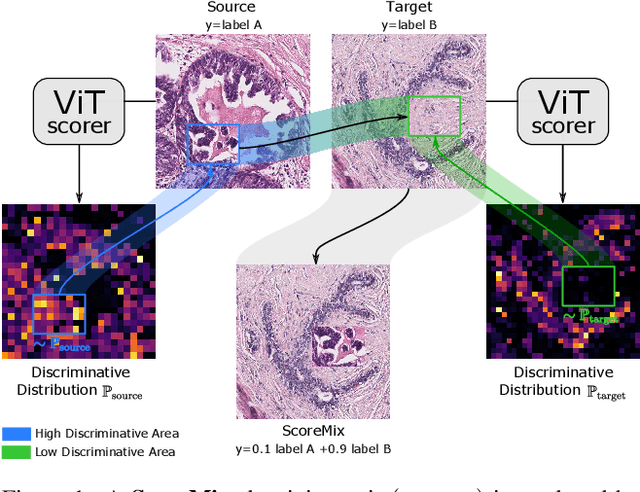
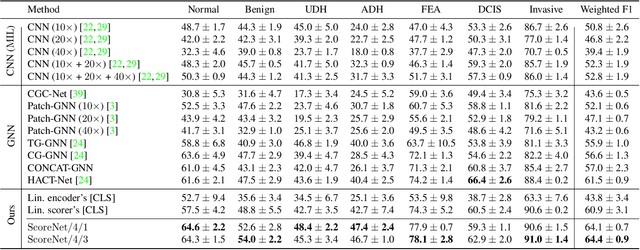
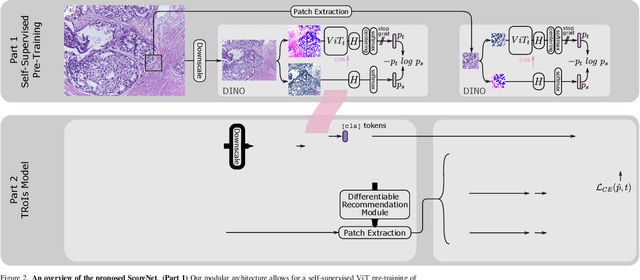
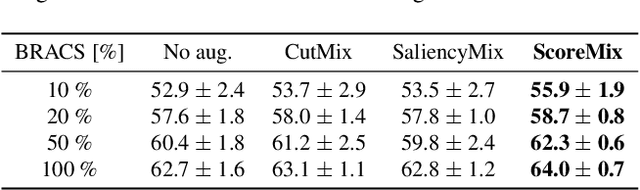
Progress in digital pathology is hindered by high-resolution images and the prohibitive cost of exhaustive localized annotations. The commonly used paradigm to categorize pathology images is patch-based processing, which often incorporates multiple instance learning (MIL) to aggregate local patch-level representations yielding image-level prediction. Nonetheless, diagnostically relevant regions may only take a small fraction of the whole tissue, and current MIL-based approaches often process images uniformly, discarding the inter-patches interactions. To alleviate these issues, we propose ScoreNet, a new efficient transformer that exploits a differentiable recommendation stage to extract discriminative image regions and dedicate computational resources accordingly. The proposed transformer leverages the local and global attention of a few dynamically recommended high-resolution regions at an efficient computational cost. We further introduce a novel Mixup-based data-augmentation, namely ScoreMix, by leveraging the image's semantic distribution to guide the data mixing and produce coherent sample-label pairs. ScoreMix is embarrassingly simple and mitigates the pitfalls of previous augmentations, which assume a uniform semantic distribution and risk mislabeling the samples. Thorough experiments and ablation studies on three breast cancer histology datasets of Haematoxylin & Eosin (H&E) have validated the superiority of our approach over prior arts, including transformer-based models on tumour regions-of-interest (TRoIs) classification. ScoreNet equipped with proposed ScoreMix augmentation demonstrates better generalization capabilities and achieves new state-of-the-art (SOTA) results with only 50% of the data compared to other Mixup augmentation variants. Finally, ScoreNet yields high efficacy and outperforms SOTA efficient transformers, namely TransPath and SwinTransformer.
Self-Supervised Generative Style Transfer for One-Shot Medical Image Segmentation
Oct 05, 2021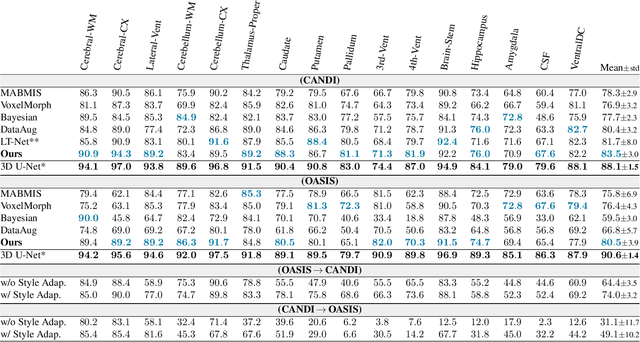
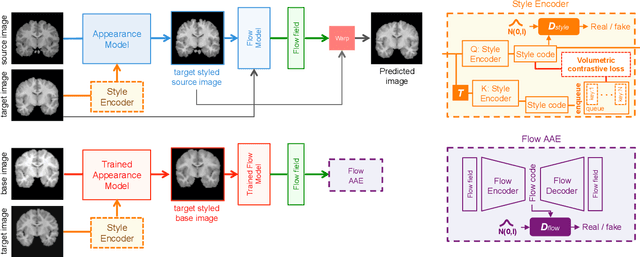
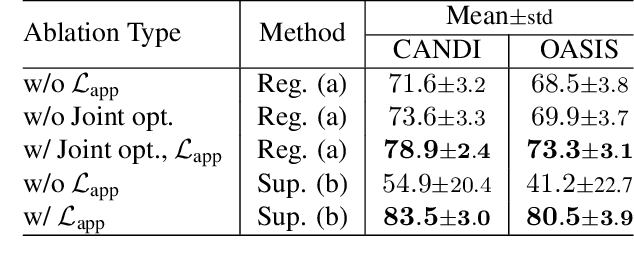
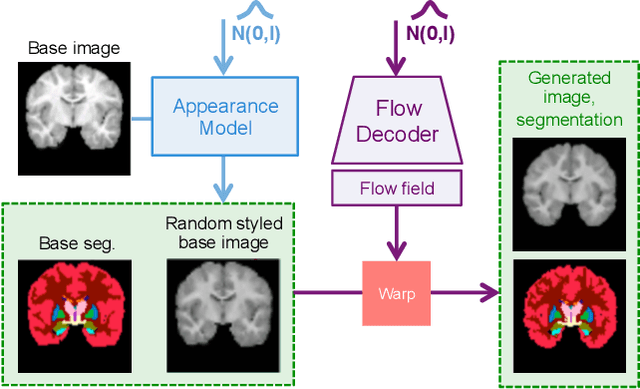
In medical image segmentation, supervised deep networks' success comes at the cost of requiring abundant labeled data. While asking domain experts to annotate only one or a few of the cohort's images is feasible, annotating all available images is impractical. This issue is further exacerbated when pre-trained deep networks are exposed to a new image dataset from an unfamiliar distribution. Using available open-source data for ad-hoc transfer learning or hand-tuned techniques for data augmentation only provides suboptimal solutions. Motivated by atlas-based segmentation, we propose a novel volumetric self-supervised learning for data augmentation capable of synthesizing volumetric image-segmentation pairs via learning transformations from a single labeled atlas to the unlabeled data. Our work's central tenet benefits from a combined view of one-shot generative learning and the proposed self-supervised training strategy that cluster unlabeled volumetric images with similar styles together. Unlike previous methods, our method does not require input volumes at inference time to synthesize new images. Instead, it can generate diversified volumetric image-segmentation pairs from a prior distribution given a single or multi-site dataset. Augmented data generated by our method used to train the segmentation network provide significant improvements over state-of-the-art deep one-shot learning methods on the task of brain MRI segmentation. Ablation studies further exemplified that the proposed appearance model and joint training are crucial to synthesize realistic examples compared to existing medical registration methods. The code, data, and models are available at https://github.com/devavratTomar/SST.
Self-Rule to Adapt: Generalized Multi-source Feature Learning Using Unsupervised Domain Adaptation for Colorectal Cancer Tissue Detection
Aug 20, 2021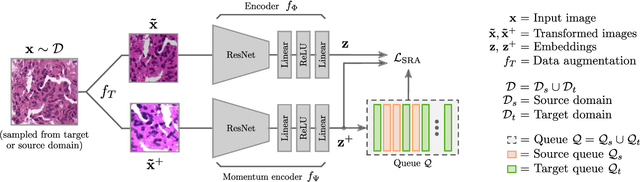
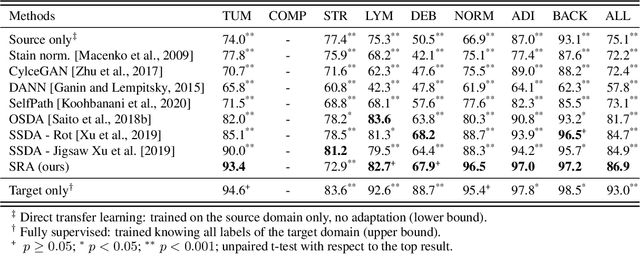
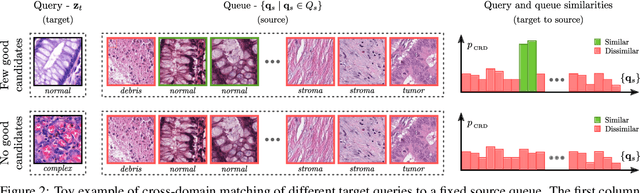
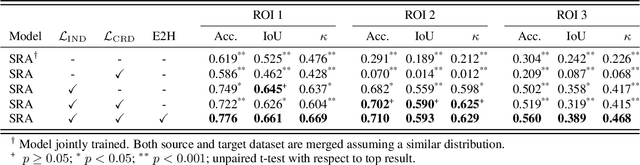
Supervised learning is constrained by the availability of labeled data, which are especially expensive to acquire in the field of digital pathology. Making use of open-source data for pre-training or using domain adaptation can be a way to overcome this issue. However, pre-trained networks often fail to generalize to new test domains that are not distributed identically due to variations in tissue stainings, types, and textures. Additionally, current domain adaptation methods mainly rely on fully-labeled source datasets. In this work, we propose SRA, which takes advantage of self-supervised learning to perform domain adaptation and removes the necessity of a fully-labeled source dataset. SRA can effectively transfer the discriminative knowledge obtained from a few labeled source domain's data to a new target domain without requiring additional tissue annotations. Our method harnesses both domains' structures by capturing visual similarity with intra-domain and cross-domain self-supervision. Moreover, we present a generalized formulation of our approach that allows the architecture to learn from multi-source domains. We show that our proposed method outperforms baselines for domain adaptation of colorectal tissue type classification and further validate our approach on our in-house clinical cohort. The code and models are available open-source: https://github.com/christianabbet/SRA.
Test-Time Adaptation for Super-Resolution: You Only Need to Overfit on a Few More Images
Apr 06, 2021
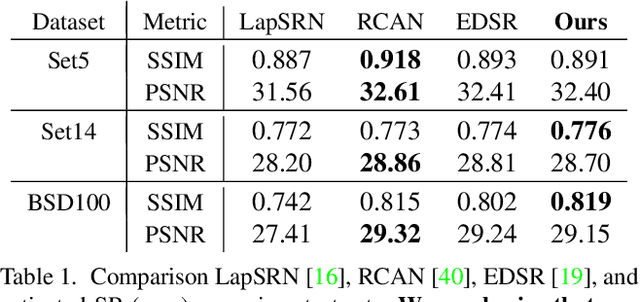
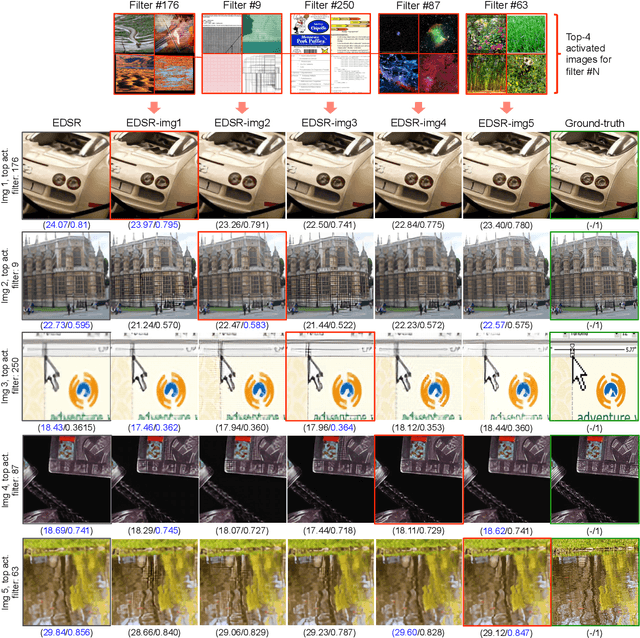
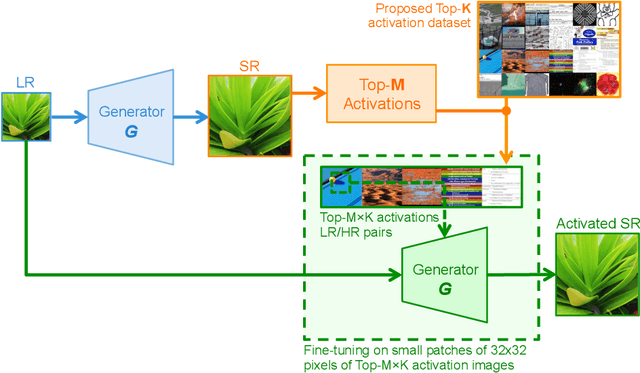
Existing reference (RF)-based super-resolution (SR) models try to improve perceptual quality in SR under the assumption of the availability of high-resolution RF images paired with low-resolution (LR) inputs at testing. As the RF images should be similar in terms of content, colors, contrast, etc. to the test image, this hinders the applicability in a real scenario. Other approaches to increase the perceptual quality of images, including perceptual loss and adversarial losses, tend to dramatically decrease fidelity to the ground-truth through significant decreases in PSNR/SSIM. Addressing both issues, we propose a simple yet universal approach to improve the perceptual quality of the HR prediction from a pre-trained SR network on a given LR input by further fine-tuning the SR network on a subset of images from the training dataset with similar patterns of activation as the initial HR prediction, with respect to the filters of a feature extractor. In particular, we show the effects of fine-tuning on these images in terms of the perceptual quality and PSNR/SSIM values. Contrary to perceptually driven approaches, we demonstrate that the fine-tuned network produces a HR prediction with both greater perceptual quality and minimal changes to the PSNR/SSIM with respect to the initial HR prediction. Further, we present novel numerical experiments concerning the filters of SR networks, where we show through filter correlation, that the filters of the fine-tuned network from our method are closer to "ideal" filters, than those of the baseline network or a network fine-tuned on random images.
Self-Attentive Spatial Adaptive Normalization for Cross-Modality Domain Adaptation
Mar 05, 2021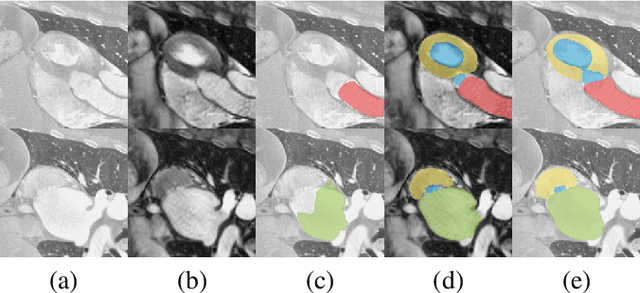
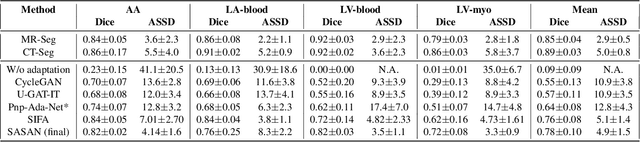
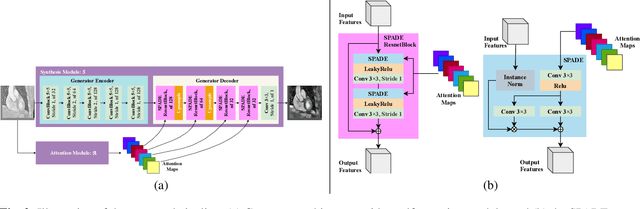
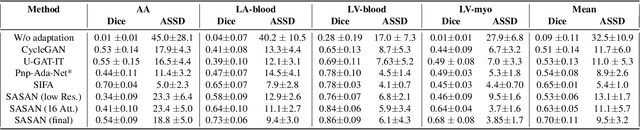
Despite the successes of deep neural networks on many challenging vision tasks, they often fail to generalize to new test domains that are not distributed identically to the training data. The domain adaptation becomes more challenging for cross-modality medical data with a notable domain shift. Given that specific annotated imaging modalities may not be accessible nor complete. Our proposed solution is based on the cross-modality synthesis of medical images to reduce the costly annotation burden by radiologists and bridge the domain gap in radiological images. We present a novel approach for image-to-image translation in medical images, capable of supervised or unsupervised (unpaired image data) setups. Built upon adversarial training, we propose a learnable self-attentive spatial normalization of the deep convolutional generator network's intermediate activations. Unlike previous attention-based image-to-image translation approaches, which are either domain-specific or require distortion of the source domain's structures, we unearth the importance of the auxiliary semantic information to handle the geometric changes and preserve anatomical structures during image translation. We achieve superior results for cross-modality segmentation between unpaired MRI and CT data for multi-modality whole heart and multi-modal brain tumor MRI (T1/T2) datasets compared to the state-of-the-art methods. We also observe encouraging results in cross-modality conversion for paired MRI and CT images on a brain dataset. Furthermore, a detailed analysis of the cross-modality image translation, thorough ablation studies confirm our proposed method's efficacy.
Learning Whole-Slide Segmentation from Inexact and Incomplete Labels using Tissue Graphs
Mar 04, 2021Segmenting histology images into diagnostically relevant regions is imperative to support timely and reliable decisions by pathologists. To this end, computer-aided techniques have been proposed to delineate relevant regions in scanned histology slides. However, the techniques necessitate task-specific large datasets of annotated pixels, which is tedious, time-consuming, expensive, and infeasible to acquire for many histology tasks. Thus, weakly-supervised semantic segmentation techniques are proposed to utilize weak supervision that is cheaper and quicker to acquire. In this paper, we propose SegGini, a weakly supervised segmentation method using graphs, that can utilize weak multiplex annotations, i.e. inexact and incomplete annotations, to segment arbitrary and large images, scaling from tissue microarray (TMA) to whole slide image (WSI). Formally, SegGini constructs a tissue-graph representation for an input histology image, where the graph nodes depict tissue regions. Then, it performs weakly-supervised segmentation via node classification by using inexact image-level labels, incomplete scribbles, or both. We evaluated SegGini on two public prostate cancer datasets containing TMAs and WSIs. Our method achieved state-of-the-art segmentation performance on both datasets for various annotation settings while being comparable to a pathologist baseline.